什么是熵?
熵是由热力学领域首次提出的。在机器学习领域内,熵用来表示数据的信息量大小。
在机器学习中,一个事件出现的概率越小,那么当这个事件发生时,它所代表的信息量越大的数据,其熵越大。
对于一个随机变量,其熵等于它所有可能取值信息的期望,公式如下:

当X 只有两个取值时,其熵与概率p之间的关系如下所示:

由此图可知,当p = 0.5 时,熵最大。其意义为,当这两种事件发生的概率相等时,很难预测下一次会发生的事件是哪个。故此时随机变量的混乱度最大,此时其熵最大。
如果要理解交叉熵,则必须首先理解一个概念叫 相对熵
相对熵(relative entropy) 又称为 KL 散度 (Kullback-Leibler divergence) 。其意义是用来表示两个随机分布之间的差别。记做
Dkl(p||q)

在机器学习领域,真实分布为p,假设分布为q。用KL 散度来度量q的无效性。其公式如下:

交叉熵
公式中的 Ep[-logq(x)] 就是交叉熵。其计算公式可变为:

当模型已知时,H(p)即为一个常数。
此时可认为交叉熵和 KL散度是等价的。结合机器学习的目的,可得出以下重要结论:
1. 当KL散度大时,交叉熵大,表示 p,q 两个随机分布之间的差别较大,由于p表示真实分布,q表示预测的分布。故可认为,此时预测分布与真实分布之间差距较大,此时的预测不准确。
2. 当KL散度较小时,交叉熵小,表示p,q两个随机分布之间的差别较小,可认为此时的预测较可信。
针对 logistic regression 来说,交叉熵 cross entropy 可认为是:
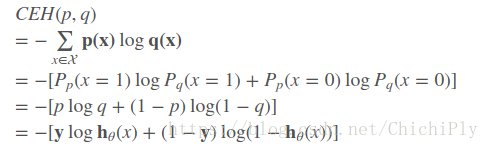
p是真实情况,q是预测情况。对应到模型的预测结果中,可认为 p = yi, q = yhat
当 yi = 0, yhat = 0 即预测和实际相等时,cross entropy = 0
当yi = 0 , yhat = 1 即预测和实际不等时,cross entropy = 正无穷
同理可得到 yi = 1 的情况。
所以可得出cross entropy 和模型准确率以及真值预测值之间的关系。
如果想要使得模型越准确,则需要使得 yhat 和 yi 的值尽量接近,则需要cross entropy 较小。
故可通过求cross entropy的最小值,来求某一组参数,这组参数使得 yhat 和 yi 的值尽量接近,那么就可以使整个模型更加接近准确模型。
最后通过字面含义来记住什么叫交叉熵。
首先理解“交叉”,这里的交叉是公式中将指p和 q结合在一起。p,q分别指两个随机分布。p是真实分布,q是预测分布。
“熵”是指 p * log(q)。
“交叉熵”的意义就是评价 p 和 q的相似程度。
Loss Function
所有的分类问题,其loss function 都可以是 交叉熵。其中模型参数出现在yhat中。通过对模型的参数进行更新,从而yhat的更新,使得loss function 越来越小。
参考链接:
https://blog.csdn.net/rtygbwwwerr/article/details/50778098