Envoy threading Model
关于envoy 代码的底层文档相当稀少。为了解决这个问题我计划编写一系列文档来描述各个子系统的工作。由于是第一篇, 请让我知道你希望其他主题覆盖哪些内容。
一个我所了解到最共同的技术问题是关于envoy使用的线程模型的底层描述,这篇文章将会描述envoy如何使用线程来处理连接的(how envoy maps connections to threads), 同事也会描述Thread Local Storage(TLS)系统是如何使内部代码平行且高效的。
Threading overview
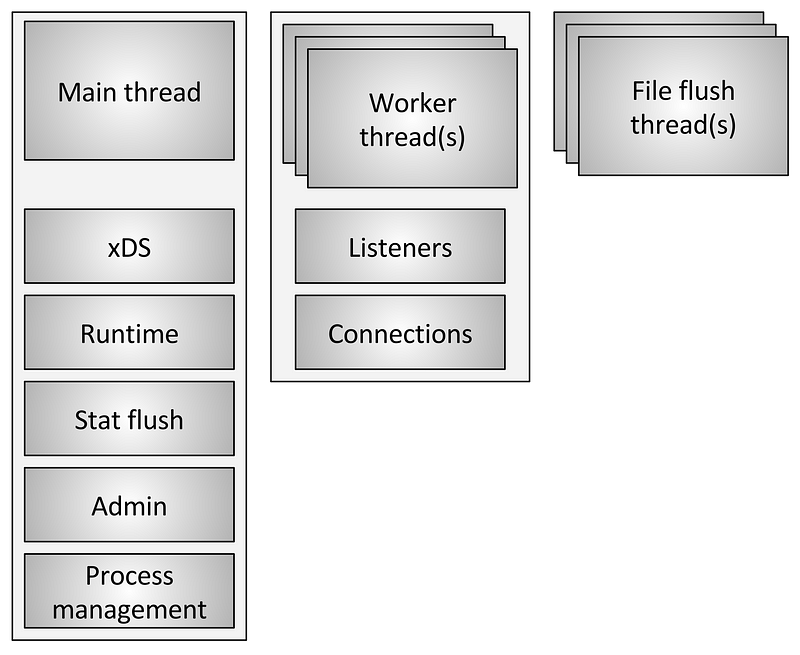
Figure 1: Threading overview
如同图一所示,envoy使用了三中不同类型的线程。
Main: 这个线程管理了服务器本身的启动和终止, 所有xDS API的处理(包括DNS, 健康检查(health checking) 和通常的集群管理), running, 监控刷新(stat flushing), 管理界面 还有 通用的进程管理(signals, hot restart。在这个线程中发生的所有事情都是异步和非阻塞的(non blocking)。通常,主线程用来协调所有不需要大量cpu完成的关键功能。这允许大部分代码编写的如同单线程一样。
Worker 在envoy系统中,默认为每个硬件(every harware)生成一个worker线程(可以通过--concurrency参数控制),每个工作线程运行一个无阻塞的事件循环(event loop),for listening on every listener (there is currently no listener sharding), accept 新的连接,为每个连接实例化过滤栈,以及处理这个连接生命周期的所有io。同时,也允许所有连接代码编写的如同单线程一样。
File flusher Envoy 写入的每个文件现在都有一个单独的block的刷新线程。这是因为使用O_NONBLOCK在写入文件系统有时也会阻塞。当Worker线程需要写入文件时,这个数据实际上被移动至in-memory buffer中,最终会被File Flusher线程刷新至文件中。envoy的代码会在一个worker试图写入memory buffer时锁住所有worker。还有一些其他的会在下面讨论。
连接处理
如上所述, 所有worker线程都会监听端口而没有任何分片,因此,内核智能的分配accept的套接字给worker进程。现代内核一般都很擅长这一点,在开始使用其他监听同一套接字的其他线程之前,内核使用io 优先级提升等特性来分配线程的工作,同样的还有不适用spin-lock来如理所有请求。
一旦woker accept了一个连接,那么这个连接永远不会离开这个worker(一个连接只由同一worker进行处理), 所有关于连接的处理都将会在worker线程内进一步处理,包括任何转发行为。这有一些重要的含义:
Envoy连接池中都是worker线程,因此通过http/2 连接池每次只与上游主机建立一个连接,如果有4个worker,那在稳定状态将只有四个http/2连接与上游主机进行连接。
Envoy以这种方式工作的原因在于这样几乎所有的代码都可以如同单线程一样以没有锁的方式进行编写。这个设计使得大部分代码易于编写和扩展。
从内存和连接池效率的角度来看,调整 - concurrency选项实际上非常重要。拥有比所需要的worker更多的worker将会浪费大量的内存,造成大量空置的连接,并导致较低的连接池命中率。在lyft,envoy以较低的concurerency运行,性能大致与他们旁边的服务相匹配。
non-blocking意味着什么
到目前为止,在讨论主线程和worker线程时我们已经多次使用术语'non-blocking'.几乎所有代码都是假设没有阻塞的情况下进行编写。但是,这并非完全正确(哪里有完全正确的东西),Envoy确实使用了一些process wide locks.
- 正如上述,如果在写入访问日志, 所有worker都会获得同样的锁在将访问日志填充至内存缓存1前。锁应当保持较短的时间,但是这个锁有可能在高并发和高吞吐量时进行竞争。
- Envoy使用了一个非常复杂的系统来处理线程本地的统计数据,这将是另一个帖子的主题,我简要的介绍一下,作为线程本地统计处理的一部分,它有时会获得一个对于中央统计商店2的锁, 这个锁不应当被经常竞争。
- 主线程定期需要协调所有worker线程。这是通过主线程发不到工作线程来完成的。发布过程需要lock来锁定消息队列。这个锁不应当被高度争用,但从技术上可以进行阻止。
- 当envoy记录日志至stderr, 它将会获得process wide lock。 通常来说, envoy 本地日志被认为对于性能来说是糟糕的,所以没有改善该过程的想法。
- 还有一切其他随机锁。但他们都不在影响性能的过程中,也永远不当被争用。
线程局部变量3
由于envoy将主线程的职责和worker线程的职责完全分开,需要在主线程完成复杂的处理同时使每个worker线程高度可用。本节将介绍Envoy的高级线程本地存储(TLS)系统。在下一节中,我将描述如何使用它来处理集群管理。
如已经描述的那样,主线程基本上处理Envoy过程中的所有管理/控制平面功能。(控制平面在这里有点过载,但在特使程序本身考虑并与工人做的转发进行比较时,似乎是合适的)。主线程进程执行某些操作是一种常见模式,然后需要使用该工作的结果更新每个工作线程,并且工作线程不需要在每次访问时获取锁定
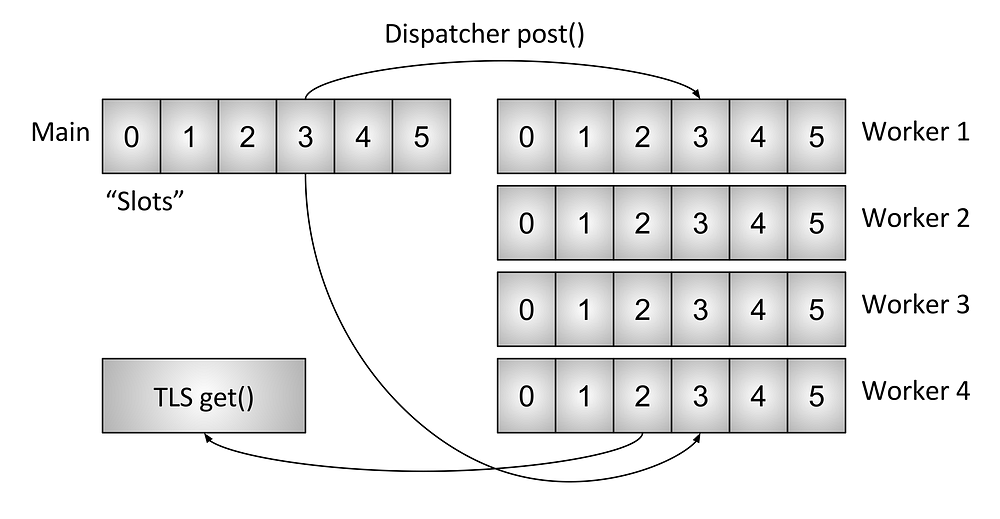
Envoy的TLS系统工作如下:
- 运行在主线程的代码分配了一个线程范围的TLS插槽4,虽然是abstracted的,但实际上时允许o(1)访问的索引
- 主线程可以设置任意数据在slot中,当它完成时,这个数据将会发送到所有worker作为一个正常的事件循环
- 工作线程可以从TLS插槽中读取获取它所能获取的局部数据。
虽然非常简单,但它非常强大与只读副本更新锁类似.(实质上,worker线程在工作时从不会看到插槽的数据发生任何改变, 变化只发生在event切换的时候5), Envoy用两种不同的方式来使用它:
- 存储不同的数据在每个worker上,获取时不需要任何锁
- 通过将指向只读全局数据的共享指针存储到每个worker上,从而,每个worker具有该数据的引用计数,该计数在工作时不会递减。仅当所有worker查询和读取新的共享数据时会将原数据摧毁,这与RCU相同。
集群更新线程
在本节中,我将描述TLS如何用于集群管理。群集管理包括xDS API处理和DNS以及运行状况检查。
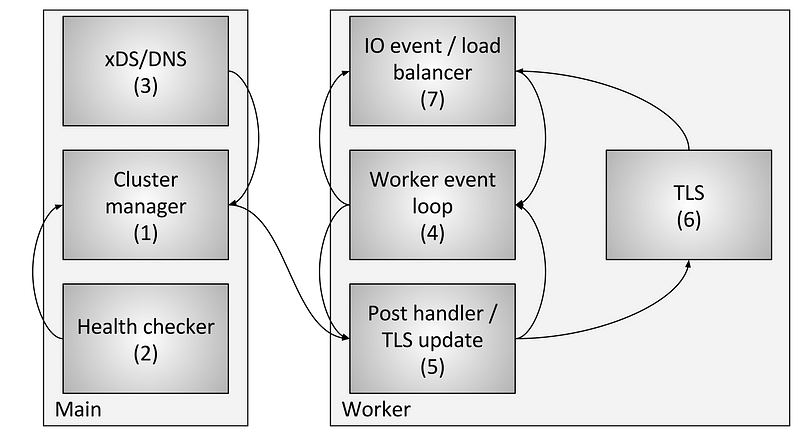
图3显示了涉及以下组件和步骤的总体流程:
- 集群管理器(Cluster Manager)在envoy中管理已知上游的集群,包括CDS API, SDS/EDS API DNS 和活跃的健康检查。它负责创建每个上游主机最终一致的视图,上游主机包括了发现的主机和健康统计。
- 健康检查器(Health Checker)进行活跃健康检查,并将健康检查的统计结果返回给集群管理器(Cluster Manager).
- CDS/SDS/EDS/DNS 用来决定集群的成员,一旦状态改变会返回给集群管理器(Cluster Manager).
- 每个Worker 线程包含一个 Event Loop。
- 当集群管理器要改变集群的状态时,它将创建一个集群状态只读的快照(Snapshot), 并将它发送给每一个worker 线程。
- 在下一个静止期中,worker线程将更新存在TLS中的快照
- 在IO事件需要确定主机如何负载均衡时,负载均衡器(Load Banlancer)将会查询TLS中存有的集群状态信息,这个过程中是无锁的。(TLS也可以触发事件使得负载均衡器和其他组件重新计算高速缓存和数据结构。但这超出了本文的范围)
通过这些过程,Envoy能够处理每个请求而不使用任何锁。除了TLS代码本身的复杂度之外,大部分代码无需理解线程是如何具体工作的,使用单线程的方式即可。这使得大部分代码易于修改且性能较好。
其他使用TLS的子系统
TLS和RCU(Read-Copy Update6)在Envoy内广泛使用。
其他一些例子包括:
- Runtime (feature flag) overide lookup 运行时覆盖查找:现在的feature flag overide map是在主线程进行计算的。为每个线程提供只读的快照用来实现RCU。
- Route table swapping 路由表交换:对于RDS提供的路由表,路由表在主线程上实例化。
然后使用RCU语义为每个工作程序提供只读快照.这使得路由表在原子级别上进行交换。 - HTTP data header caching http数据头缓存: 事实证明,在每个请求上计算HTTP日期标题非常昂贵。Envoy大约每半秒计算一次日期标题,并通过TLS和RCU将其提供给每个worker线程。
还有其他情况,但前面的例子应该已经足够阐释TLS在envoy中的作用。
已知的性能陷阱
虽然Envoy整体表现相当不错,但是当它以非常高的并发和高吞吐使用时,有一些已知的点需要注意:
- 正如前文描述的那样,现在当写入日志的内存缓冲区时,所有worker线程都会获得锁,在高并发和吞吐使用时,若要写入最终文件,就会被要求处理所有worker线程的访问日志,这将导致日志的无序。
- 尽管统计信息已经经过了很多的优化,在非常高的并发性和吞吐量下,个别统计数据仍然可能存在原子争用。解决方案时每个工人进行统计,并定期刷新到中央计数器。
- 如果Envoy部署在需要大量资源来处理的少量连接的场景下,现有的体系结构将无法正常工作。这是因为无法保证连接在worker 线程之间均匀分布。这可以通过实现再平衡来解决,其中worker 线程能够将连接转发给另一个worker 线程进行处理。
总结
Envoy的线程模型旨在简化编程和提高性能,但如果设置不当,可能会浪费内存和连接使用。Envoy的线程模型允许它在非常高的worker数量和高吞吐量下表现良好。
正如我在Twitter上简略提到的那样,该设计也适合在DPDK之类的完整用户模式网络堆栈上运行,这使得商用服务器在进行完整的L7处理时每秒处理数百万个请求。观察envoy再接下来几年如何进展是一件非常有趣的事情
。
最后一个评论:我多次被问到为什么我们为Envoy选择C ++?
原因是它仍然是唯一广泛部署的生产语言,在该语言中可以构建本文所述的体系结构。C ++当然不适合所有项目,甚至许多项目,但对于某些用例,它仍然是完成工作的唯一工具。