每一个系统都拥有很多概念,这些概念是作者在设计与实现时为不同的模块或功能做的定义。概念本身只是一个名词,往往会跟随作者的喜好不同而不同,重要的是理解其设计的初衷以及要表达的实际内容,否则很快就会忘记其意义。作为专栏文章的第二篇,本文将从多个方面对Elasticsearch的核心概念进行整理,尽可能由浅入深的交代清楚每个概念,而相关的使用技巧会在后续博文中介绍。本文写作背景是Elasticsearch 5.5。
为了方便查阅,这里首先列出会涉及到的概念,读者可以根据需要选择性阅读。

1. 数据组织
1.1 逻辑组织
假设我们在一个业务系统中选择MySQL做数据存储,那么我们需要先创建一个database,再创建一组相关的table。几乎所有的数据存储系统都有类似的设计,这样做的一个基本目的在于对数据进行抽象分类,将描述同种特性的数据放在一起,可以更好的做压缩存储、查询优化等。另一方面,通过这样在逻辑层面对数据进行组织后,可以屏蔽底层的具体细节,方便在应用程序中进行操作。
Elasticsearch同样具有这样的概念,如下图所示,使用index和doc_type来组织数据。doc_type中的每条数据称为一个document,是一个JSON Object,相关的schema信息通过mapping来定义。mapping不仅仅包括数据类型的定义,还有很多其他元信息的设置,它们共同决定了数据如何被存储和索引。这四个概念实现了Elasticsearch的逻辑数据组织,假设有一批结构化或半结构化数据需要存储,我们会先对数据进行分类,设计相应的index与doc_type,再为每个doc_type设置相关的mapping信息。如果不指定mapping,Elasticsearch会使用默认值,并自动为你推导每个字段的类型,即支持schema free的特性。但是,这种灵活性也会带来一些问题,一方面会失去对数据的控制,即会越来越不清楚你的数据结构,另一方面,自动推导出来数据类型可能不是预期的,会带来写入和查询问题。所以,笔者建议,尽最大可能对schema加以约束。

通常情况下,我们都会拿Elasticsearch的这些概念跟关系型数据库对比来更好的理解,比如index等价于database,doc_type等价于table,mapping等价于db schema。但是,需要注意的是,对于关系型数据库而言,table与table之间是完全独立的,不同table的schema是完全隔离的,而Elasticsearch中的doc_type则不是。同一个index下不同doc_type中的字段在底层是合并在一起存储的,意味着假设两个doc_type中都有一个叫name的字段,那么这两个字段的mapping必须一样。基于这个原因,Elasticsearch官方从6.0开始淡化doc_type的概念,推荐一个index只拥有一个doc_type,并计划在8.x完全废弃doc_type。因此,在当前的index设计中,最好能遵循这个规则。
1.2 物理组织
Elasticsearch是一个分布式系统,其数据会分散存储到不同的节点上。为了实现这一点,需要将每个index中的数据划分到不同的块中,然后将这些数据块分配到不同的节点上存储。这里的数据块,就是shard。通过"分"的思想,可以突破单机在存储空间和处理性能上的限制,这是分布式系统的核心目的。而对于分布式存储而已,还有一个重要特性是"冗余",因为分布式的前提是:接受系统中某个节点因为某些故障退出。为了保证在故障节点退出后数据不丢失,同一份数据需要拷贝多份存在不同节点上。因此,shard从角色上划分为primary shard和replica shard两种,数据会首先写入primary shard,然后同步到replica shard中。
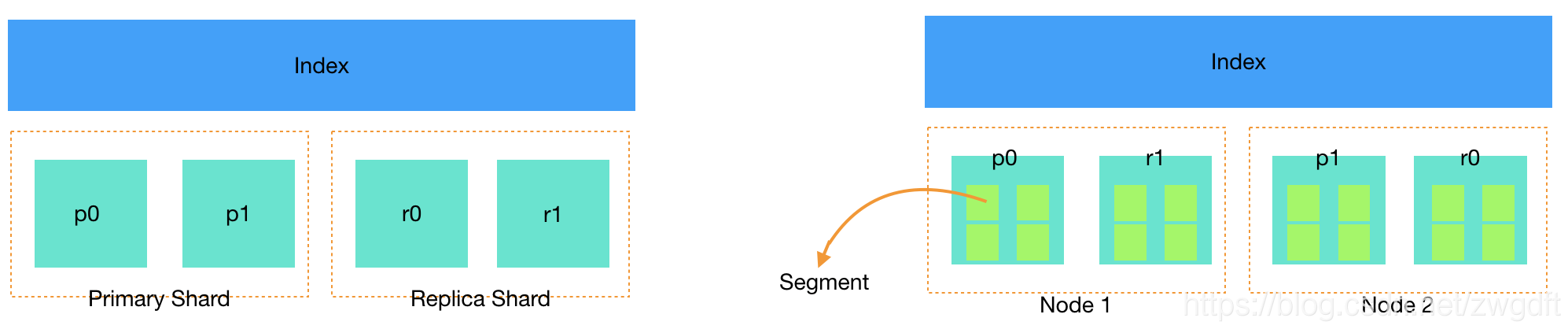
shard是Elasticsearch中最小的数据分配单位,即一个shard总是作为一个整体被分配到某个节点,而不会只分配其中一部分。那么,shard中的数据又是如何组织的?答案是segment。一个shard包含一组segment,segment是最小的数据单元,Elasticsearch每隔一段时间产生一个新的segment,里面包含了新写入的数据。segment是immutable的,即不可改变,这样设计的考量是:一方面,不支持修改就不用对读写操作加锁,省去了相关开销;另一方面,因为文件内容不会修改,可以更好的利用filesystem cache进行缓存,提高查询性能。但是,任何设计都不是完美的,伴随而来的问题是:如果segment不可修改,怎么实现数据的更新与删除呢?这个问题将在下面“数据写入”一节介绍。
2. 数据分布
上面提到,Elasticsearch将每个index中的数据划分到不同的shard中,然后将shard分配到不同的节点上,实现分布式存储。这里面涉及到两个概念:一个是数据到shard的映射(route),另一个是shard到节点的映射(shard allocate)。
一方面,插入一条数据时,Elasticsearch会根据指定的key来计算应该落到哪个shard上。默认key是自动分配的id,可以自定义,比如在我们的业务中采用CompanyID作为key。因为primary shard的个数是不允许改变的,所以同一个key每次算出来的shard是一样的,从而保证了准确定位。
shard_num = hash(_routing) % num_primary_shards
另一方面,master节点会为每个shard分配相应的data节点进行存储,并维护相关元信息。通过route计算出来的shard序号,在元信息中找到对应的存储节点,便可完成数据分布。shard allocate的映射关系并不是完全不变的,当检测到数据分布不均匀、有新节点加入或者有节点挂掉等情况时就会进行调整,称为relocate。
关于数据分布,可以参考阅读博文《谈Elasticsearch下分布式存储的数据分布》。

3. 集群角色
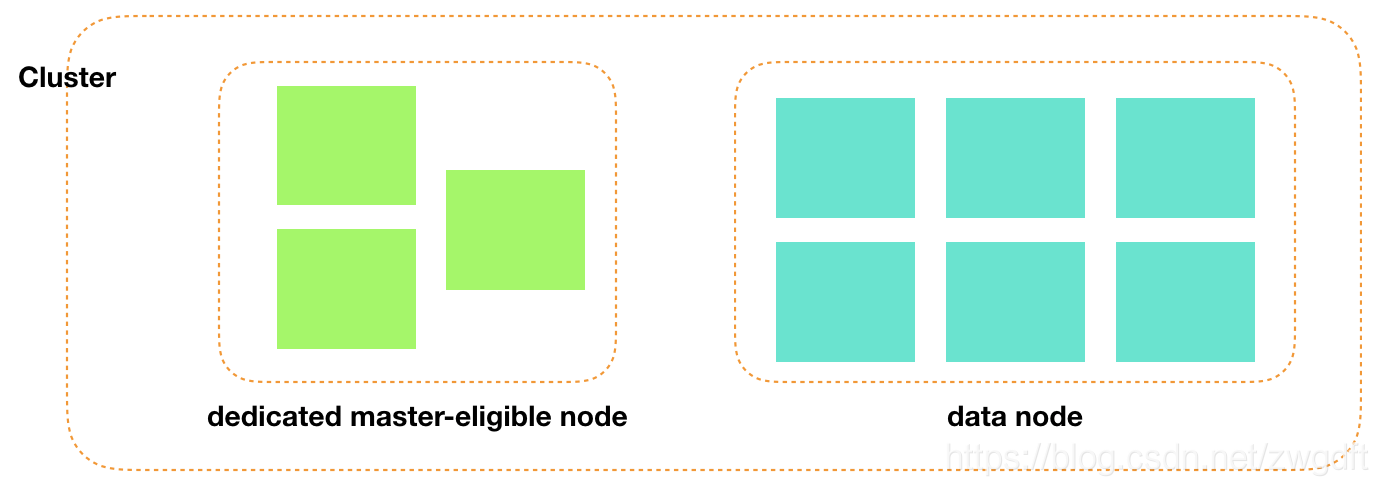
一个分布式系统,是由多个节点各司其职、相互协作完成整体服务的,从架构上可以分为有中心管理节点和无中心管理节点两种,Elasticsearch属于前者。中心管理节点负责维护整个系统的状态和元信息,为了保证高可用性,通常是从一组候选节点中选举出来的,而非直接指定。按照职责,Elasticsearch将节点分为三种:master-eligible节点、data节点、ingest节点。master-eligible节点就是中心节点的候选人,通过选举算法从这些候选人中推选出大家公认的中心节点。data节点负责数据存储、查询,也是整个系统中负载最重的部分。ingest节点是针对Elasticsearch一个特定功能而设定的,Elasticsearch支持在数据写入前对数据进行相关的转换、处理,而这类节点就是负责这样的工作,从笔者遇到的实践来看,使用这类节点的并不多。
这三种角色是通过配置来设定的,可以同时设置到同一个节点上,即一个节点可以同时具备这三种功能。但是这种做法只适用于数据量小、业务较轻的场景,因为不同角色承担的功能所带来的负载是不同的,很可能因为数据写入/查询负载较重导致master节点通信受到影响,从而导致系统不稳定。所以,推荐将不同角色分离开,某个节点只负责其中一个功能,通常会设置dedicated master-eligible节点、data/ingest节点。前者负载很轻,只需要分配较低配置的机器,而后者对CPU、IO、Memory要求较高,需要配置更好的机器,实践中根据性能测试结果来调整。
前面提到,中心节点(master)是从一组候选人(master-eligible)中选举出来的,那设置多少个候选人是合理的?原则是要保证任何时候系统只有一个确定的master节点。考虑到一致性,只有被半数以上候选节点都认可的节点才能成为master节点,否则就会出现多主的情况。只有1个候选节点显然不能保证高可用;有2个时,半数以上(n/2+1)的个数也是2,任何一个出现故障就无法继续工作了;有3个时,半数以上的值仍然是2,恰好可以保证master故障或网络故障时系统可以继续工作。因此,3个dedicated master-eligible节点是最小配置,也是目前业界标配。
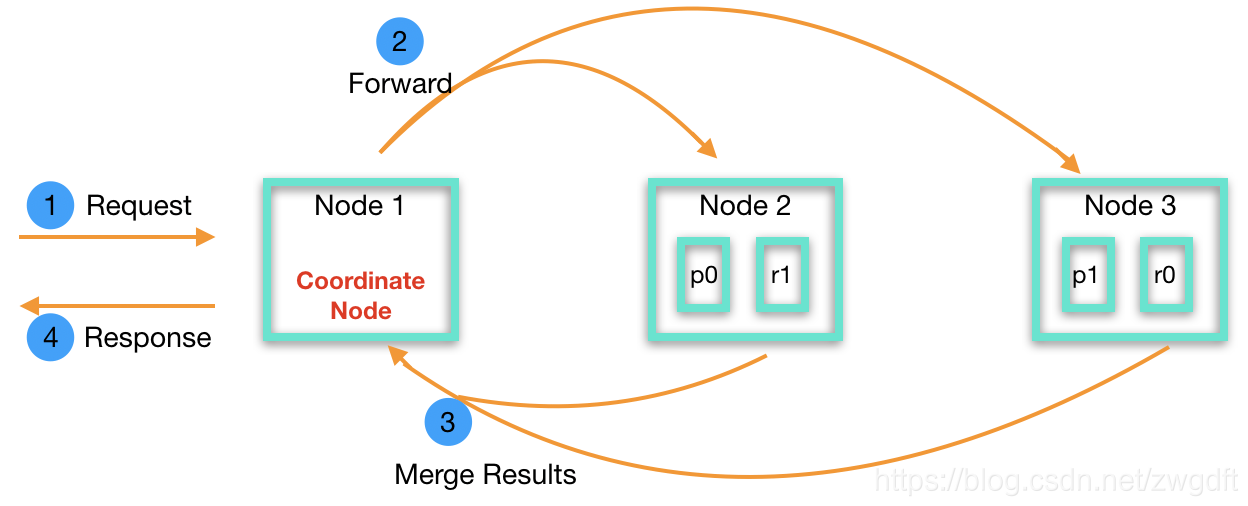
Elasticsearch以REST API形式对外提供服务,数据写入与查询都会发送HTTP(S)请求到服务端,由负载均衡将请求分发到集群中的某个节点上(任何非dedicated master-eligible节点)。如下图所示,节点1收到请求后,会根据相关的元信息将请求分发到shard所在的节点(2和3)上进行处理,处理完成后,节点2和3会将结果返回给节点1,由节点1合并整理后返回给客户端。这里的节点1扮演着协调者的角色,称为coordinate节点,任何节点在收到请求后就开始发挥协调者的角色,直到请求结束。在实际使用中,可以根据需要增加一些专用的coordinate节点,用于性能调优。
4. 数据写入
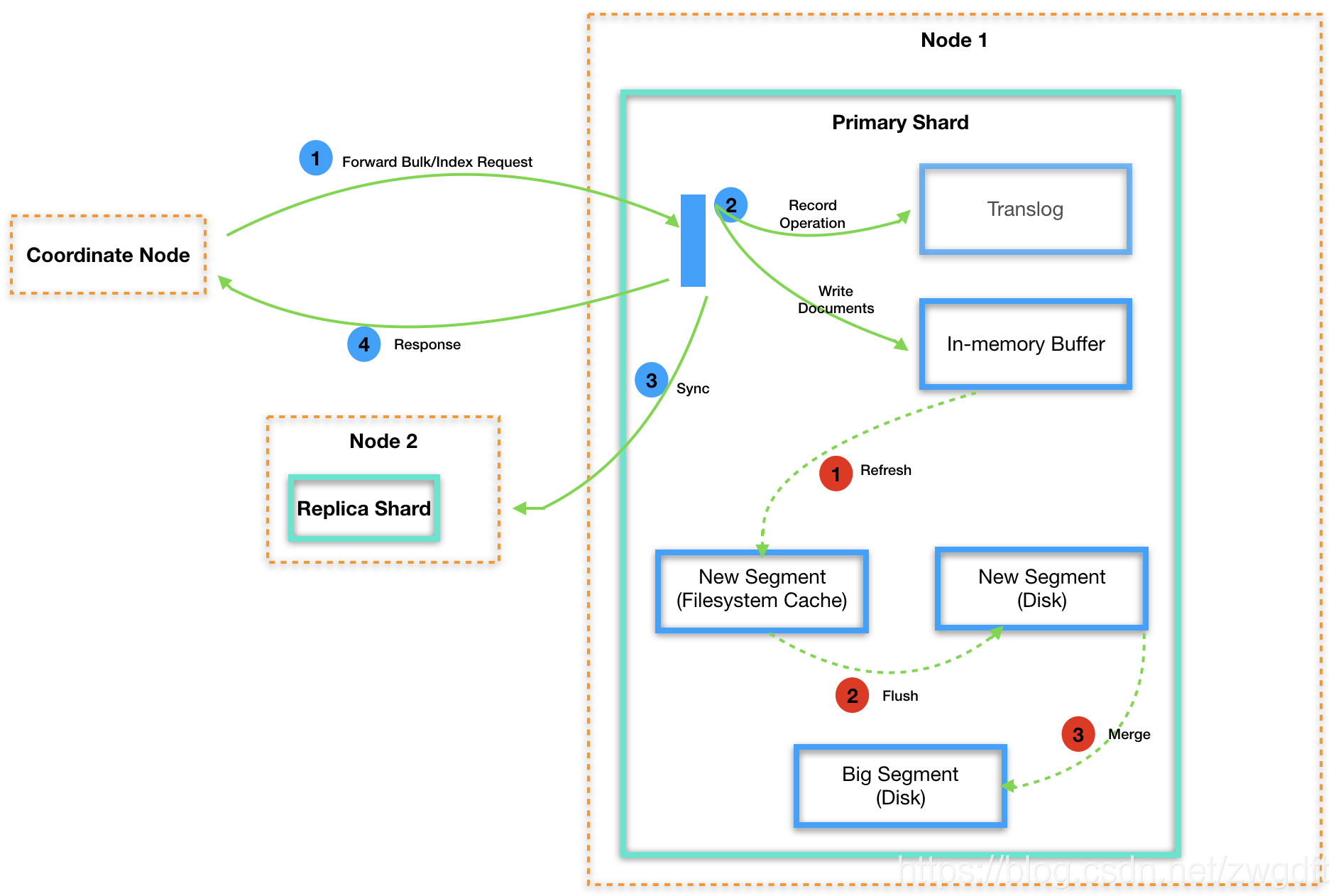
通过上面的整理,我们知道,当有数据写入时,请求会先到达集群中的某个节点上,由该节点根据routing信息和元信息将相应的数据分发到对应的shard所在的节点上,可能是一个也可能是多个节点,取决于写入的数据。这些节点在收到分发出来的请求后,会经过一系列过程,最终将数据以segment的形式落地到磁盘上,这些过程就是本节要聊的内容,其包含同步与异步两个过程,如下图所示。
同步过程:
同步过程是指在请求返回前做的事情,即包含在一个HTTP请求的过程中,客户端需要等其做完才能拿到结果。简单来看,这个过程需要完成三件事:第一,将操作记录写入到translog中,我们后面再来谈它的作用;第二,根据数据生成相应的数据结构,并写入到in-memory buffer,注意是写入到一个内存buffer中,不是磁盘;第三,将数据同步到所有primary shard中。完成这些之后,就会生成相应的结果返回给coordinate节点了。
异步过程:
我们知道,写磁盘很慢,且非常耗费CPU与IO,在同步过程中,为了让请求尽快返回,并没有将数据直接落盘。Elasticsearch的最小数据单元是segment,而此时数据还在in-memory buffer中,因此这部分数据是不能被查询请求访问到的。只有当发生refresh动作,才会产生一个新的segment,将内存buffer中的数据写入到里面,同时清空buffer。默认refresh的时间间隔是1秒,可以配置,需要在实时性与性能之间进行权衡。
此时虽然已经生成了新的segment文件,但是只是停留在filesystem cache中,并没有真正的落到磁盘中。这些动作的目的都是为了将“写磁盘”这件事尽可能的延后并变得低频,但是数据一直留在内存中始终是不安全的,很容易因为断电等原因导致数据丢失,因此每隔一段时间,Elasticsearch会真正做一次磁盘flush,完成数据的持久化。
从写入请求过来到数据最终落盘,中间很长一段时间数据是停留在内存中的,那么如果在此期间机器断电岂不是会丢失数据?为了解决这个问题,就要用到上面所述的translog了。在请求返回前,必须要将操作记录写入到translog中并落盘,保证机器重启后可以恢复数据。显然这件事本身是会消耗性能的,但这也是保证数据不丢失的一个牺牲了,必须要做的。
segment是由refresh动作产生的,因此随着时间推移,会产生很多小segment,而每个segment都需要占用一定的资源,比如文件句柄、缓存等等,过多的segment势必会导致性能下降。因此每隔一段时间,Elasticsearch会做一次segment merge,将多个小的segment合并成一个大的segment。
最后再来看下前面提到的一个问题:因为segment是不可改变的,如何实现数据更新与删除?以删除为例,Elasticsearch将要删除的数据记录到一个叫.del文件中,每次查询时会将匹配到的数据跟这个文件中的数据做一次对比,去掉被删除的数据。直到segment merge时,会将.del文件和相应的segment文件一起加载进行合并,这时才真正删除了数据。
5. 存储结构
在讲存储结构之前,先来看看两种常见的查询需求(以一组博文信息数据为例,有作者、标题等信息)。一种是精确匹配,比如查找作者姓名为"Bruce"的信息;另一种是全文检索,比如从1000个文章的标题中搜索出包含"分布式"的文章。对于第一个需求,我们只需要将每个名字作为一个term即可,“是"或"不是”;对于第二个,我们如果想知道标题中是否包含"分布式",就需要提前将每个标题分解为多个term,比如"浅谈分布式存储系统",可能会产生"浅谈"、“分布式”、“存储”、"系统"等多个term,具体取决于使用了哪一种分析器。
不管哪种情况,最后都是产生一组term,问题是用一个什么样的存储结构可以实现快速检索。这就是Elasticsearch的核心:inverted index。inverted index是一个二维结构,如下所示,包含一组排好序的term,每个term都关联有一些信息,这些信息指出哪些document包含了这个term。当需要查询包含关键词"分布式"的数据时,系统会先从inverted index中找出对应的term,获取到其对应的document id,然后就可以根据document id找出其信息了。
sample data:
1. {"author": "Bruce", "title": "浅谈分布式存储系统"}
2. {"author": "Bruce", "title": "常见的分布式系统"}
3. {"author": "David", "title": "分布式存储原理"}
inverted index for field "author":
-------------------------------
term | doc id
-------------------------------
Bruce | 1, 2
David | 3
-------------------------------
inverted index for field "title":
-------------------------------
term | doc id
-------------------------------
常见 | 3
存储 | 1, 3
分布式 | 1, 2, 3
浅谈 | 1
系统 | 1, 2
原理 | 3
-------------------------------
通过inverted index,我们可以根据关键词快速搜索出相关的document,除了这种查询,还有一种常见的需求是求聚合,即关系型数据库中的GROUP BY功能。比如查看写"分布式"相关的文章最多的10位作者,首先根据上述方法通过inverted index找到与"分布式"相关的所有document,然后需要对这些document的作者进行归类并计数,最后再排序取出TOP10。在"归类"时,我们需要知道每个document的作者名字,但是通过inverted index是无法直接查找到的,因为他是term-to-doc_id形式的,而我们这里需要的是doc_id-to-term形式的数据,只有通过循环迭代才能知道某个document的作者姓名是什么,这样做的效率无疑是很低的。
为了解决聚合的效率问题,Elasticsearch建立了一个与inverted index反向的数据结构:doc values,如下所示。
-------------------------------
doc id | terms
-------------------------------
1 | Bruce
2 | Bruce
3 | David
-------------------------------
inverted index和doc values都是在数据写入时建立的,即上述的同步过程第二步中完成的。他们都是针对per segment而言的,数据最终以文件的形式存储,并且是immutable的。数据查询时,如果每次都去读取磁盘文件,其效率显然是无法接受的,Elasticsearch将这些文件内容映射到内存中,通过充分利用文件系统缓存来提高查询性能,因此在实践中建议保留足够的memory给系统。
以上便是笔者认为使用Elasticsearch过程中应该掌握的核心概念与原理,这些知识点对使用和理解实践中Elasticsearch表现出来的行为有很大的帮助。当然,并不意味着必须要从一开始就完全掌握,任何认知都是需要伴随实践来提高的。另外,在本文的描述中,笔者淡化了Elasticsearch与Lucene的关系,其实有不少概念是Lucene里面的,而Elasticsearch是在Lucene的基础上开发的,淡化的原因是笔者认为没有必要刻意去区分这二者,除非你想深入研究源码。当然,概念远不止这些,读者也可以参考阅读笔者的其他博文。
(全文完,本文地址:https://blog.csdn.net/zwgdft/article/details/83619905 )
(版权声明:本人拒绝不规范转载,所有转载需征得本人同意,并且不得更改文字与图片内容。大家相互尊重,谢谢!)
Bruce
2018/12/03 晚