版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/hongbin_xu/article/details/84793030
Show and Tell: A Neural Image Caption Generator
Show and Tell
1、四个问题
- 要解决什么问题?
- Image Caption(自动根据图像生成一段文字描述)。
- 用了什么方法解决?
- 作者提出了一个基于深度循环架构的生成式模型。
- 训练时的目标是最大化这个从输入图像到目标描述语句的似然。
- 效果如何?
- 所提出模型在几个数据集上的效果都不错。
- 比如,此前在Pascal数据集上效果最好的BLEU-1分数是25,这里达到了59,与人类的表现(69左右)相当。
- 在Flickr30k上的BLEU-1分数从56提高到了66。
- 在SBU上,从19提高到了28.
- 在最新的COCO数据集上,BLEU-4分数达到了27.7,是目前最好的结果。
- 还存在什么问题?
- 由于这篇论文是在15年发表的,当时的state-of-the-art,现在已经算是比较落后的了。
- 图像特征仅仅是只在开始的时候以bias的形式传入,只关注到了全局特征,模型也是学习到了一种模板然后往里面填词。
2、论文概述
2.1、简介
- Image Caption任务,顾名思义,就是让算法根据输入的一幅图像自动生成对应的描述性文字。
- Image Caption的难点在于,不止要检测到图像中的物体,还需要表示出这些物体相互之间的关系。
- 此前关于Image Caption的尝试,大多数是考虑将那些子问题的一些现有的解决算法拼在一起。
- Image Caption任务数学模型:
- 输入图像为 。
- 输出语句是 ,每个单词 都是从一个给定的字典中得到的。可以充分地对图像进行描述。
- 目标函数是最大化似然函数: 。
- 文中提出的主要思路来自于最近的机器翻译相关的工作。
- 机器翻译的主要任务是将源语言的语句 转换为目标语言的语句 ,通过最大化似然函数 。
- 近期的工作中使用RNN做机器翻译可以取得相当不错的效果。
- 整体思路是:使用一个“编码器”RNN读取源语句,并将其转换为长度固定的特征向量,而这些特征向量又被用作“解码器”RNN的初始隐藏层状态。最后使用“解码器”RNN来生成目标语句。

- 上图是文中提出的模型,NIC。
- 思路很简单,在机器翻译中有一个编码器RNN、一个解码器RNN,然后把编码器RNN替换成CNN。
- 在近些年来的研究中,已经充分证明了CNN可以从输入图像中充分地提取特征并嵌入到一个定长的向量中。
- 很自然地,可以将CNN用作一个编码器,先在ImageNet上进行预训练,随后将其最后一层隐藏层作为作为RNN的输入。
- 论文的贡献有以下三点:
- 提出了一个端到端的系统来解决Image Caption任务。
- NIC模型结合了分别在CV和NLP领域state-of-the-art的子网络模型。
- 相比其他方法,取得了state-of-the-art的效果。
2.2、模型
- 近期的基于统计机器翻译的发展说明了,只要提供了一个强大的序列模型,我们能够直接通过最大化给定输入语句的正确翻译的概率(以一种端到端的方式),来获得state-of-the-art的结果。
- 这些模型使用RNN对变长输入进行编码,得到定长的特征向量,然后再用来解码成期望的输出语句。
- 将编码器的部分换成,输入图像到CNN,输出定长的特征向量。
- 最大化似然的公式可以描述为如下公式:
- ,其中 是输入图像, 是正确的图像描述, 是模型的参数。
- 可以表示任意语句,它的长度是不确定的。
- 使用链式法则来对
到
的联合概率建模是很常见的:
- 。
- 为简便起见,丢弃了 的依赖。
- 训练中, 是一对样本对。我们求上式的log概率之和,使用SGD进行优化,使其最大。
- 使用RNN来对 建模,0到 为止的可变词数可以用一个定长的隐藏层 来表示。
- 在得到一个新的输入 后,会使用一个非线性函数 更新 。
- 为了让上述的RNN模型更具体,还有两个重要的问题要考虑:
- 非线性函数
具体的形式是什么样子?
- 使用一个LSTM网络来表示。
- 图像和单词如何转换成输入
?
- 使用CNN从图像提取特征,来表示图像。
- 非线性函数
具体的形式是什么样子?
2.3、LSTM
- 在设计和训练RNN过程中,最具挑战的是如何解决梯度消失和梯度爆炸的问题,所以选择了LSTM。

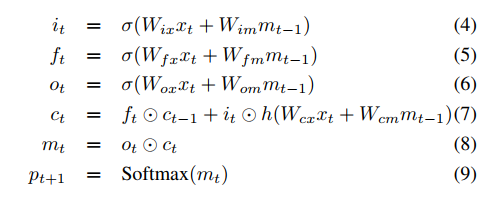
2.4、训练

- 如果用 表示输入图像,用 表示描述这个图像的真实句子,展开过程如下:
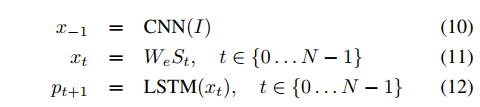
- 每个单词都被表示为一个与字典等长的one-hot向量 。
- 表示开始单词, 表示结束单词。 从LSTM检测到停止单词,就意味着已经生成了一个完整的句子。
- 图像和单词都被映射到同一个特征空间,使用CNN提取图像特征,使用word embedding将单词映射为词向量。
- 图像只在 时输入,以告知LSTM图像中的内容。
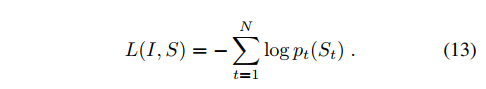
- loss函数是每个步骤中正确单词的负对数概率之和。
2.4、Inference
- 我们有多种方法来使用NIC模型根据输入图像生成描述。
- 第一种是采样。我们可以根据 采样得到第一个单词,然后提供对应的embedding作为输入,并采样 ,不断重复,知道我们采样到特殊句末标识,或到达了最大句长。
- 第二种是BeamSearch。迭代地选取直到时间 最好的 个语句作为候选,来长度为 时刻的句子,最后只保留其中的 个最好结果。
- 后续的实验中采用BeamSearch的方法,beam大小为20。如果将beam大小取为1,结果会降低2个BLEU点数。
2.5、实验
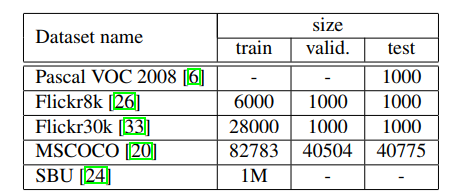
- 数据集
- 训练细节:
- 训练中很容易碰到过拟合。
- 解决过拟合的一个很简单的办法就是,提供大量的数据。但是已有的数据量却不足。
- 经过实验,作者发现最有效的避免过拟合的方法是使用预训练权重(ImageNet)来初始化CNN。
- 另外一组权重,即word embedding的权重,使用在一个大型新闻语料库下预训练的结果效果并不理想。所以最后为简单起见,直接就不对其做初始化。
- 还用了其他一些防止过拟合的策略:dropout,ensemble等。
- 训练时采用SGD,学习率固定,没有momentum。除了CNN的权重采用ImageNet的预训练权重,其他权重参数都是随机初始化的。
- embedding的维度是512维,也是LSTM记忆单元的大小。
- 生成结果见表1。

- 生成多样性讨论
- 表3显示了从beamsearch解码器中返回的N个最佳列表的一些样本,而不是最好的假设。

- 如果选出最好的候选句子,那么这个句子就会在约80%的时间里出现在训练集中。考虑到训练数据较少,并不难预料到,模型相对容易会选取一个模板句子,然后填词进去。
- 如果分析的是生成的前15个最好的句子,大约在50%的时间内,我们可以看到一个全新的语句描述,也可以取得差不多高的BLEU分数。
- 排名结果:

- 人工评估:


- word embedding分析
- 把输入的前一个词 送入LSTM然后输出 ,使用了word embedding方法,这样能够摆脱字典大小的依赖。
- 如表6中所示,一些示例单词,和其最近邻的词向量所对应的单词。
- 请注意模型学习到一些关系是如何帮助视觉组件的。
- 比如,将“马”、“小马”和“驴”的词向量彼此靠近,将会鼓励CNN提取与马匹动物相关的特征。
