1.xml的解析方式(技术):dom 和 sax
>>dom方式解析:
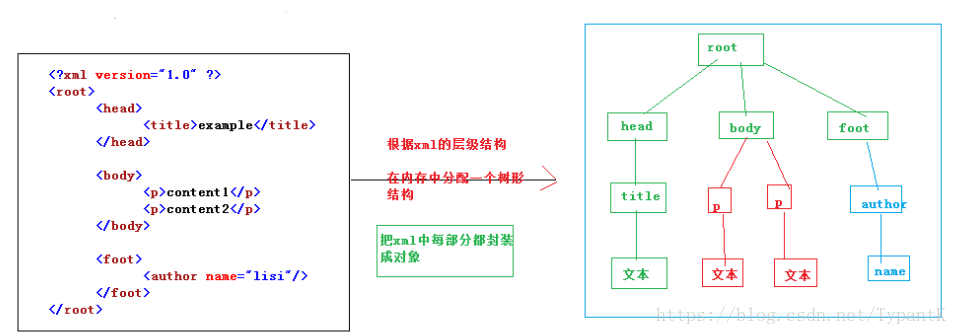
根据xml的层级结构在内存中分配一个树形结构,把xml的标签、属性和文本都封装成对象
**优点:实现增删改操作很方便
**缺点:如果文件过大会造成内存溢出
**解析过程:
>>sax方式解析:(simple api xml)
采用事件驱动,边读边解析
--从上到下,一行一行的解析,解析到某个对象就返回对象的名称
在javax.xml.parsers包里面有两个关于SAX的类
** SAXParser
此类的实例可以从 SAXParserFactory.newSAXParser() 方法获得
- parse(File f, DefaultHandler dh)
** 两个参数:(XML的路径,事件处理器(事件驱动))
** SAXParserFactory
实例 newInstance() 方法得到
**优点:如果文件过大不会造成内存溢出,查询操作容易实现
**缺点:不能实现增删改操作
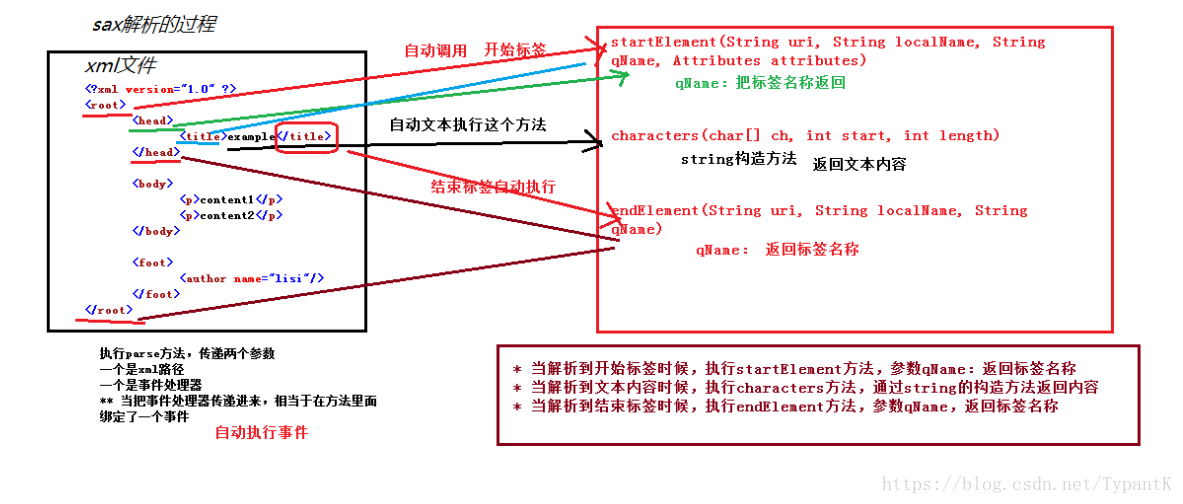
**解析过程:
先执行parse方法,将指定文件内容解析为XML,然后就一行一行的解析,
-当解析到开始标签时候,自动执行startElement方法
-当解析到文本时候,自动执行characters方法
-当解析到结束标签时候,自动执行endElement方法
1.针对dom和sax解析方式的解析器jaxp/dom4j/jdom
>>jaxp解析器(dom和sax区分不同的类)
在javase中(包javax.xml.parsers)
**解析步骤:
先获取解析器工厂的实例(xxxFactory.newInstance())
通过解析器工厂获取解析器( factory.newDocumentBuilder() or factory.newSAXParser() )
四个类:分别针对dom和sax解析
dom:
-DocumentBuilder:解析器类
- 这个类是一个抽象类,不能new,
此类的实例可以从 DocumentBuilderFactory.newDocumentBuilder() 方法获取
- 一个方法,可以解析xml parse("xml路径") 返回是 Document 整个文档
- 返回的document是一个接口,父节点是Node,如果在document里面找不到想要的方法,到Node里面去找
- 在document里面方法
getElementsByTagName(String tagname)
-- 这个方法可以得到标签
-- 返回集合 NodeList
createElement(String tagName)
-- 创建标签
createTextNode(String data)
-- 创建文本
appendChild(Node newChild)
-- 把文本添加到标签下面
removeChild(Node oldChild)
-- 删除节点
getParentNode()
-- 获取父节点
NodeList list
- getLength() 得到集合的长度
- item(int index)下标取到具体的值
getTextContent()
- 得到标签里面的内容
-DocumentBuilderFactory:解析器工厂
- 这个类也是一个抽象类,不能new
newInstance() 获取 DocumentBuilderFactory 的实例。
sax:
-SAXParser:解析器类
- 这个类是一个抽象类,不能new,
此类的实例可以从 SAXParserFactory.newSAXParser()方法获取
- 一个方法,可以解析xml parse("xml路径",事件处理器)
- 重写一个类继承DefaultHandler 的三个自动调用方法(startElement / characters / endElement)
-SAXParserFactory:解析器工厂
- 这个类也是一个抽象类,不能new
newInstance() 获取 SAXParserFactory 的实例。
>>dom4j解析器(将sax和dom解析方法集合一起,可以增删改查)
需要导包(不是javase的一部分)
1.创建解析器
SAXReader reader = new SAXReader();
2.得到document(父节点是Node,如果document找不到想要的方法就去Node去找)
Document document = reader.read(url); // xml文档的路径url
3.得到根结点(Element父节点也是Node,找不到的方法就去Node)
Element root = document.getRootElement(); //获取根结点
4.得到所需结点,根据需求进行操作
List<Element> list = root.elements("p");
....
但是这样一层一层获取会有点慢
所以dom4j提供了可以和XPATH结合的方式来进行查询元素
默认是不允许xpath的
所以需要导包 jaxen-1.1-beta-6.jar
在dom4j里面提供了Document的两个方法,用来支持xpath
*** selectNodes("xpath表达式")
- 获取多个节点
*** selectSingleNode("xpath表达式")
- 获取一个节点
xpath表达式:可以直接获取到某个元素 ,不用一层一层获取
* 第一种形式
/AAA/DDD/BBB: 表示一层一层的,AAA下面 DDD下面的BBB
* 第二种形式
//BBB: 表示和这个名称相同,表示只要名称是BBB,都得到
* 第三种形式
/*: 所有元素
* 第四种形式
** BBB[1]: 表示第一个BBB元素
×× BBB[last()]:表示最后一个BBB元素
* 第五种形式
** //BBB[@id]: 表示只要BBB元素上面有id属性,都得到
* 第六种形式
** //BBB[@id='b1'] 表示元素名称是BBB,在BBB上面有id属性,并且id的属性值是b1
>>jdom解析器
大致和dom4j差不多
String xmlpath = TEST.class.getResource("/test.xml").getFile();
try {
xmlpath = URLDecoder.decode(xmlpath, "utf-8");
} catch (UnsupportedEncodingException e1) {
e1.printStackTrace();
}
SAXBuilder builder=new SAXBuilder(false);
try {
Document doc=builder.build(xmlpath);
JDOM 类
JDOM定义了几个Java类。以下是最常见的类:
-
Document - 表示整个XML文档。文档Document对象是通常被称为DOM树。
-
Element - 表示一个XML元素。 Element对象有方法来操作其子元素,它的文本,属性和名称空间。
-
Attribute 表示元素的属性。属性有方法来获取和设置属性的值。它有家长和属性类型。
-
Text 表示XML标记的文本。
-
Common 表示一个XML文档中的注释。
常见的JDOM方法
使用JDOM,还有会经常用到的几种方法:
-
SAXBuilder.build(xmlSource)() - 构建XML源的JDOM文档。
-
Document.getRootElement() - 得到XML的根元素。
-
Element.getName() - 获取XML节点的名称。
-
Element.getChildren() - 得到一个元素的所有直接子节点。
-
Node.getChildren(Name) - 获得具有给定名称的直接子节点。
-
Node.getChild(Name) - 获取使用给定名称的第一个孩子节点。