scrapy
scrapy是一个爬取网站数据,提取结构性数据的框架。注意敲重点是框架。框架就说明了什么?——提供的组件丰富,scrapy的设计参考了Django,可见一斑。但是不同于Django的是scrapy的可拓展性也很强,所以说,你说你会用python写爬虫,不了解点scrapy。。。。
scrapy使用了Twisted异步网络库来处理网络通讯,整体架构如下图:
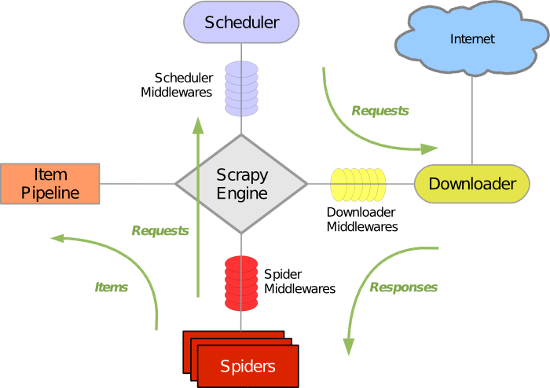
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
好介绍到这里。面试题来了:谈谈你对scrapy架构的理解:

上面就是我的理解,你的理解与我的可能不一样,以你的为准,面试的时候如果被问到了。千万要说,这东西怎么说都对。不说的话,一定会被面试官反问一句:你还有什么要补充的吗?。。。。
安装:
pass
直接开始写代码吧。
项目上手,利用scrapy爬取抽屉。读到这里你是不是有点失望了?为什么不是淘宝?不是腾讯视频?不是知乎?在此说明下抽屉虽小,五脏俱全嘛。目的是为了展示下scrapy的基本用法没必要将精力花在处理反爬虫上。
在开始我们的项目之前,要确定一件事就是我们要爬取什么数据?怎么存储数据?这个案例使用到的Mysql最为容器存储数据的。设计的表结构如下:
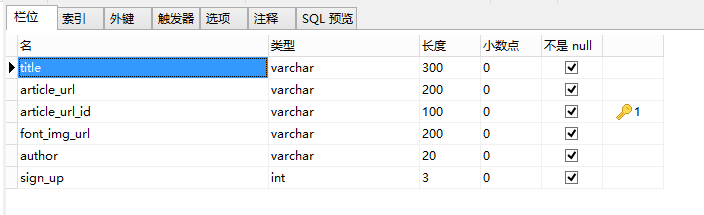
有了这些字段就能着手于spider的编写了,第一步首先写item类


1 import datetime 2 import re 3 4 import scrapy 5 from scrapy.loader import ItemLoader 6 from scrapy.loader.processors import Join, MapCompose, TakeFirst 7 8 9 def add_title(value): 10 """字段之后加上签名""" 11 return value + 'Pontoon' 12 13 14 class ArticleItemLoader(ItemLoader): 15 """重写ItemLoader,从列表中提取第一个字段""" 16 default_output_processor = TakeFirst() 17 18 19 class ChouTiArticleItem(scrapy.Item): 20 """初始化items""" 21 title = scrapy.Field( 22 input_processor=MapCompose(add_title) 23 ) 24 article_url = scrapy.Field() 25 article_url_id = scrapy.Field() 26 font_img_url = scrapy.Field() 27 author = scrapy.Field() 28 sign_up = scrapy.Field() 29 30 def get_insert_sql(self): 31 insert_sql = ''' 32 insert into chouti(title, article_url, article_url_id, font_img_url, author, sign_up) 33 VALUES (%s, %s, %s, %s, %s, %s) 34 ''' 35 params = (self["title"], self["article_url"], self["article_url_id"], self["font_img_url"], 36 self["author"], self["sign_up"],) 37 return insert_sql, params
下一步解析数据(这里并没由对下一页进行处理,省事!)
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.http import Request 4 5 from ..items import ChouTiArticleItem, ArticleItemLoader 6 from ..utils.common import get_md5 7 8 9 class ChoutiSpider(scrapy.Spider): 10 name = 'chouti' 11 allowed_domains = ['dig.chouti.com/'] 12 start_urls = ['https://dig.chouti.com/'] 13 header = { 14 "User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) " 15 "Chrome/71.0.3578.98 Safari/537.36" 16 } 17 18 def parse(self, response): 19 article_list = response.xpath("//div[@class='item']") 20 for article in article_list: 21 item_load = ArticleItemLoader(item=ChouTiArticleItem(), selector=article) # 注意这里的返回值并不是response了 22 article_url = article.xpath(".//a[@class='show-content color-chag']/@href").extract_first("") 23 item_load.add_xpath("title", ".//a[@class='show-content color-chag']/text()") 24 item_load.add_value("article_url", article_url) 25 item_load.add_value("article_url_id", get_md5(article_url)) 26 item_load.add_xpath("font_img_url", ".//div[@class='news-pic']/img/@src") 27 item_load.add_xpath("author", ".//a[@class='user-a']//b/text()") 28 item_load.add_xpath("sign_up", ".//a[@class='digg-a']//b/text()") 29 article_item = item_load.load_item() # 解析上述定义的字段 30 yield article_item
OK,这时我们的数据就被解析成了字典yield到了Pipline中了
1 import MySQLdb 2 import MySQLdb.cursors 3 from twisted.enterprise import adbapi # 将入库变成异步操作 4 5 6 class MysqlTwistedPipleline(object): 7 """抽屉Pipleline""" 8 def __init__(self, db_pool): 9 self.db_pool = db_pool 10 11 @classmethod 12 def from_settings(cls, settings): 13 """内置的方法自动调用settings""" 14 db_params = dict( 15 host=settings["MYSQL_HOST"], 16 db=settings["MYSQL_DBNAME"], 17 user=settings["MYSQL_USER"], 18 password=settings["MYSQL_PASSWORD"], 19 charset="utf8", 20 cursorclass=MySQLdb.cursors.DictCursor, 21 use_unicode=True, 22 ) 23 db_pool = adbapi.ConnectionPool("MySQLdb", **db_params) 24 25 return cls(db_pool) 26 27 def process_item(self, item, spider): 28 """使用twisted异步插入数据值数据库""" 29 query = self.db_pool.runInteraction(self.do_insert, item) # runInteraction() 执行异步操作的函数 30 query.addErrback(self.handle_error, item, spider) # addErrback() 异步处理异常的函数 31 32 def handle_error(self, failure, item, spider): 33 """自定义处理异步插入数据的异常""" 34 print(failure) 35 36 def do_insert(self, cursor, item): 37 """自定义执行具体的插入""" 38 insert_sql, params = item.get_insert_sql() 39 # chouti插入数据 40 cursor.execute(insert_sql, (item["title"], item["article_url"], item["article_url_id"], 41 item["font_img_url"], item["author"], item["sign_up"]))
再到settings.py中配置一下文件即可。
1 ITEM_PIPELINES = { 2 'ChoutiSpider.pipelines.MysqlTwistedPipleline': 3, 3 4 } 5 ... 6 7 MYSQL_HOST = "127.0.0.1" 8 MYSQL_DBNAME = "article_spider" # 数据库名称 9 MYSQL_USER = "xxxxxx" 10 MYSQL_PASSWORD = "xxxxx"
ok练手的项目做完了,接下来正式进入正题。
scrapy—pipeline组件
pipeline是用来做数据的持久化的,内部源码中给我们提供一些方法,下面介绍几种常见的。
1 from scrapy.exceptions import DropItem 2 3 class CustomPipeline(object): 4 def __init__(self,v): 5 self.value = v 6 7 def process_item(self, item, spider): 8 # 操作并进行持久化 9 10 # return表示会被后续的pipeline继续处理 11 return item 12 13 # raise DropItem() 表示将item丢弃,不会被后续pipeline处理 14 15 @classmethod 16 def from_crawler(cls, crawler): 17 """ 18 初始化时候,用于创建pipeline对象 19 :param crawler: 20 :return: 21 """ 22 val = crawler.settings.getint('XXXXX') 23 return cls(val) # 注意这种创建对象的方式,在scrapy源码中会大量遇见 24 25 def open_spider(self,spider): 26 """ 27 爬虫开始执行时,调用 28 :param spider: 29 :return: 30 """ 31 print('spider start') 32 33 def close_spider(self,spider): 34 """ 35 爬虫关闭时,被调用 36 :param spider: 37 :return: 38 """ 39 print('spider close')
scrapy—url去重的策略
url去重的问题用于分布式爬虫。