机器学习的算法经常会涉及到在非常多的随机变量上的概率分布。通常,这些概率分布涉及到的直接相互作用都是介于非常少的变量之间的。使用单个函数来描述整个联合概率分布是非常低效的 (无论是计算上还是统计上)。
我们可以把概率分布分解成许多因子的乘积形式,而不是使用单一的函数来表示概率分布。例如,假设我们有三个随机变量 a, b 和 c,并且 a 影响 b 的取值,b 影响 c 的取值,但是 a 和 c 在给定 b 时是条件独立的。我们可以把全部三个变量的概率分布重新表示为两个变量的概率分布的连乘形式:
![]()
这种分解可以极大地减少用来描述一个分布的参数数量。每个因子使用的参数数目是它的变量数目的指数倍。这意味着,如果我们能够找到一种使每个因子分布具有更少变量的分解方法,我们就能极大地降低表示联合分布的成本。
我们可以用图来描述这种分解。这里我们使用的是图论中的 ‘‘图’’ 的概念:由 一些可以通过边互相连接的顶点的集合构成。当我们用图来表示这种概率分布的分 解,我们把它称为 结构化概率模型(structured probabilistic model)或者 图模型(graphical model)。
有两种主要的结构化概率模型:有向的和无向的。两种图模型都使用图 G,其中图的每个节点对应着一个随机变量,连接两个随机变量的边意味着概率分布可以表示成这两个随机变量之间的直接作用。
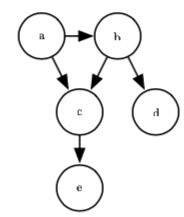
上图是关于随机变量 a, b, c, d 和 e 的有向图模型。该图模型使我们能够快速看出此分布的一些性质。例如,a 和 c 直接相互影响,但 a 和 e 只有通 过 c 间接相互影响。这幅图对应的概率分布可以分解为:
![]()
无向(undirected)模型使用带有无向边的图,它们将分解表示成一组函数;不 像有向模型那样,这些函数通常不是任何类型的概率分布。G 中任何满足两两之间有边连接的顶点的集合被称为团。无向模型中的每个团 C(i) 都伴随着一个因子 φ(i)(C(i))。这些因子仅仅是函数,并不是概率分布。每个因子的输出都必须是非负的,但是并没有像概率分布中那样要求因子的和或者积分为 1。
随机变量的联合概率与所有这些因子的乘积 成比例(proportional)——意味着 因子的值越大则可能性越大。当然,不能保证这种乘积的求和为 1。所以我们需要除 以一个归一化常数 Z 来得到归一化的概率分布,归一化常数 Z 被定义为 φ 函数乘 积的所有状态的求和或积分。概率分布为:
![]()

上图是关于随机变量 a, b, c, d 和 e 的无向图模型。该图模型使我们能够快速看出此分布的一些性质。例如,a 和 c 直接相互影响,但 a 和 e 只有通 过 c 间接相互影响。这幅图对应的概率分布可以分解为:
![]()