文章目录
安装
从官网下载Solr7.4(或本资源包内直接解压,本包内也是官网下载的)
下载地址:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/7.4.0/
因为我是Windows系统所以选的是.zip的版本,如果是Linux系统需要用.tgz的版本,下面都是以Windows系统下的示例。
Solr7.4是免安装的,解压后就可以直接使用了。
启动

打开之后是这样的

创建core
在cmd窗口输入:
solr create -c testcore
testcore 是自己起的名字,回车后会出现下面的信息(还是会有log4j2的错误信息,不用管)
一刷新

Core也可以直接在控制台创建,但是需要自己先再Solr安装根目录/server/solr目录下创建一个core文件夹,而且里面要自己创建一个data文件夹。然后通过控制台的Core Admin创建core 。
个人建议直接在cmd窗口用命令创建,省力省心还可靠。
网上还有自己拷贝conf文件夹到自己创建core 等等的操作,感觉太麻烦。有兴趣的自行百度。
配置core索引MySQL数据
1、把数据库驱动jar包放到
Solr安装根目录/server/solr-webapp/webapp/WEB-INF/lib下

2、把Solr安装根目录/dist文件夹下的
solr-dataimporthandler-x.x.x.jar
solr-dataimporthandler-extras-x.x.x.jar

放到Solr安装根目录/server/solr-webapp/webapp/WEB-INF/lib下

4、Solr安装根目录/server/solr/核心/conf路径下添加文件data-config.xml,并添加以下内容(示范如下)
<dataConfig>
<!-- url如果包含特殊字符如";",必须使用html转移字符 -->
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/solrdb" user="root" password="123456"/>
<document>
<!-- query为全量更新SQL -->
<entity name="testdb" pk="tid" query="select * from testdb">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="tid" name="idid"/>
<field column="tname" name="TName"/>
<field column="tbirthday" name="TBirthDay"/>
</entity>
</document>
</dataConfig>
---------------------
作者:这个冬天真的冷
来源:CSDN
原文:https://blog.csdn.net/h0713/article/details/82503848
版权声明:本文为博主原创文章,转载请附上博文链接!
3.2.1
solr默认使用UTC时间,即与中国时差8小时,所以需要修改配置文件:
Solr安装根目录/bin/solr.in.sh
SOLR_TIMEZONE=”UTC+8”
默认是注释掉的,找到SOLR_TIMEZONE修改后面的值为UTC+8
注意:如果单纯修改solr.in.sh文件没有作用,就修改和solr.in.sh同目录下的solr.cmd文件,修改其中的set SOLR_TIMEZONE=UTC为set SOLR_TIMEZONE=UTC+8
3.2.2
修改mysql数据库的表结构,添加一个时间戳字段,当某行数据发生更新时该字段自动更新为修改数据的时间,为solr增量添加提供服务(范例如下)
ALTER TABLE testdb ADD last_modified TIMESTAMP NOT NULL ON UPDATE CURRENT_TIMESTAMP DEFAULT current_timestamp
3.2.3
修改solr/server/solr/核心/conf路径下添加文件data-config.xml,并添加增量SQL(示范如下)
就是多添加了deltaQuery部分
<dataConfig>
<!-- url如果包含特殊字符如";",必须使用html转移字符 -->
<dataSource driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/solrdb" user="root" password="123456"/>
<document>
<!-- query为全量更新SQL -->
<entity name="testdb" pk="tid" query="select * from testdb"
deltaQuery="select tid from testdb where last_modified > '${dih.last_index_time}'">
<!-- 每一个field映射着数据库中列与文档中的域,column是数据库列,name是solr的域(必须是在managed-schema文件中配置过的域才行) -->
<field column="tid" name="idid"/>
<field column="tname" name="TName"/>
<field column="tbirthday" name="TBirthDay"/>
</entity>
</document>
</dataConfig>
4、修改solrconfig.xml,添加以下内容
data-config.xml
5、修改managed-schema,添加mysql中需要存入solr的字段(示范如下)
准备测试效果:
数据库里的数据:
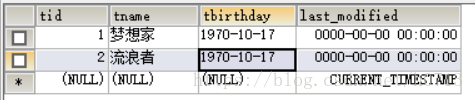
注意:当last_modified的值是0000-00-00 00:00:00时会有错误,
因为java的时间是从1970年开始的,所以不能翻译这个时间,导致的结果就是查不到数据。
现在测试全量更新:依次选择1234

结果是:


测试增量更新,在数据库新添一条数据
注意:增量更新就是只更新有变化的数据,不会更新没有变化的数据。如果增量更新选择clean会删除所有的原索引数据,然后只更新有修改过的数据。
正常使用情况下增量更新的clean是不选择的。这里为了测试更新方式是增量更新的方式,所以选择了clean。切忌用在项目中!!!除非你知道会有什么后果

结果是: 

我们看到,之前的两条数据被删除了,只有一条新添加的数据。证明增量更新的功能有效。
四、接下来我们配置一个实用的功能:定时更新
因为数据库的数据可能是动态变化的,为了能和数据库的数据“及时”同步,所以就有了这个功能。
它可以按设定时间自动更新一次索引
4.1修改testcore目录下的配置文件core.properties
name=testcore
config=solrconfig.xml
schema=data-config.xml
dataDir=data
4.2添加实时更新索引相关的jar包:dataimportscheduler-1.2.jar 到
Solr安装根目录/server/solr-webapp/webapp/WEB-INF/lib下
还有两个jar包因为之前已经添加过了就不需要添加了,是
solr-dataimporthandler-x.x.x.jar
solr-dataimporthandler-extras-x.x.x.jar
4.3 修改Solr安装根目录/server/solr-webapp/webapp/WEB-INF/web.xml
把这个添加到里面
org.apache.solr.handler.dataimport.scheduler.ApplicationListener
注意:中间的内容两边不要有空格,容易出现不正常现象
4.4添加更新配置文件:Solr安装根目录/server/solr下新建conf文件夹
在文件夹下新建dataimport.properties文件
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
#syncCores=game,resource
syncCores=testcore
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
port=8983
interval=2
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# URL params [mandatory]
# remainder of URL
params=/dataimport?command=delta-import&clean=false&commit=true
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
# 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
reBuildIndexInterval=7200
# 重做索引的参数
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=03:10:00
测试定时更新

我们先全量更新一下所有数据,然后在数据库添加一条数据,再等一分钟直接查询
更新前

更新后

五、配置中文分词
solr自带的几个分词器对中文支持并不好,所以需要使用第三方分词器对中文进行分词索引。
常用的分词器有:ansj和ik,前者的效果更好。
注:目前发现ansj分词器索引内容大小超过65248字节时,会报异常,目前尚未找到解决办法
5.1需要的jar包:
ansj_lucene5_plug-5.1.1.2.jar
ansj_seg-5.1.1.jar
ik-analyzer-solr5-5.x.jar
nlp-lang-1.7.2.jar
放到Solr安装根目录/server/solr-webapp/webapp/WEB-INF/lib 中
5.2配置放到Solr安装根目录/server/solr/testcore/conf下的managed-schema
(还是之前配置的那个)
!
<!-- ik分词器 -->
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" />
</analyzer>
<analyzer type="query">
<tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" />
<!-- 如果不做同义词,可以不配置下面这个Filter -->
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer></fieldType>
<!-- ansj分词器 -->
<fieldType name="text_ansj" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" isQuery="false" stopwords="/path/to/stopwords.dic"/>
</analyzer>
<analyzer type="query">
<tokenizer class="org.ansj.lucene.util.AnsjTokenizerFactory" stopwords="/path/to/stopwords.dic"/>
</analyzer>
</fieldType>
然后为要索引的字段添加分词器,例如
<field name="TName" type="text_ansj" indexed="true" stored="true"/>
测试


成功了!
SolrJ 操作索引的增、删、查
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import org.apache.solr.common.SolrInputDocument;
import java.io.IOException;
import java.util.Iterator;
public class IndexOperation {
private static final String urlString = "http://localhost:8983/solr/testcore";
private static SolrClient solr = new HttpSolrClient.Builder(urlString).build();
public void addIndexTest(){//添加一个索引
SolrInputDocument doc = new SolrInputDocument();
//默认id为主键,当id存在时更新数据,否则添加数据
doc.addField("id", "3");
doc.addField("name", "hello world test");
doc.addField("age", "230");
doc.addField("addr", "1111");
try {
solr.add(doc);
solr.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public void deleteIndexTest(String did){
//通过id删除索引
try {
solr.deleteById(did);
solr.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//通过搜索条件删除索引
//solr.deleteByQuery(query);
}
public void selectIndexTest(){// 查询
SolrQuery query = new SolrQuery();
// *标示多个任意字符,?标示单个任意字符,~模糊搜索
query.setQuery("*:*"); //全搜索
// 分页
query.setStart(0);
query.setRows(10);
QueryResponse queryResponse = null;
try {
queryResponse = solr.query(query);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
SolrDocumentList docs = queryResponse.getResults();
Iterator<SolrDocument> iter = docs.iterator();
while(iter.hasNext()){
SolrDocument doc = iter.next();
System.out.println(doc.toString());
}
try {
solr.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
//测试
public static void main(String[] args){
IndexOperation ion=new IndexOperation();
ion.addIndexTest();
ion.selectIndexTest();
System.out.println("---------------分割线-----------------");
ion.deleteIndexTest("3");
ion.selectIndexTest();
}
}

七、通过SolrJ对MySQL数据库进行全量更新、增量更新
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import org.apache.http.NameValuePair;
import org.apache.http.client.CookieStore;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.BasicCookieStore;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.message.BasicNameValuePair;
public class LinkMysql {//对数据库进行的操作,全量更新,增量更新
private CloseableHttpClient httpclient = null;
private CookieStore cookieStore = null;
private final String baseSolrUrl;
/**
* 全量导入
*/
private static final String FULL_IMPORT = "full-import";
/**
* 增量导入
*/
private static final String DELTA_IMPORT = "delta-import";
public LinkMysql(String baseSolrUrl) {
if(!baseSolrUrl.endsWith("/")){
baseSolrUrl += "/";
}
this.baseSolrUrl = baseSolrUrl;
}
private synchronized void init(){
if(httpclient == null){
cookieStore = new BasicCookieStore();
httpclient = HttpClientBuilder.create().setDefaultCookieStore(cookieStore).build();
}
}
public void fullImport(String coreName) throws IOException {
init();
HttpPost post = getDataImportPost(coreName, FULL_IMPORT);
httpclient.execute(post);
}
public void deltaImport(String coreName) throws IOException {
init();
HttpPost post = getDataImportPost(coreName, DELTA_IMPORT);
httpclient.execute(post);
}
private HttpPost getDataImportPost(String coreName,String command) throws UnsupportedEncodingException{
HttpPost post = new HttpPost(baseSolrUrl + coreName + "/dataimport?indent=on&wt=json&_=" + new Date().getTime());
List<NameValuePair> params = new ArrayList<NameValuePair>();
params.add(new BasicNameValuePair("command", command));
params.add(new BasicNameValuePair("verbose", "false"));
if(command.equals(FULL_IMPORT)){
params.add(new BasicNameValuePair("clean", "true"));
}
params.add(new BasicNameValuePair("commit", "true"));
params.add(new BasicNameValuePair("optimize", "false"));
params.add(new BasicNameValuePair("core", coreName));
params.add(new BasicNameValuePair("name", "dataimport"));
post.setEntity(new UrlEncodedFormEntity(params, "UTF-8"));
return post;
}
public void close() throws IOException{
httpclient.close();
httpclient = null;
cookieStore = null;
}
public static void main(String[] args){
//测试
LinkMysql dataClient=new LinkMysql("http://localhost:8983/solr/");
/*全量更新*/
try {
dataClient.fullImport("testcore");
dataClient.close();
} catch (IOException e) {
e.printStackTrace();
}
/*增量更新*/
/* try {
dataClient.deltaImport("testcore");
dataClient.close();
} catch (IOException e) {
e.printStackTrace();
}*/
}
}
八、索引高亮显示
需要有一个实体类
public class TXDocument {
private String id;
private String path;
private String content;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getPath() {
return path;
}
public void setPath(String path) {
this.path = path;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String toString() {
return "TXDocument{" +
"id='" + id + '\'' +
", path='" + path + '\'' +
", content='" + content + '\'' +
'}';
}
}
下面来高亮的代码
import org.apache.solr.client.solrj.SolrQuery;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.response.QueryResponse;
import org.apache.solr.common.SolrDocument;
import org.apache.solr.common.SolrDocumentList;
import java.io.IOException;
import java.util.List;
import java.util.Map;
public class GaoLiang {
public void setHighL(){
HttpSolrClient solrClient = new HttpSolrClient.Builder("http://127.0.0.1:8983/solr/testcore").build();
SolrQuery query = new SolrQuery();
query.set("q","TName:*回归*");//查询的内容
//1.过滤器
//query.set("fq","pprice:[1 TO 100]");//query.setFilterQueries("pprice:[1 TO 100]");也可以用addFiterQuries设置多过滤条件
//2.排序
//query.set("sort","pprice desc,id asc");//query.setSort("pprice",ORDER.desc); addSort
//3.设置查询到的文档返回的域对象
//query.set("fl","TBPackageName,PackageTypeID");//query.setFields("id,pname");
//4.设置默认查询的域
//query.set("df","pname");
//5.分页
//query.set("start",0); //query.setStart(0)
//query.set("rows",5); //query.setRows(5)
//6.高亮
//query.set("hl",true);
//设置高亮域(设置的域必须在查询条件中存在)
// query.set("h1.fl","TBPackageName");
//前缀
// query.set("hl.simple.pre","<em style='color:red'>");
//后缀
//query.set("hl.simple.post","</em>");
query.setHighlight(true);
query.addHighlightField("TName");
query.setHighlightSimplePre("<em style='color:red'>");
query.setHighlightSimplePost("</em>");
QueryResponse response=null;
{
try {
response = solrClient.query(query);
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
SolrDocumentList results = response.getResults();
System.out.println(results);
//k是id,内部的map的key是域名,其value是高亮的值集合
Map<String, Map<String, List<String>>> highlighting = response.getHighlighting();
System.out.println("匹配的结果总数是-------"+results.getNumFound());
for(SolrDocument document:results) {
System.out.println("id----" + document.get("id"));
System.out.println("pname-----" + document.get("TName"));
//System.out.println("pprice------" + document.get("pprice"));
List<String> list = null;
if(highlighting.get(document.get("id")) != null) {
list = highlighting.get(document.get("id")).get("TName");
}else {
System.out.println("无法获取高亮map");
}
System.out.println(list);
if (list != null && list.size() > 0) {
System.out.println("高亮显示的内容:----"+list.get(0));
}else {
System.out.println("高亮显示的内容为空!!!");
}
System.out.println("=========================");
}
}
public static void main(String[] args){
GaoLiang gl=new GaoLiang();
gl.setHighL();
}
}

如果之前你对高亮怎么用在前台显示的文字里,看到这个结果你应该能够猜到了,就是给需要高亮的字段加上了html标签,至于加什么效果,用什么标签就自己决定吧。高亮的意思不是闪闪发亮,只是一个让查询字段特别显示的代名词。
把这个以字符串的形式传给前台……后面就不需要我啰嗦了吧。
九、SolrJ读取富文本创建索引
就是读取word、pdf、xml……等文件的内容创建索引
import org.apache.solr.client.solrj.SolrClient;
import org.apache.solr.client.solrj.SolrServerException;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.apache.solr.client.solrj.request.AbstractUpdateRequest;
import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;
import java.io.File;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class FuWenBen {
public static void main(String[] args)
{ //测试
beStart("solr-word.pdf");
}
public static void beStart(String fname){
//富文本存放路径,这是示例就写的简单粗暴一些
String fileUrl = "E:/WorkSpace/ImportData/"+fname;
try
{
indexFilesSolrCell(fname, fname,fileUrl);
}
catch (IOException e)
{
e.printStackTrace();
}
catch (SolrServerException e)
{
e.printStackTrace();
}
}
/**
* @Author:sks
* @Description:获取系统当天日期yyyy-mm-dd
* @Date:
*/
private static String GetCurrentDate(){
Date dt = new Date();
//最后的aa表示“上午”或“下午” HH表示24小时制 如果换成hh表示12小时制
// SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss aa");
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String day =sdf.format(dt);
return day;
}
public static void indexFilesSolrCell(String fileName, String solrId, String path)
throws IOException, SolrServerException
{
String urlString = "http://localhost:8983/solr/testcore";
SolrClient solr = new HttpSolrClient.Builder(urlString).build();
ContentStreamUpdateRequest up = new ContentStreamUpdateRequest("/update/extract");
String contentType = getFileContentType(fileName);
up.addFile(new File(path), contentType);
String fileType = fileName.substring(fileName.lastIndexOf(".")+1);
up.setParam("literal.id", fileName);
up.setParam("literal.path", path);//文件路径
up.setParam("literal.pathuploaddate", GetCurrentDate());//文件上传时间
up.setParam("literal.pathftype", fileType);//文件类型,doc,pdf
up.setParam("fmap.content", "attr_content");//文件内容
up.setAction(AbstractUpdateRequest.ACTION.COMMIT, true, true);
solr.request(up);
}
/**
* @Author:sks
* @Description:根据文件名获取文件的ContentType类型
* @Date:
*/
public static String getFileContentType(String filename) {
String contentType = "";
String prefix = filename.substring(filename.lastIndexOf(".") + 1);
if (prefix.equals("xlsx")) {
contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";
} else if (prefix.equals("pdf")) {
contentType = "application/pdf";
} else if (prefix.equals("doc")) {
contentType = "application/msword";
} else if (prefix.equals("txt")) {
contentType = "text/plain";
} else if (prefix.equals("xls")) {
contentType = "application/vnd.ms-excel";
} else if (prefix.equals("docx")) {
contentType = "application/vnd.openxmlformats-officedocument.wordprocessingml.document";
} else if (prefix.equals("ppt")) {
contentType = "application/vnd.ms-powerpoint";
} else if (prefix.equals("pptx")) {
contentType = "application/vnd.openxmlformats-officedocument.presentationml.presentation";
}
else {
contentType = "othertype";
}
return contentType;
}
}
测试结果:内容太长,就截取了一部分,证明代码是成功的
