版权声明:路漫漫其修远兮,吾将上下而求索。 https://blog.csdn.net/Happy_Sunshine_Boy/article/details/86345414
Producer and Consumer
- Producer通过主动Push的方式将消息发布到Broker,Consumer通过Pull从Broker消费数据
Pull的优点
- Consumer按实际处理能力获取相应的数据,不会被压垮
- Broker实现简单
- 如果处理不好,实时性相对不足
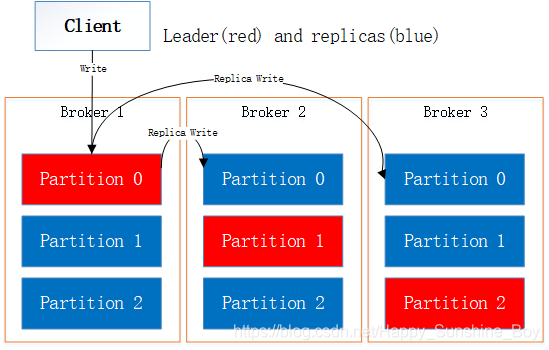
KafKad读写机制
- 每个partition有一个leader和若干个Follower(replica)

- 用户的读写都是通过Leader完成
- Follower从Leader拉取数据
KafKa vs zookeeper
Leader,Follower
- 所有的Follower都可提供读服务
- 写操作都会被forward到Leader
- Client与Server通过NIO通信
- 所有的写操作全局串行化FIFO执行
Consumer Group
High Level Consumer
- 高层抽象,屏蔽掉细节,提供丰富的语义,适合大多数应用场景
- 客户只需要从KafKa顺序读取数据,而无需关心offset等具体细节
- 语义级别控制同一条消息只被某一个Consumer消费或被所有Consumer消费
- 使用High Level Consumer 的客户程序提供给KafKa一个名字,这个名字被称为Consumer Group
- Consumer Group是整个KafKa集群全局唯一的,而非针对某个Topic
- 每个High Level Consumer实例都属于一个Consumer Group,若不指定则属于默认的Group
- High Level Consumer从某个Partition读取的最后一条消息的offset会被存于KafKa的一个专用topic中
- 消息被消费后,并不会被删除,只是相应的offset加一
- 对于每条消息,在同一个Consumer Group里,只会被一个Consumer消费
- 不同Consumer Group可消费同一条消息
Consumer Balance
- 将Topic下的所有Partition排序
- 对Consumer Group下所有Consumer排序
- N=size§/size©,向上取整
- 将N个Partition分配给C(每个Consumer分配N个Partition)