Kylin简介
使命是超高速的大数据OLAP(Online Analytical Processing),也就是要让大数据分析像使用数据库一样简单迅速,用户的查询请求可以在秒内返回。
Hadoop
Hadoop诞生以来,大数据的存储和批处理问题均得到了妥善解决,而如何高速地分析数据也就成为了下一个挑战。于是各式各 样的“SQL on Hadoop”技术应运而生,其中以Hive为代表,Impala、Presto、 Phoenix、Drill、SparkSQL等紧随其后。它们的主要技术是“大规模并行处 理”(Massive Parallel Processing,MPP)和“列式存储”(Columnar Storage)。大规模并行处理可以调动多台机器一起进行并行计算,用线性增加的资源来换取计算时间的线性下降。列式存储则将记录按列存放,这样做不
仅可以在访问时只读取需要的列,还可以利用存储设备擅长连续读取的 特点,大大提高读取的速率。这两项关键技术使得Hadoop上的SQL查询
速度从小时提高到了分钟。
大数据OLAP的特征:
- 大数据查询要的一般是统计结果,是多条记录经过聚合函数计算后的统计值。
- 聚合是按维度进行的,由于业务范围和分析需求是有限的,有意义的维度聚合组合也是相对有限的,一般不会随着数据的膨胀而增长
预计算
尽量多地预先计算聚合结果,在查询时刻应尽量使用预算的结果得出查询结果,从而避免直接扫描可能无限增长的原始记录。
工作原理
MOLAP(Multidimensional Online Analytical Processing)Cube,也就是多维立方体分析。
- 维度就是观察数据的角度。比如电商的销售数据,可以从 时间的维度来观察,也可以进一步细化,从时间和 地区的维度来观察
- 度量就是被聚合的统计值,也是聚合运算的结果,它一般是连续的 值
- 对于每一种维度的组合,将度 量做聚合运算,然后将运算的结果保存为一个物化视图,称为Cuboid。所 有维度组合的Cuboid作为一个整体,被称为Cube。一个 Cube就是许多按维度聚合的物化视图的集合。
- Apache Kylin的工作原理就是对数据模型做Cube预计算,并利用计算的结果加速查询
1)指定数据模型,定义维度和度量。
2)预计算Cube,计算所有Cuboid并保存为物化视图。
3)执行查询时,读取Cuboid,运算,产生查询结果。
由于Kylin的查询过程不会扫描原始记录,而是通过预计算预先完成表的关联、聚合等复杂运算,并利用预计算的结果来执行查询。
技术架构
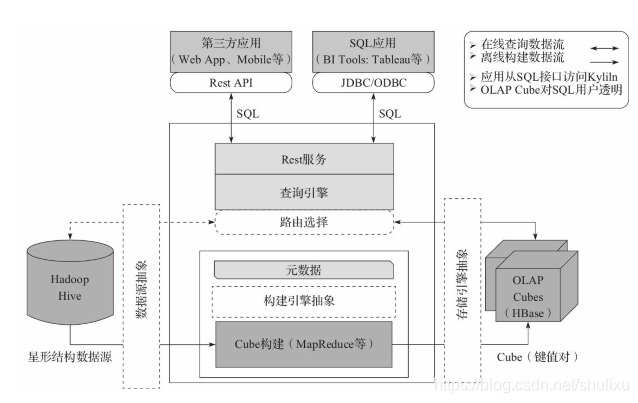
- 下方是离线部分(构建cube),上方是在线部分(用户查询)。
- Kylin屏蔽了Cube概念,用户不可见,而是通过各种Rest API, JDBC、ODBC接口调用。SQL给予关系模型来写。
- 查询引擎解析SQl,生成给予关系表的逻辑执行计划,转译成基于Cube的物理执行计划,最后查询预计算生成的Cube并产生结果。
- 整个过程不访问数据源
- Kylin 1.5引入了可扩展架构概念。体现在三个虚线部分的抽象层。这三个模块分别是数据源,构建引擎,存储引擎。默认的分别是HIve,Mapreduce,HBase。这三部分被抽象成接口,用户可以根据需要做二次开发进行替换。
主要特点
Apache Kylin的主要特点包括支持SQL接口、支持超大数据集、亚秒级 响应、可伸缩性、高吞吐率、BI工具集成等。
-
标准SQl接口
终端用户只需要像原来查询 Hive表一样编写SQL,就可以无缝地切换到Kylin,几乎不需要额外的学 习,甚至原本的Hive查询也因为与SQL同源,大多都无须修改就能直接在 Kylin上运行。 -
支持超大数据集
Kylin可以支撑的数据集大小没有上限,仅受限于存储系统和分布式计算系统的承载能力,并且查 询速度不会随数据集的增大而减慢。Kylin在数据集规模上的局限性主要在于维度的个数和基数 -
亚秒级 响应
Apache Kylin在某生产环境中 90%的查询可以在3s内返回结果 -
可伸缩性、高吞吐率
随着服务器的增加,吞吐率也呈线 性增加,这主要还是归功于预计算降低了查询时所需的计算总量,令Kylin可以在相同的硬件配置下承载更多的并发查询。 -
BI工具集成