1 接着上一节往下介绍
将apache-solr-dataimportscheduler.src.jar包导入apache-tomcat-7.0.90\webapps\solr\WEB-INF\lib下
2 在solr_home新建文件夹conf,新建文件dataimport.properties,将下列代码复制其中。
#################################################
# #
# dataimport scheduler properties #
# #
#################################################
# to sync or not to sync
# 1 - active; anything else - inactive
syncEnabled=1
# which cores to schedule
# in a multi-core environment you can decide which cores you want syncronized
# leave empty or comment it out if using single-core deployment
syncCores=test,hotel
# solr server name or IP address
# [defaults to localhost if empty]
server=localhost
# solr server port
# [defaults to 80 if empty]
port=8080
# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr
# 增量索引的参数
# URL params [mandatory]
# remainder of URL
params=/dataimport?command=delta-import&clean=false&commit=true
# 重做增量索引的时间间隔
# schedule interval
# number of minutes between two runs
# [defaults to 30 if empty]
interval=1
# 重做全量索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引
#reBuildIndexInterval=7200
# 重做索引的参数
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true
# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2012-04-11 03:10:00 或者 03:10:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=03:10:00
3 进行如上代码后就完成了一分钟一更新的状态
4 进入apache-tomcat-7.0.90\webapps\solr\WEB-INF,打开web.xml,添加个监听器。
<listener>
<listener-class>org.apache.solr.handler.dataimport.scheduler.ApplicationListener</listener-class>
</listener>
5 进入 solr_home\news\conf ,打开data-config.xml,设置增量更新。
<entity name="new" pk="id"
query="SELECT id,title,content,imgurl FROM new_detail"
deltaImportQuery="SELECT id,title,content,imgurl FROM new_detail where id='${dih.delta.id}'"
deltaQuery="SELECT id,title,content,imgurl FROM new_detail where modifyDate > '${dih.last_index_time}'">
query和 deltaQuery属性的意思是,如果修改时间大于最后一次的时间就查询来此id,之后在根据此id查出信息。
6 此时在进入浏览器查看信息,就会发现如果mysql数据库的信息改变后,solr也会进行增量更新。
7 全文检索 :https://blog.csdn.net/menghuannvxia/article/details/41984445 这个博客介绍的安装分词器非常详细。
不同的是在solr_home\news\conf下的schema.xml下加入
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false"
class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true"
class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
接下来将与mysql数据库中指定的字段中的type由string改为text_ ik.
更改为:
<field name="id" type="int" indexed="true" stored="true"/>
<field name="title" type="text_ik" indexed="true" stored="true"/>
<field name="content" type="text_ik" indexed="true" stored="true"/>
<field name="imgurl" type="text_ik" indexed="true" stored="true"/>
<field name="text" type="text_general" indexed="true" stored="false"
全文检索如下:将词汇进行拆分:一如百度推广,输入几个词汇的话,就会出现很多相关的广告,原理就是用分词器检索实现的。
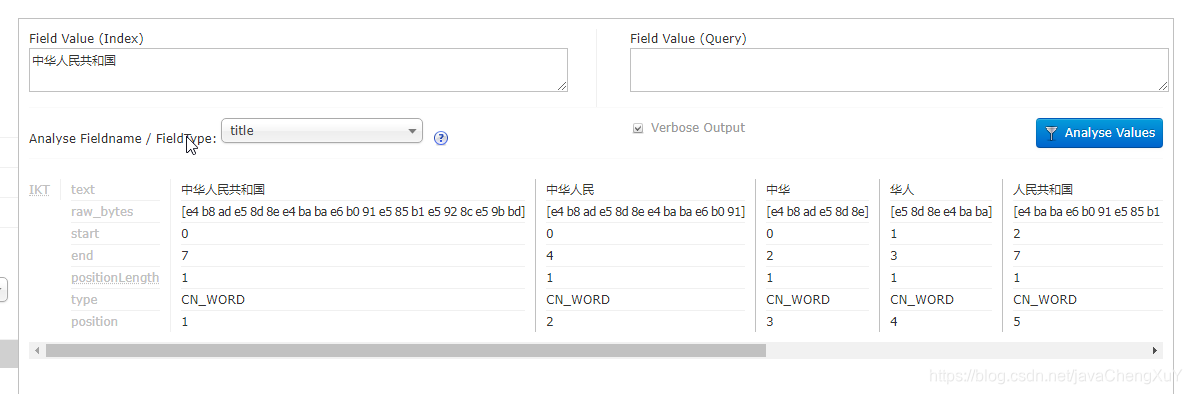
sole查询语法:
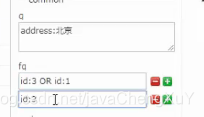
1 q:用于查询关键词
2 fq:用于对q查询的过滤;如下图,查询北京,过滤查询id等于3或者id等于1的,当和下面的id等于3是and的关系,相当于只查询id=3;
3 fq,在solr,执行完成后,会对数据进行缓存,查询数据比较快。

