项目搭建过程
一、新建python项目
在对应的地址 中 打开 cmd
输入:scrapy startproject first
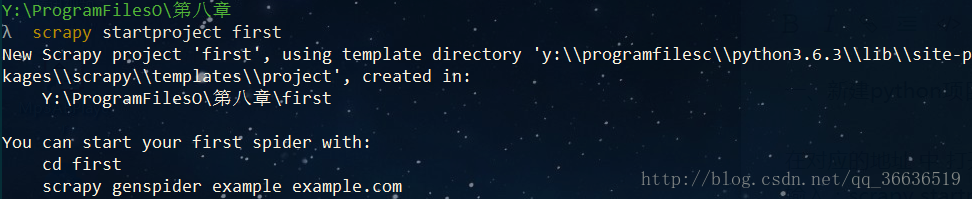
2、在pyCharm 中打开新创建的项目,创建spider 爬虫核心文件ts.py
import scrapy
from first.items import FirstItem
from scrapy.http import Request # 模拟浏览器爬虫
class WeisuenSpider(scrapy.Spider):
name = ‘ts’
allowed_domains = [‘hellobi.com’]
start_urls = (
‘https://edu.hellobi.com/course/100/‘,
)
# 模拟浏览器爬虫
def start_requests(self):
ua={
“User-Agent”: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36 QIHU 360SE’}
yield Request(‘https://edu.hellobi.com/course/100/‘,headers=ua)
def parse(self, response):
item=FirstItem()
item[“title”]=response.xpath(“//ol[@class=’breadcrumb’]/li[@class=’active’]/text()”).extract()
item[“view”]=response.xpath(“//div/span[@class=’course- view’]/text()”).extract()
yield item #用来返回
3、在items 中编辑需要爬取的内容
import scrapy
class FirstItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field() # 爬取标题
view=scrapy.Field() # 爬取观看人数
4、在 ts.py 中利用xpath 设置爬取规则
from first.items import FirstItem
def parse(self, response):
item=FirstItem()
item[“title”]=response.xpath(“//ol[@class=’breadcrumb’]/li[@class=’active’]/text()”).extract()
item[“view”]=response.xpath(“//div/span[@class=’course-view’]/text()”).extract()
yield item #用来返回
5、在pipelines.py设置输出
class FirstPipeline(object):
def process_item(self, item, spider):
print(item[“title”])
print(item[“view”])
return item
6、在 setting.py 中打开 pipelines 和设置默认的爬虫规则为False
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure item pipelines
ITEM_PIPELINES = {
‘first.pipelines.FirstPipeline’: 300,
}
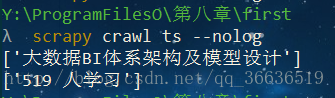
7、运行结果
总结
1、关于python解释器的问题
pyCharm 在设置默认解释器时有提供三种不同的方式
- Virtualenv Environment
- Conda Environment
- System Interpreter
应选择 System Interpreter
2、关于xpath的总结
- / 表示从顶端去提取信息
/html/head/title/text() 表示:提取 html 下面的 head 下面的 title 下面的 text() 标签
- // 寻找所有的标签
//ol/il/text() 表达:提取 所有 的 ol 标签下面的 il 标签下面的 text()标签
- @ 提取标签下的属性值:
//li[@class=”hidden-xs”]/a/@href
提取 含有 class=”hidden-xs” 的li 标签 下的 a 标签 下的 href 属性
3、 srapy 命令 总结
- 全局命令(全局命令可以在全局使用,包括项目)
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
fetch
scrapy fetch http://www.baidu.com 作用:爬取百度网页信息
scrapy fetch http://www.baidu.com –nolog 不显示日子的爬取
runspider
不依托爬虫项目(文件夹),来运行爬虫文件(program.py)
在文件所在目录下:输入 scrapy runspider first.py
startproject 创建一个项目
scrapy startproject 项目名
view 下载某个网页,并且用浏览器来查看的命令
scrapy view http://news.163.com
scrapy genspider -l 罗列所有的爬虫母版
basic 基本爬虫母版
crawl 自动爬虫母版
csvfeed 用于csv 文件
xmlfeed 用于xml 文件
常用命令:
scrapy genspider -t basic 爬虫文件名 域名
crawl 运行某个爬虫
scrapy crawl 爬虫名(不用加py)
4、爬虫项目结构
first (项目名称)
first 文件夹
scrapy.efg
first 文件夹:(核心目录)
- spiders 文件夹
- init.py
- items.py
- pipeline.py
- settings.py
init.py 爬虫项目的初始化文件
items.py 爬虫需要爬取的内容 ,是个容器
pipeline.py 爬取信息后的过滤文件
setting,py 对爬虫进行设置 伪装浏览器,用户代理