青魔法Python 读取txt文档
本文作者:魏泯
我的博客源地址:https://www.cnblogs.com/Asterism-2012/
做有效率的魔法师
我自己粘贴的代理IP保存到.txt文本文档中,准备用于测试使用。
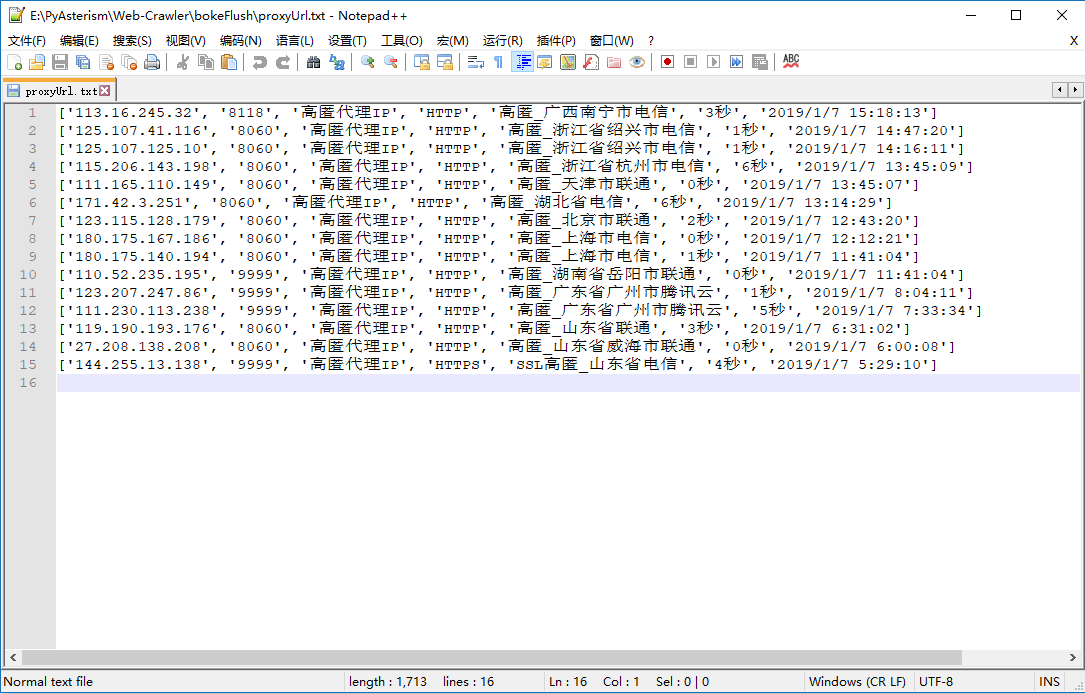
由于读取文字行的最佳方式是利用迭代器来对文件进行逐行读取,所以使用:
In [2]: f = open(r'E:\PyAsterism\Web-Crawler\bokeFlush\proxyUrl.txt')但是在进行文件操作的时候出现了编码问题:
In [3]: lines = f.readlines()
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-3-d1e99c5e7da7> in <module>()
----> 1 lines = f.readlines()
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa1 in position 80: illegal multibyte sequence判断异常信息是编码问题,可以更改一种读取方法(二进制读取rb):
f = open(r'E:\PyAsterism\Web-Crawler\bokeFlush\proxyUrl.txt','rb')
lines = f.readlines()
lines结果就变成了这样:
[b"['113.16.245.32', '8118', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb9\xbf\xe8\xa5\xbf\xe5\x8d\x97\xe5\xae\x81\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '3\xe7\xa7\x92', '2019/1/7 15:18:13']\r\n", b"['125.107.41.116', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe6\xb5\x99\xe6\xb1\x9f\xe7\x9c\x81\xe7\xbb\x8d\xe5\x85\xb4\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '1\xe7\xa7\x92', '2019/1/7 14:47:20']\r\n", b"['125.107.125.10', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe6\xb5\x99\xe6\xb1\x9f\xe7\x9c\x81\xe7\xbb\x8d\xe5\x85\xb4\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '1\xe7\xa7\x92', '2019/1/7 14:16:11']\r\n", b"['115.206.143.198', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe6\xb5\x99\xe6\xb1\x9f\xe7\x9c\x81\xe6\x9d\xad\xe5\xb7\x9e\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '6\xe7\xa7\x92', '2019/1/7 13:45:09']\r\n", b"['111.165.110.149', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xa4\xa9\xe6\xb4\xa5\xe5\xb8\x82\xe8\x81\x94\xe9\x80\x9a', '0\xe7\xa7\x92', '2019/1/7 13:45:07']\r\n", b"['171.42.3.251', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe6\xb9\x96\xe5\x8c\x97\xe7\x9c\x81\xe7\x94\xb5\xe4\xbf\xa1', '6\xe7\xa7\x92', '2019/1/7 13:14:29']\r\n", b"['123.115.128.179', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\x8c\x97\xe4\xba\xac\xe5\xb8\x82\xe8\x81\x94\xe9\x80\x9a', '2\xe7\xa7\x92', '2019/1/7 12:43:20']\r\n", b"['180.175.167.186', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe4\xb8\x8a\xe6\xb5\xb7\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '0\xe7\xa7\x92', '2019/1/7 12:12:21']\r\n", b"['180.175.140.194', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe4\xb8\x8a\xe6\xb5\xb7\xe5\xb8\x82\xe7\x94\xb5\xe4\xbf\xa1', '1\xe7\xa7\x92', '2019/1/7 11:41:04']\r\n", b"['110.52.235.195', '9999', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe6\xb9\x96\xe5\x8d\x97\xe7\x9c\x81\xe5\xb2\xb3\xe9\x98\xb3\xe5\xb8\x82\xe8\x81\x94\xe9\x80\x9a', '0\xe7\xa7\x92', '2019/1/7 11:41:04']\r\n", b"['123.207.247.86', '9999', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb9\xbf\xe4\xb8\x9c\xe7\x9c\x81\xe5\xb9\xbf\xe5\xb7\x9e\xe5\xb8\x82\xe8\x85\xbe\xe8\xae\xaf\xe4\xba\x91', '1\xe7\xa7\x92', '2019/1/7 8:04:11']\r\n", b"['111.230.113.238', '9999', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb9\xbf\xe4\xb8\x9c\xe7\x9c\x81\xe5\xb9\xbf\xe5\xb7\x9e\xe5\xb8\x82\xe8\x85\xbe\xe8\xae\xaf\xe4\xba\x91', '5\xe7\xa7\x92', '2019/1/7 7:33:34']\r\n", b"['119.190.193.176', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb1\xb1\xe4\xb8\x9c\xe7\x9c\x81\xe8\x81\x94\xe9\x80\x9a', '3\xe7\xa7\x92', '2019/1/7 6:31:02']\r\n", b"['27.208.138.208', '8060', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTP', '\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb1\xb1\xe4\xb8\x9c\xe7\x9c\x81\xe5\xa8\x81\xe6\xb5\xb7\xe5\xb8\x82\xe8\x81\x94\xe9\x80\x9a', '0\xe7\xa7\x92', '2019/1/7 6:00:08']\r\n", b"['144.255.13.138', '9999', '\xe9\xab\x98\xe5\x8c\xbf\xe4\xbb\xa3\xe7\x90\x86IP', 'HTTPS', 'SSL\xe9\xab\x98\xe5\x8c\xbf_\xe5\xb1\xb1\xe4\xb8\x9c\xe7\x9c\x81\xe7\x94\xb5\xe4\xbf\xa1', '4\xe7\xa7\x92', '2019/1/7 5:29:10']\r\n"]但是这样也是可以解决的,先说一下思路:文件为我们打印出来是列表的形式,我们可以将这些内容从列表中取出来然后进行转码。
代码:
def EncodeStr(str): # 定义一个解码的函数,接收的参数类型为str
return str.decode()
x = map(EncodeStr, lines) # 使用高阶函数map进行映射
for info in x: # 此时x是一个可迭代对象
print(info)成功!打印结果:
['113.16.245.32', '8118', '高匿代理IP', 'HTTP', '高匿_广西南宁市电信', '3秒', '2019/1/7 15:18:13']
['125.107.41.116', '8060', '高匿代理IP', 'HTTP', '高匿_浙江省绍兴市电信', '1秒', '2019/1/7 14:47:20']
['125.107.125.10', '8060', '高匿代理IP', 'HTTP', '高匿_浙江省绍兴市电信', '1秒', '2019/1/7 14:16:11']
['115.206.143.198', '8060', '高匿代理IP', 'HTTP', '高匿_浙江省杭州市电信', '6秒', '2019/1/7 13:45:09']
['111.165.110.149', '8060', '高匿代理IP', 'HTTP', '高匿_天津市联通', '0秒', '2019/1/7 13:45:07']
['171.42.3.251', '8060', '高匿代理IP', 'HTTP', '高匿_湖北省电信', '6秒', '2019/1/7 13:14:29']
['123.115.128.179', '8060', '高匿代理IP', 'HTTP', '高匿_北京市联通', '2秒', '2019/1/7 12:43:20']
['180.175.167.186', '8060', '高匿代理IP', 'HTTP', '高匿_上海市电信', '0秒', '2019/1/7 12:12:21']
['180.175.140.194', '8060', '高匿代理IP', 'HTTP', '高匿_上海市电信', '1秒', '2019/1/7 11:41:04']
['110.52.235.195', '9999', '高匿代理IP', 'HTTP', '高匿_湖南省岳阳市联通', '0秒', '2019/1/7 11:41:04']
['123.207.247.86', '9999', '高匿代理IP', 'HTTP', '高匿_广东省广州市腾讯云', '1秒', '2019/1/7 8:04:11']
['111.230.113.238', '9999', '高匿代理IP', 'HTTP', '高匿_广东省广州市腾讯云', '5秒', '2019/1/7 7:33:34']
['119.190.193.176', '8060', '高匿代理IP', 'HTTP', '高匿_山东省联通', '3秒', '2019/1/7 6:31:02']
['27.208.138.208', '8060', '高匿代理IP', 'HTTP', '高匿_山东省威海市联通', '0秒', '2019/1/7 6:00:08']
['144.255.13.138', '9999', '高匿代理IP', 'HTTPS', 'SSL高匿_山东省电信', '4秒', '2019/1/7 5:29:10']