对象的创建:需要类的加载。对象创建图:
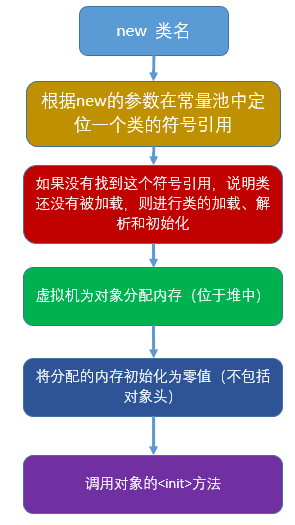
<init>方法是代码块(构造方法)
new类名和调用对象方法是可见的,
对象的内存分配。
堆是不连续的存储空间,堆内存是规整的,用过的放一边,没用过的放在一边。分配内存是指针移动的过程。
1.指针碰撞的内存分配方式:(java堆规整)

2.空闲列表:(java堆不规整)
1是使用的在一边,没有使用的在另一边,如果是使用的和没有使用的交错在一起的情况,它会建立一张空闲列表,空闲的内存区域都在这张表里,java堆的规整与否是由回收策略决定的
它会造成线程不安全问题(多线程一起发起多个请求,向空闲列表里申请内存,便会造成内存混乱问题)
1.线程同步(加锁解锁)
2.
对象的结构:
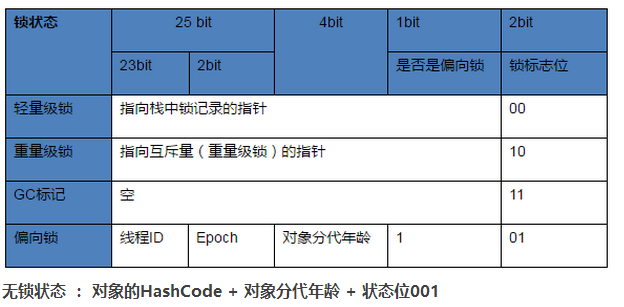
header(对象头)
1.自身运行时数据【mark word】(哈希值,GC分代年龄(为后面垃圾回收的各大算法服务),锁状态标识,偏向时间戳,线程持有的锁。。。。。。。。。)
更多详情可以看:http://www.cnblogs.com/duanxz/p/4967042.html
public class Object{
public final native Class<?> getClass();
}2.类型指针(指向对象 “元数据” 的指针)
instanceData(数据实例)
long, double放在一起
short/char放在一起(相同大小会放在一起)
padding (对齐填充,对象大小必须要8个字节)
对象访问定位:

垃圾回收:
判定对象为垃圾的算法
1.引用计数法:
在对象中添加一个引用计数器,当有地方引用到这个对象的时候,引用计数器的值就+1,当引用失败的时候,计数器的值就-1
-verbose:gc(简单打印垃圾回收的日志信息)
-XX:+PrintGCDetails (详细打印gc垃圾回收日志信息)
public class Main {
private Object instance;
public Main() {
//手动开辟20兆的空间
//1TB=1024GB 1GB=1024MB 1MB=1024KB 1KB=1024B 1B(字节byte)=8b(比特bit)
//1MB(Mebibyte,兆字节,百万字节,简称“兆”)=1024KB(千字节)= 2^20 byte=1024*1024 byte
byte [] m=new byte[20*1024*1024];
}
public static void main(String[] args) {
Main m1=new Main();
Main m2=new Main();
m1.instance=m2;
m2.instance=m1;
m1=null;
//销毁对象1
m2=null;
//销毁对象2
System.gc();
//手动调用垃圾回收器
}
}

2.可达性分析算法
从GCRoots节点出发,沿着引用链遍历对象,为被遍历的,便被判定为 垃圾(即对象没有任何的引用指向它,就会被标记为垃圾对象)

可作为GCRoots的对象
1.1虚拟机栈(这里指虚拟机栈中的局部变量表)
1.2方法区的类属型所引用的对象
1.3方法区中常量所引用的对象
1.4本地方法栈中引用的对象
回收垃圾:
1.标记-清除算法:
效率问题
空间问题
标记出要回收的对象

复制算法;
1.线程共享区:堆 (细分为:
新生代(
1.1 Eden 中文为伊甸园,创建一个对象,就会被扔到这里,新创建的就会在这里无忧无虑的生活,但也是死神垃圾回收器最喜欢光顾的地方
1.2 Survivor 存活区
1.3 Tenured Gen 养老区)
--------------------------------------------------------------------------------------------------------------------------
引用一段比喻:
JVM区域总体分两类,heap区和非heap区。heap区又分:Eden Space(伊甸园)、Survivor Space(幸存者区)、Tenured Gen(老年代-养老区)。 非heap区又分:Code Cache(代码缓存区)、Perm Gen(永久代)、Jvm Stack(java虚拟机栈)、Local Method Statck(本地方法栈)。

HotSpot虚拟机GC算法采用分代收集算法:
1、一个人(对象)出来(new 出来)后会在Eden Space(伊甸园)无忧无虑的生活,直到GC到来打破了他们平静的生活。GC会逐一问清楚每个对象的情况,有没有钱(此对象的引用)啊,因为GC想赚钱呀,有钱的才可以敲诈嘛。然后富人就会进入Survivor Space(幸存者区),穷人的就直接kill掉。
2、并不是进入Survivor Space(幸存者区)后就保证人身是安全的,但至少可以活段时间。GC会定期(可以自定义)会对这些人进行敲诈,亿万富翁每次都给钱,GC很满意,就让其进入了Genured Gen(养老区)。万元户经不住几次敲诈就没钱了,GC看没有啥价值啦,就直接kill掉了。
3、进入到养老区的人基本就可以保证人身安全啦,但是亿万富豪有的也会挥霍成穷光蛋,只要钱没了,GC还是kill掉。
分区的目的:新生区由于对象产生的比较多并且大都是朝生夕灭的,所以直接采用标记-清理算法。而养老区生命力很强,则采用复制算法,针对不同情况使用不同算法。
非heap区域中Perm Gen中放着类、方法的定义,jvm Stack区域放着方法参数、局域变量等的引用,方法执行顺序按照栈的先入后出方式。
--------------------------------------------------------------------------------------------------------------------------
) 方法区
2.线程独享:栈 本地方法栈 程序计数器
复制算法图:

优化后的

标记整理清除算法(用于老年代的垃圾回收)

分代收集算法:
内存分新生代和老年代,对于新生代,垃圾回收率较高的,会采用复制算法,对于老年代,内存回收率较低的,会采用标记清除算法。
垃圾收集器之Serial收集器(适用于客户端):
最基本,发展最悠久
单线程垃圾收集器

PraNew多线程收集器

Parallel Scavenge 收集器(适用于高并发情况)
采用复制算法(新生代收集器)
多线程收集器
达到可控制的 吞吐量(cpu用于运行用户代码的时间与cpu消耗的总时间的比值)
吞吐量=(执行用户代码时间)/(执行用户代码时间+垃圾回收所占的时间)
-XX:MaxGFPauseMillis垃圾收集器停顿时间
-XX:CGTimeRatio吞吐量大小
CMS收集器Concurrent Mark Sweep(高并发标记清除,用于老年代)
并发收集器(边扔边打扫)
并行缩短等待时间
并发可以提高速度


工作过程

优点:并发收集,低停顿
缺点:占用大量cpu资源, 无法处理浮动垃圾(打扫过一遍的垃圾你又给扔了) ,出现Concurrent Mode Failure (并发清理的回收垃圾池的内存区域分配过小),空间碎片 (由标记清除算法导致)
G1收集器(收集器界的老大,面向服务端)
优势:并行与并发,分代收集,空间整合,可预测的停顿
步骤:初始,并发,最终标记,筛选回收
