Hystrix是什么
在分布式环境下,不可避免的有一些服务会失效,Hystrix通过延迟容忍和错误容忍逻辑,可以控制分布式服务之间的交互。Hystrix可以隔离服务访问入口、抑制级联错误、
支持fallback,所有的这些都可以提升系统的整体弹性(resiliency)。
Hystrix用来做什么
保护和控制访问服务的延迟和错误;
抑制在复杂分布式系统中的级联错误;
快速失败和快速恢复;
fallback和降级;
近实时的监控、报警以及操作控制。
Hystrix可以解决什么问题
在复杂的分布式系统中,通常都会存在许多服务依赖,不可避免会有服务失效。假设一个应用依赖30个服务,每个服务在99.99%的运行时间里都是正常的,可以计算:
99.99e30 = 99.7% uptime
0.3% of 1 billion requests = 3,000,000 failures
2+ hours downtime/month even if all dependencies have excellent uptime(99.99%).
所有服务健康时,请求流是这样的:

一个后端系统产生延迟就会影响用户整个请求:
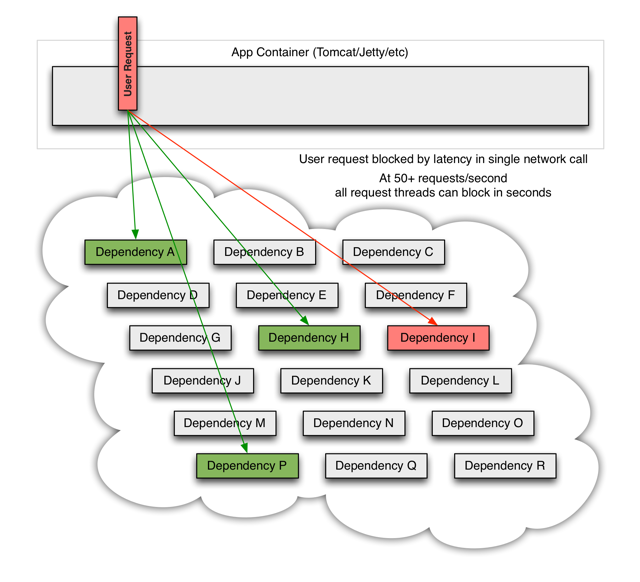
依赖的服务lib是一个“黑盒”,它大多都会进行网络请求,但更加糟糕的是该服务系统可能还会依赖其他服务。在高吞吐量的应用中,一个服务依赖的延迟可能在数秒内使整个服务器资源耗竭:
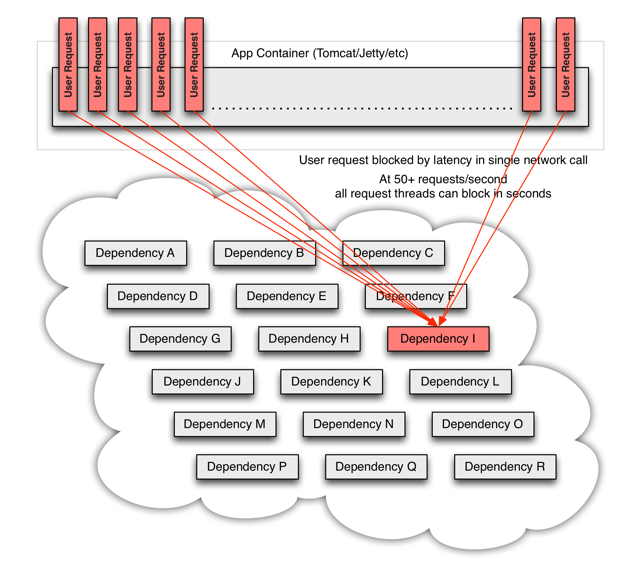
Hystrix如何解决问题
Hystrix可以将服务调用包裹在HystrixCommand中,每一个HystrixCommand都维护着一个threadpool,从而隔离服务,当一个服务产生延迟时,其“吞噬”的资源也只会限定在该HystrixCommand内(比如至多只会占用n个线程资源),而不会对全局造成影响。依赖threadpool,Hystrix还可以实现timeout操作。同时,当请求超时、异常、线程池满、熔断器打开时,Hystirx可以fallback。
