一、实验目标
用GPU加速FFT程序运行,测量加速前后的运行时间,确定加速比。
二、实验要求
- 采用CUDA或OpenCL(视具体GPU而定)编写程序
- 根据自己的机器配置选择合适的输入数据大小 n
- 对测量结果进行分析,确定使用GPU加速FFT程序得到的加速比
- 回答思考题,答案加入到实验报告叙述中合适位置
三、实验内容
使用CUDA进行FFT加速
使用到的代码如下
- FFT.h
-
typedef struct complex //复数类型 { float real; //实部 float imag; //虚部 }complex; #define PI 3.1415926535 void complex_plus(complex a, complex b, complex *c);//复数加 void complex_mul(complex a, complex b, complex *c);//复数乘 void complex_sub(complex a, complex b, complex *c); //复数减法 void complex_div(complex a, complex b, complex *c); //复数除法 void complex_abs(complex f[], float out[], float n);//复数数组取模 void fft(int N, complex f[]);//傅立叶变换 输出也存在数组f中 void ifft(int N, complex f[]); // 傅里叶逆变换 void conjugate_complex(int n, complex in[], complex out[]); - CUDA.h
-
#include "FFT.h" #include <iostream> #include <time.h> #include "cuda_runtime.h" #include "device_launch_parameters.h" #include "../include/cufft.h" #define NX 4096 // 有效数据个数 #define N 5335// 补0之后的数据长度 #define MAX 1<<12 #define BATCH 1 #define BLOCK_SIZE 1024 using std::cout; using std::endl; complex m[MAX], l[MAX]; bool IsEqual(cufftComplex *idataA, cufftComplex *idataB, const long int size) { for (int i = 0; i < size; i++) { if (abs(idataA[i].x - idataB[i].x) > 0.000001 || abs(idataA[i].y - idataB[i].y) > 0.000001) return false; } return true; } /** * 功能:实现 cufftComplex 数组的尺度缩放,也就是乘以一个数 * 输入:idata 输入数组的头指针 * 输出:odata 输出数组的头指针 * 输入:size 数组的元素个数 * 输入:scale 缩放尺度 */ static __global__ void cufftComplexScale(cufftComplex *idata, cufftComplex *odata, const long int size, float scale) { const int threadID = blockIdx.x * blockDim.x + threadIdx.x; if (threadID < size) { odata[threadID].x = idata[threadID].x * scale; odata[threadID].y = idata[threadID].y * scale; } } void conjugate_complex(int n, complex in[], complex out[]) { int i = 0; for (i = 0; i < n; i++) { out[i].imag = -in[i].imag; out[i].real = in[i].real; } } void complex_abs(complex f[], float out[], int n) { int i = 0; float t; for (i = 0; i < n; i++) { t = f[i].real * f[i].real + f[i].imag * f[i].imag; out[i] = sqrt(t); } } void complex_plus(complex a, complex b, complex *c) { c->real = a.real + b.real; c->imag = a.imag + b.imag; } void complex_sub(complex a, complex b, complex *c) { c->real = a.real - b.real; c->imag = a.imag - b.imag; } void complex_mul(complex a, complex b, complex *c) { c->real = a.real * b.real - a.imag * b.imag; c->imag = a.real * b.imag + a.imag * b.real; } void complex_div(complex a, complex b, complex *c) { c->real = (a.real * b.real + a.imag * b.imag) / (b.real * b.real + b.imag * b.imag); c->imag = (a.imag * b.real - a.real * b.imag) / (b.real * b.real + b.imag * b.imag); } #define SWAP(a,b) tempr=(a);(a)=(b);(b)=tempr void Wn_i(int n, int i, complex *Wn, char flag) { Wn->real = cos(2 * PI*i / n); if (flag == 1) Wn->imag = -sin(2 * PI*i / n); else if (flag == 0) Wn->imag = -sin(2 * PI*i / n); } //傅里叶变化 void fft(int NN, complex f[]) { complex t, wn;//中间变量 int i, j, k, m, n, l, r, M; int la, lb, lc; /*----计算分解的级数M=log2(N)----*/ for (i = NN, M = 1; (i = i / 2) != 1; M++); /*----按照倒位序重新排列原信号----*/ for (i = 1, j = NN / 2; i <= NN - 2; i++) { if (i < j) { t = f[j]; f[j] = f[i]; f[i] = t; } k = NN / 2; while (k <= j) { j = j - k; k = k / 2; } j = j + k; } /*----FFT算法----*/ for (m = 1; m <= M; m++) { la = pow(2, m); //la=2^m代表第m级每个分组所含节点数 lb = la / 2; //lb代表第m级每个分组所含碟形单元数 //同时它也表示每个碟形单元上下节点之间的距离 /*----碟形运算----*/ for (l = 1; l <= lb; l++) { r = (l - 1)*pow(2, M - m); for (n = l - 1; n < NN - 1; n = n + la) //遍历每个分组,分组总数为N/la { lc = n + lb; //n,lc分别代表一个碟形单元的上、下节点编号 Wn_i(NN, r, &wn, 1);//wn=Wnr complex_mul(f[lc], wn, &t);//t = f[lc] * wn复数运算 complex_sub(f[n], t, &(f[lc]));//f[lc] = f[n] - f[lc] * Wnr complex_plus(f[n], t, &(f[n]));//f[n] = f[n] + f[lc] * Wnr } } } } //傅里叶逆变换 void ifft(int NN, complex f[]) { int i = 0; conjugate_complex(NN, f, f); fft(NN, f); conjugate_complex(NN, f, f); for (i = 0; i < NN; i++) { f[i].imag = (f[i].imag) / NN; f[i].real = (f[i].real) / NN; } } bool IsEqual2(complex idataA[], complex idataB[], const int size) { for (int i = 0; i < size; i++) { if (abs(idataA[i].real - idataB[i].real) > 0.000001 || abs(idataA[i].imag - idataB[i].imag) > 0.000001) return false; } return true; } - Main
-
int main() { cufftComplex *data_dev; // 设备端数据头指针 cufftComplex *data_Host = (cufftComplex*)malloc(NX*BATCH * sizeof(cufftComplex)); // 主机端数据头指针 cufftComplex *resultFFT = (cufftComplex*)malloc(N*BATCH * sizeof(cufftComplex)); // 正变换的结果 cufftComplex *resultIFFT = (cufftComplex*)malloc(NX*BATCH * sizeof(cufftComplex)); // 先正变换后逆变换的结果 // 初始数据 for (int i = 0; i < NX; i++) { data_Host[i].x = float((rand() * rand()) % NX) / NX; data_Host[i].y = float((rand() * rand()) % NX) / NX; } dim3 dimBlock(BLOCK_SIZE); // 线程块 dim3 dimGrid((NX + BLOCK_SIZE - 1) / dimBlock.x); // 线程格 cufftHandle plan; // 创建cuFFT句柄 cufftPlan1d(&plan, N, CUFFT_C2C, BATCH); // 计时 clock_t start, stop; double duration; start = clock(); cudaMalloc((void**)&data_dev, sizeof(cufftComplex)*N*BATCH); // 开辟设备内存 cudaMemset(data_dev, 0, sizeof(cufftComplex)*N*BATCH); // 初始为0 cudaMemcpy(data_dev, data_Host, NX * sizeof(cufftComplex), cudaMemcpyHostToDevice); // 从主机内存拷贝到设备内存 cufftExecC2C(plan, data_dev, data_dev, CUFFT_FORWARD); // 执行 cuFFT,正变换 cudaMemcpy(resultFFT, data_dev, N * sizeof(cufftComplex), cudaMemcpyDeviceToHost); // 从设备内存拷贝到主机内存 cufftExecC2C(plan, data_dev, data_dev, CUFFT_INVERSE); // 执行 cuFFT,逆变换 cufftComplexScale << <dimGrid, dimBlock >> > (data_dev, data_dev, N, 1.0f / N); // 乘以系数 cudaMemcpy(resultIFFT, data_dev, NX * sizeof(cufftComplex), cudaMemcpyDeviceToHost); // 从设备内存拷贝到主机内存 stop = clock(); duration = (double)(stop - start) * 1000 / CLOCKS_PER_SEC; cout << "FFT经过GPU加速之后的时间为" << duration << "ms" << endl; cufftDestroy(plan); // 销毁句柄 cudaFree(data_dev); // 释放空间 if (IsEqual(data_Host, resultIFFT, NX)) cout << "逆变化检测通过。" << endl; else cout << "逆变换检测不通过。" << endl; //cpu fft for (long int i = 0; i < MAX; i++) { m[i].real = float((rand() * rand()) % 4096) / 4096; l[i].real = m[i].real; l[i].imag = m[i].imag = 0; } clock_t start2, end2; double duration1; start2 = clock(); fft(MAX, m); ifft(MAX, m); end2 = clock(); duration1 = (double)(end2 - start2) * 1000 / CLOCKS_PER_SEC; cout << "FFT经过CPU加速之后的时间为 " << duration1 << " ms" << endl; if (IsEqual2(m, l, MAX)) cout << "逆变化检测通过。" << endl; else cout << "逆变化检测不通过。" << endl; return 0; }
四、测试平台
-
CPU:i7-6500U
-
GPU:NVIDA GTX960M
-
内存:DDR3 8GB
-
操作系统:Windows 10 专业版
-
编译器:Microsoft Visual Studio Enterprise 2017
五、测试记录
分别测试数据集2^14、2^15、2^16、2^17、2^18时的运行情况
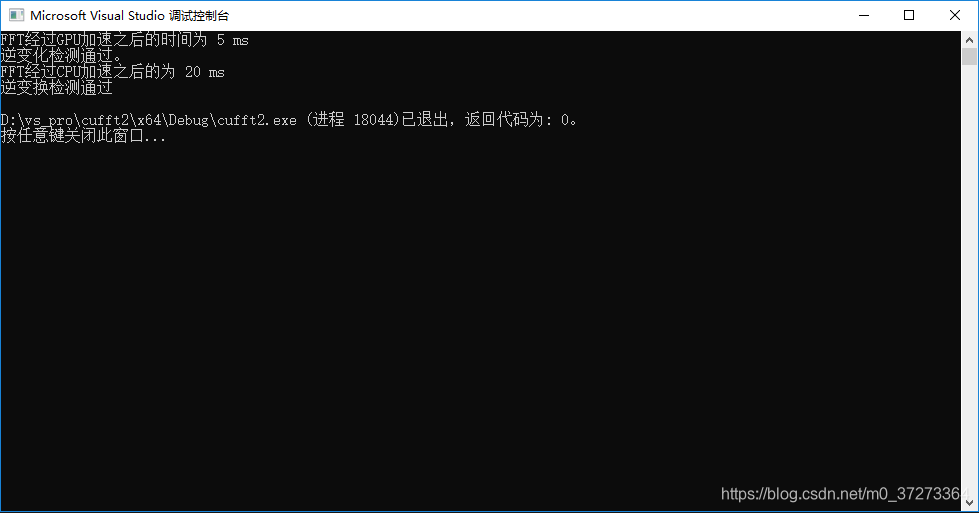
2^14
2^15
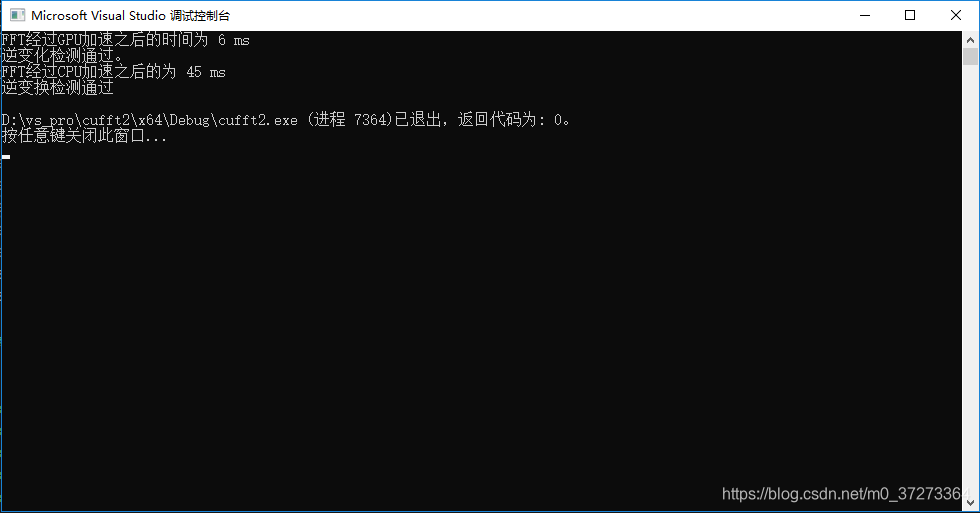
2^16
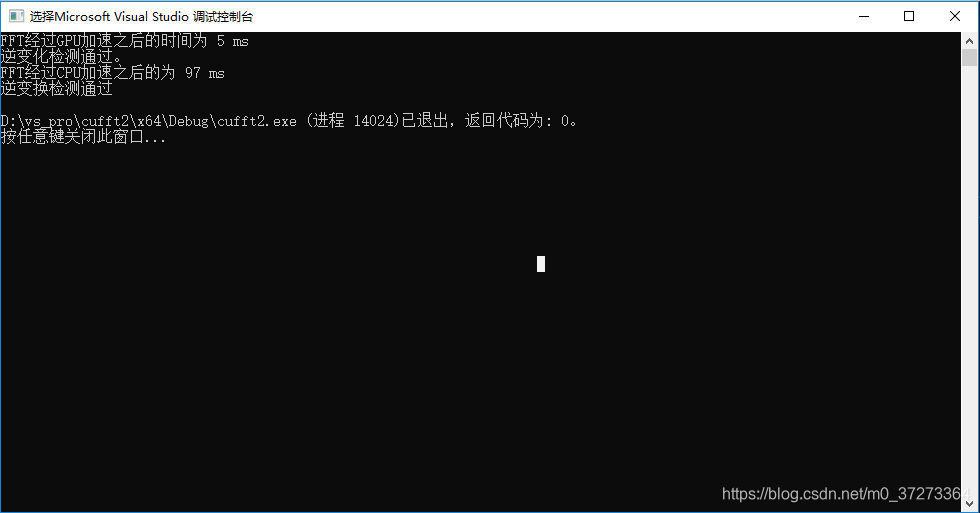
2^17
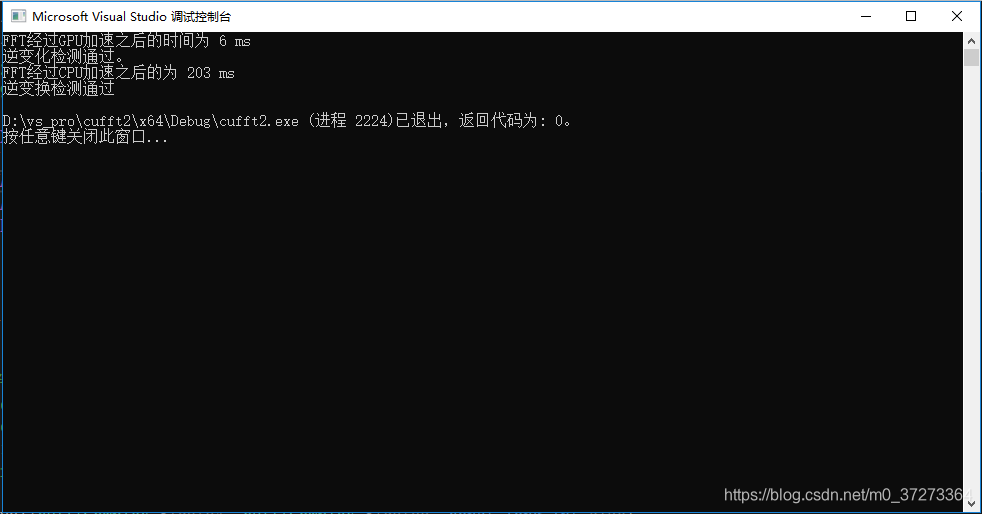
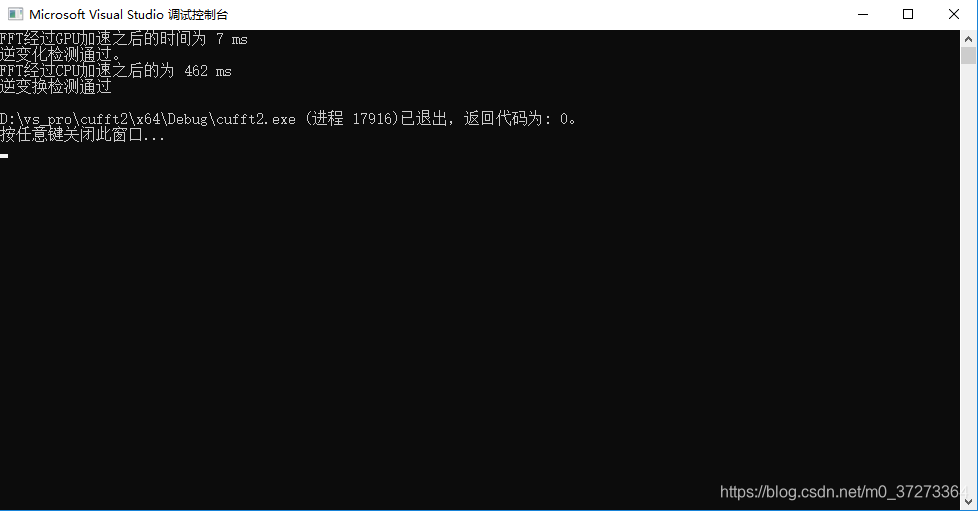
2^18
六、实验结果分析
根据运行的时间对比,可以看出,随着数据集的增加,CPU的处理时间和数据集的增加速率基本同步(数据集增大两倍,CPU处理时间增大两倍),而GPU的处理时间基本不变。
之前在做小数据集的时候发现经过GPU的加速运行时间和CPU的运行时间不相上下,甚至比CPU还要慢。
通过分析可以知道,当数据集较小时,数据在相关寄存器/内存的传送的时间对总时间的贡献更大主要,而当数据集很大的时候,计算时间对总时间的贡献更大。为了比较性能,于是就没有放小数据集的运行情况。
可以看到,对于大数据集,经过GPU加速,计算时间基本维持在了一个常数时间(其中也有程序运行的偶然性以及计时精度的问题,实际上运行时间应该线性增加,但是速率比CPU的2倍速慢)
七、思考题
分析GPU加速FFT程序可能获得的加速比
理论上,如果GPU可以一次存储完所有的数据,那么相对于CPU,数据传送的时间可以忽略,而CPU能够一次处理的数据块的大小有限,理论的加速比应该是GPU一次可以处理的数据块大小/CPU一次可以处理的数据块大小,因为实际上GPU就是对多个数据块的并行运算。但是这个加速比不可知(需要查阅相关的数据手册,但是我没有找到)
实际加速比相对于理想加速比差多少?原因是什么?
原因:
每次运行程序时,数据在CPU/GPU和内存之间的传送时间不同(依赖于当时计算机的运行情况)
GPU上进行的类多线程方式的时间开销以及写回/验证时的可能存在的写冲突