Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage,划分stage的依据就是RDD之间的宽窄依赖。遇到宽依赖就划分stage,每个stage包含一个或多个task任务。然后将这些task以taskSet的形式提交给TaskScheduler运行。
stage是由一组并行的task组成。
stage切割规则
切割规则:从后往前,遇到宽依赖就切割stage。
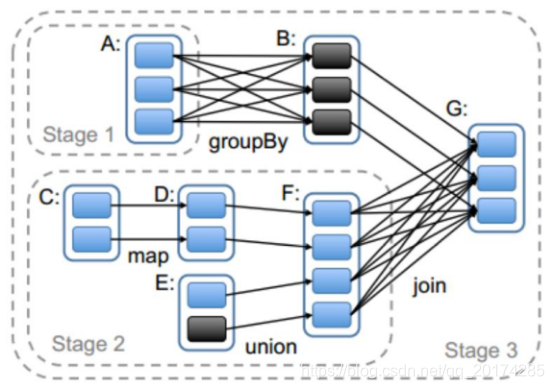
stage计算模式
pipeline管道计算模式,pipeline只是一种计算思想,模式。
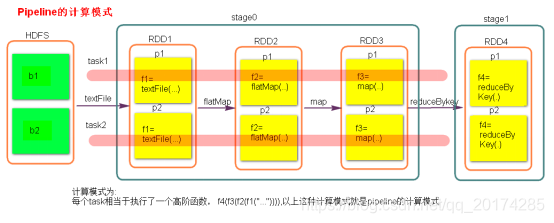
数据一直在管道里面什么时候数据会落地?
1.对RDD进行持久化。
2.shuffle write的时候。
Stage的task并行度是由stage的最后一个RDD的分区数来决定的 。
如何改变RDD的分区数?
例如:reduceByKey(XXX,3),GroupByKey(4)
测试验证pipeline计算模式
val conf = new SparkConf()
conf.setMaster(“local”).setAppName(“pipeline”);
val sc = new SparkContext(conf)
val rdd = sc.parallelize(Array(1,2,3,4))
val rdd1 = rdd.map { x => {
println(“map--------”+x)
x
}}
val rdd2 = rdd1.filter { x => {
println(“fliter********”+x)
true
} }
rdd2.collect()
sc.stop()
Stage
猜你喜欢
转载自blog.csdn.net/qq_20174285/article/details/85996591
今日推荐
周排行