1、基于统计特征的关键词提取算法
基于于统计特征的关键词抽取算法的思想是利用文档中词语的统计信息抽取文档的关键词。通常将文本经过预处理得到候选词语的集合,然后采用特征值量化的方式从候选集合中得到关键词。基于统计特征的关键词抽取方法的关键是采用什么样的特征值量化指标的方式。
TF-IDF
2、基于词图模型的关键词抽取算法
PageRank算法是整个google搜索的核心算法,是一种通过网页之间的超链接来计算网页重要性的技术,其关键的思想是重要性传递。在关键词提取领域, Mihalcea 等人所提出的TextRank算法就是在文本关键词提取领域借鉴了这种思想。
PageRank
PageRank是一种网页排名算法,网页质量的评估是遵循以下两个假设的:
- 数量假设:一个节点(网页)的入度(被链接数)越大,页面质量越高
- 质量假设:一个节点(网页)的入度的来源(哪些网页在链接它)质量越高,页面质量越高
TextRank算法
当TextRank应用到关键字抽取时,每个词不是与文档中所有词都有链接。那么如何界定链接关系?学者们提出了一个窗口的概念。在窗口中的词相互间都有链接关系。得到了链接关系,就可以套用TextRank的公式,对每个词的得分进行计算。最后选择得分最高的n个词作为文档的关键词。
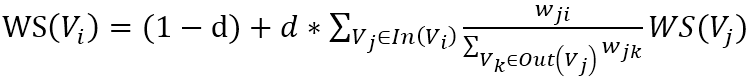
节点 i 的权重取决于节点 i 的邻居节点中 i-j 这条边的权重 / j 的所有出度的边的权重 * 节点 j 的权重,将这些邻居节点计算的权重相加,再乘上一定的阻尼系数,就是节点 i 的权重,阻尼系数 d 一般取 0.85。
TextRank 用于关键词提取的算法如下:
(1)把给定的文本 T 按照完整句子进行分割,即:
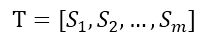
(2)对于每个句子,进行分词和词性标注处理,并过滤掉停用词,只保留指定词性的单词,如名词、动词、形容词,其中 ti,j 是保留后的候选关键词。
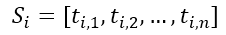
(3)构建候选关键词图 G = (V,E),其中 V 为节点集,由(2)生成的候选关键词组成,然后采用共现关系(Co-Occurrence)构造任两点之间的边,两个节点之间存在边仅当它们对应的词汇在长度为 K 的窗口中共现,K 表示窗口大小,即最多共现 K 个单词。
(4)根据 TextRank 的公式,迭代传播各节点的权重,直至收敛。
(5)对节点权重进行倒序排序,从而得到最重要的 T 个单词,作为候选关键词。
(6)由(5)得到最重要的 T 个单词,在原始文本中进行标记,若形成相邻词组,则组合成多词关键词。
Rake
Rake算法的实现,请点击:https://github.com/zelandiya/RAKE-tutorial
3、基于主题模型的关键词抽取
LDA
基于主题关键词提取算法主要利用的是主题模型中关于主题的分布的性质进行关键词提取。
参考文献:
https://blog.csdn.net/ZJL0105/article/details/82230237