防止enumerate()循环后出错
enumerate和for循环
enumerate和for循环很像,for循环是遍历一个列表里所有的元素,enumerate()对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引(标签)和值(元素),
当遍历列表时有删除操作时
- 代码
a=["soccer","basketball","pingpong","run","play","game"]
b=[]
for num,i in enumerate(a):
print(num,i)
if len(i) > 6:
print('删除'+i)
del a[num]
else:
b.append(i)
print(a)
print(b)
- 运行结果
[‘soccer’, ‘pingpong’, ‘run’, ‘play’, ‘game’]
[‘soccer’, ‘run’, ‘play’, ‘game’] - 解释
发现结果中满足条件(长度大于6)的ping-pong并没有被删除,下面模拟一下enumerate运行过程,enumerate的过程并不一定是按每个元素过滤一遍,而是按每个索引(0,1,2,3…)过滤一遍。
循环过程如下:
| 索引 | 第一次循环 | 第二次循环 | 第三次循环 | 第四次 | 第五次 | 第六次 |
|---|---|---|---|---|---|---|
| 0 | soccer | soccer | soccer | soccer | soccer | soccer |
| 1 | basketball | pingpong | pingpong | pingpong | pingpong | pingpong |
| 2 | pingpong | run | run | run | run | run |
| 3 | run | play | play | play | play | play |
| 4 | play | game | game | game | game | game |
| 5 | game |
第一次循环标签为0的soccer元素,不满足条件(长度<6),保留元素。第二次循环索引为1的basketball元素,满足条件,删除元素。在第三次循环开始的时候,由于上一个循环删除了basketball元素,所以basketball后面的元素索引都会减一。所以pingpong元素的索引由原来的2,变成了1。但第二次循环已经遍历了索引为1的元素,所以第三次循环不会再遍历这个索引以及对应的元素。所以满足删除条件的pingpong元素没有被删除。
解决方法
- 只要让满足删除条件的两个元素不挨着,那就可以删除所有满足条件的元素。
- 让列表中的元素倒着循环。
a=["soccer","game","play","pingpong","run","basketball"]
b=[]
for num,i in enumerate(a):
print(num,i)
if len(i) > 6:
print('删除'+i)
del a[num]
else:
b.append(i)
print(a)
print(b)
运行结果:
[‘soccer’, ‘game’, ‘play’, ‘run’]
[‘soccer’, ‘game’, ‘play’]
为什么b列表只有两个元素呢?
因为删除元素后,run的新索引之前被遍历过了,所以就自动略过了。
dataframe的索引
数据框(dataframe)每一行对应的标签是不会变化的
np.random.seed(123)
df = pd.DataFrame(np.random.randn(5,3))
df.drop([0],axis=1,inplace=True)
print(df)
运行结果:
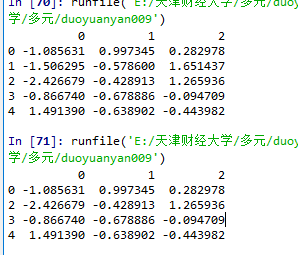
第二行被删除了,但是每一行原来对应的索引还是原来的索引。