一、硬件配置以及操作系统:
所需要的机器以及操作系统:一台mac os笔记本、一台window笔记本(CPU双核四线程,内存8G),其中mac os用于远程操作,window笔记本装有虚拟机,虚拟出3个ubuntu18.04系统(配置CPU1个线程2个,内存1.5G,硬盘分配每个70G),对于mac os(可以用window机或者linux机)的配置没有要求
- 使用vm创建3个ubuntu18.04系统,一个主节点:master(NameNode)和两个从节点slave1(DataNode)和slave2(DataNode)
- 节点IP分配:主节点IP为:192.168.0.109、从节点1IP为:192.168.0.110、从节点2IP为:192.168.0.111
- 虚拟机的网络选择桥接模式与物理网络的网段相同,这样有助于远程连接。
- master的主机名为:sunxj-hdm,slave1的主机名为:sunxj-hds1,slave2的主机名为:sunxj-hds2,如下图所示:



- 定义域名:sunxj-hdm.myhd.com(master),sunxj-hds1.myhd.com(slave1),sunxj-hds2.myhd.com(slave2)
- 配置hosts,将3台的hosts配置为:
192.168.0.109 sunxj-hdm.myhd.com
192.168.0.110 sunxj-hds1.myhd.com
192.168.0.111 sunxj-hds2.myhd.com如下图所示:
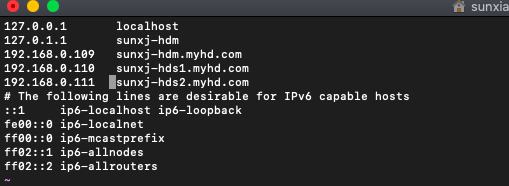
注意:不能放在最下边,从注释行开始往下是配置ipv6的,ip和域名之间必须是一个tab,且域名后不能有空格,否则是ping不通的,还有3个主机必须配置相同才能互ping。
7.然后使用如下命令进行重启网络
sudo /etc/init.d/networking restart如下图所示:
![]()
8、然后通过ping sunxj-hds1.myhd.com查看是否可以ping的通,如果是通的则配置成功,如果不通需要在找原因了,如下图所示:
在master机ping slave1和slave2

在 slave1机ping master和slave2

在 slave2机ping master和slave1

二、节点需要安装的工具:
三个节点需要安装的工具为:vm-tool、gcc、net-tools、openssh-server、vsftpd、vim(用于ftp服务)
安装顺序:
(1)sudo apt install gcc
(2) 安装vm-tool
(3)sudo apt install net-tools
(4)sudo apt install vim
(5)sudo apt install openssh-server(可以使用/etc/init.d/ssh start 启动ssh)
(6)在安装好ssh后即可远程操作,在macos中打开终端进行ssh远程连接,如下图所示:

(7)安装ftp服务并配置vsftpd请看:https://blog.csdn.net/sunxiaoju/article/details/85224602
三、安装JDK环境
1、安装java,三台主机都需要安装,安装方法请看:https://blog.csdn.net/sunxiaoju/article/details/51994559
四、创建hadoop用户
1、在master节点上使用如下命令来创建hadoop用户
sudo adduser hadoop如下图所示:

2、使用如命令把hadoop用户加入到hadoop用户组,前面一个hadoop是组名,后面一个hadoop是用户名
sudo usermod -a -G hadoop hadoop如下图所示:
![]()
3、可以使用如下命令来查看结果
cat /etc/group |grep hadoop如下图所示:
![]()
4、把hadoop用户赋予root权限,让他可以使用sudo命令,使用如下命令编辑
sudo vim /etc/sudoers修改文件如下:
root ALL=(ALL) ALL
hadoop ALL=(root) NOPASSWD:ALL如下图所示:
修改前:

修改后:

5、用同样方法在slave1和slave2上创建hadoop用户。
五、建立ssh无密码登录本机
ssh生成密钥有rsa和dsa两种生成方式,默认情况下采用rsa方式。
1、首先用hadoop用户在master主机上创建ssh-key,这里我们采用rsa方式。使用如下命令(P是要大写的,后面跟"",表示无密码)
ssh-keygen -t rsa -P ""如下图所示:
![]()
2、直接回车即可,然后就会生成相应的信息,如下图所示:

3、回车后会在~/.ssh/下生成两个文件:id_rsa和id_rsa.pub这两个文件是成对出现的,进入到该目录查看,如下图所示:
![]()
4、然后分别在slave1和slave2用同样的方法生成,然后分别用
scp id_rsa.pub [email protected]:/home/sunftp/ftpdir/slave1_id_rsa.pub
scp id_rsa.pub [email protected]:/home/sunftp/ftpdir/slave2_id_rsa.pub将slave1和slave2的文件上传到master上,如下图所示:


5、使用如下指令,将上传到master上的slave1_id_rsa.pub和slave2_id_rsa.pub文件移动到~/.ssh/目录
sudo mv /home/sunftp/ftpdir/slave1_id_rsa.pub slave1_id_rsa.pub
sudo mv /home/sunftp/ftpdir/slave2_id_rsa.pub slave2_id_rsa.pub如下图所示:

6、将id_rsa.pub、slave1_id_rsa.pub、slave2_id_rsa.pub追加到authorized_keys授权文件中,开始是没有authorized_keys文件的,只需要执行如下命令即可:
cat *.pub >>authorized_keys如下图所示:

7、然后可以通过:ssh localhost测试本机无密码登录,如下图所示:

8、将master上的公钥拷贝到slave1和slave2上,使其master无密码登录slave1和slave2,首先将authorized_keys文件通过scp上传到slave1和slave2的/home/sunftp/ftpdir/目录中,使用如下命令来上传
scp authorized_keys [email protected]:/home/sunftp/ftpdir
scp authorized_keys [email protected]:/home/sunftp/ftpdir,如下图所示:

9、此时在slave1和slave2上的/home/sunftp/ftpdir/目录中存在authorized_keys文件文件,如下图所示:
![]()
![]()
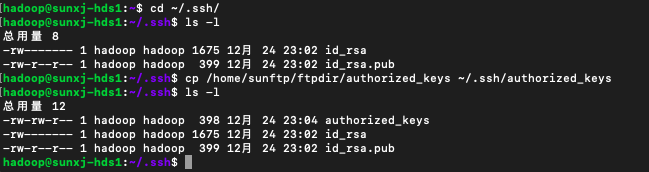
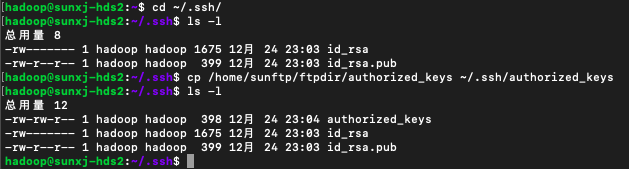
10、分别在两台slave机器上执行1~3部,然后如下命令将公钥拷贝到~/.ssh/目录中
cp /home/sunftp/ftpdir/authorized_keys ~/.ssh/authorized_keys如下图所示:
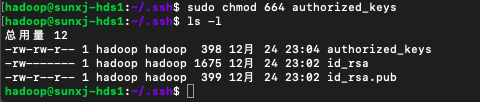
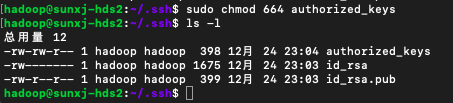
11、使用:sudo chmod 664 authorized_keys 修改authorized_keys的权限,如下图所示:
12、然后在mstar上无密码登录slave1和slave2,如下图所示:


13、然后在slave1上无密码登录mstar和slave2,如下图所示:


14、然后在slave2上无密码登录slave1和mstar,如下图所示:


注意:如果无法登录请查看/home/下的用户权限是否是755,如果不是则无法登录的,我的slave1就是将/home/sunxj的权限设置为:777,只需要将sunxj设置为755即可,如下图所示:


12、到此就可以在master上无密码登录slave1和slave2了。
六、安装hadoop
1、首先从https://hadoop.apache.org/releases.html下载,如下版本:

2、这里选择hadoop2.7.7的Binary版本。
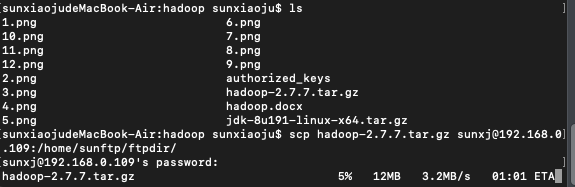
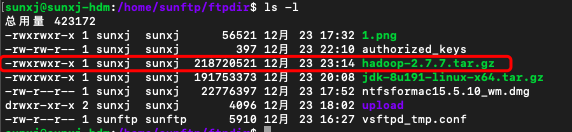
3、使用scp命令将下载好的hadoop上传到master,(此时的用户名也可以使用其他的用户配置)如下图所示:
4、使用如下命令解压
tar -xzvf hadoop-2.7.7.tar.gz将hadoop-2.7.7.tar.gz如下图所示:

5、将hadoop-2.7.7移动到/usr/目录,如下图所示:

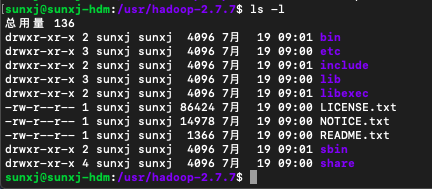
6、查看hadoop的目录,如下图所示:
7、在hadoop-2.7.7目录中一个hdfs目录和三个子目录,如
- hadoop-2.7.3/hdfs
- hadoop-2.7.3/hdfs/tmp
- hadoop-2.7.3/hdfs/name
- hadoop-2.7.3/hdfs/data

8、在hadoop-2.7.7/etc/目录中查看需要配置的文件有:
- core-site.xml
- hadoop-env.sh
- hdfs-site.xml
- mapred-site.xml.template
- yarn-env.sh
- yarn-site.xml
- mapred-env.sh
- slaves
如下图所示:

9、首先配置core-site.xml文件,使用如下命令打开
sudo vim etc/hadoop/core-site.xml然后在<configuration></configuration>中如下配置是读写sequence file 的 buffer size,可减少 I/O 次数。在大型的 Hadoop cluster,建议可设定为 65536 到 131072,默认值 4096.按照教程配置了131072:
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://sunxj-hdm.myhd.com:9000</value>
</property>
注意:第一个属性中的value和我们之前创建的/usr/hadoop-2.7.7/hdfs/tmp路径要一致。
如下图所示:

属性说明:
| 参数 | 属性值 | 解释 |
| fs.defaultFS | NameNode URI | hdfs://host:port/ |
| io.file.buffer.size | 131072 | SequenceFiles文件中.读写缓存size设定 |
fs.defaultFS //为masterIP地址,其实也可以使用主机名或者域名,这个属性用来指定namenode的hdfs协议的文件系统通信地址,可以指定一个主机+端口,也可以指定为一个namenode服务(这个服务内部可以有多台namenode实现ha的namenode服务)
o.file.buffer.size //该属性值单位为KB,131072KB即为默认的64M,这个属性用来执行文件IO缓冲区的大小
hadoop.tmp.dir //指定hadoop临时目录,前面用file:表示是本地目录。有的教程上直接使用/usr/local,我估计不加file:应该也可以。hadoop在运行过程中肯定会有临时文件或缓冲之类的,必然需要一个临时目录来存放,这里就是指定这个的。当然这个目录前面我们已经创建好了。<!-- 也有人使用zookeeper,因此,需要在hadoop核心配置文件core-site.xml中加入zookeeper的配置:-->
<!-- 指定zookeeper地址 。zookeeper可以感知datanode工作状态,并且提供一些高可用性的特性。暂时不了解zookeeper,后续再说。先不加入这个配置了暂时。-->
<property>
<name>ha.zookeeper.quorum</name>
<value>dellserver01:2181,dellserver02:2181,dellserver03:2181,dellserver04:2181,dellserver05:2181</value>
</property>10、配置 hadoop-env.sh文件,用于配置jdk目录,使用如下命令打开
sudo vim etc/hadoop/hadoop-env.sh然后将export JAVA_HOME=${JAVA_HOME}注释掉配置成具体的路径:export JAVA_HOME=/usr/jdk1.8.0_191,否则在运行时会提示找不到JAVA_HOME,如下图所示:

11、在mapred-env.sh加入JAVA_HOME,如下图所示:

12、在yarn-env.sh加入JAVA_HOME,如下图所示:

13、配置hdfs-site.xml,使用如下命令打开文件
sudo vim etc/hadoop/hdfs-site.xml然后在<configuration></configuration>中加入以下代码:
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/hadoop-2.7.7/hdfs/data</value>
<final>true</final>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>sunxj-hdm.myhd.com:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>注意:其中第二个dfs.namenode.name.dir和dfs.datanode.data.dir的value和之前创建的/hdfs/name和/hdfs/data路径一致;由于有两个从主机slave1、slave2,所以dfs.replication设置为2
如下图所示:

属性说明:
- 配置NameNode
| 参数 | 属性值 | 解释 |
| dfs.namenode.name.dir | 在本地文件系统所在的NameNode的存储空间和持续化处理日志 | 如果这是一个以逗号分隔的目录列表,然 后将名称表被复制的所有目录,以备不时 需。 |
| dfs.namenode.hosts/ dfs.namenode.hosts.exclude |
Datanodes permitted/excluded列表 | 如有必要,可以使用这些文件来控制允许 数据节点的列表 |
| dfs.blocksize | 268435456 | 大型的文件系统HDFS块大小为256MB |
| dfs.namenode.handler.count | 100 | 设置更多的namenode线程,处理从 datanode发出的大量RPC请求 |
- 配置DataNode
| 参数 | 属性值 | 解释 |
| dfs.datanode.data.dir | 逗号分隔的一个DataNode上,它应该保存它的块的本地文件系统的路径列表 | 如果这是一个以逗号分隔的目录列表,那么数据将被存储在所有命名的目录,通常在不同的设备。 |
14、复制mapred-site.xml.template文件,并命名为mapred-site.xml,使用如下命令拷贝
cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml并编辑mapred-site.xml,在标签<configuration>中添加以下代码:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>sunxj-hdm.myhd.com:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>sunxj-hdm.myhd.com:19888</value>
</property>
如下图所示:

属性说明:
| 参数 | 属性值 | 解释 |
| mapreduce.framework.name | yarn | 执行框架设置为 Hadoop YARN. |
| mapreduce.map.memory.mb | 1536 | 对maps更大的资源限制的. |
| mapreduce.map.java.opts | -Xmx2014M | maps中对jvm child设置更大的堆大小 |
| mapreduce.reduce.memory.mb | 3072 | 设置 reduces对于较大的资源限制 |
| mapreduce.reduce.java.opts | -Xmx2560M | reduces对 jvm child设置更大的堆大小 |
| mapreduce.task.io.sort.mb | 512 | 更高的内存限制,而对数据进行排序的效率 |
| mapreduce.task.io.sort.factor | 100 | 在文件排序中更多的流合并为一次 |
| mapreduce.reduce.shuffle.parallelcopies | 50 | 通过reduces从很多的map中读取较多的平行 副本 |
15、配置yarn-site.xml,使用如下命令打开
sudo vim etc/hadoop/yarn-site.xml 然后在<configuration>标签中添加以下代码:
<property>
<name>yarn.resourcemanager.address</name>
<value>sunxj-hdm.myhd.com:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>sunxj-hdm.myhd.com:18030</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>sunxj-hdm.myhd.com:18088</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>sunxj-hdm.myhd.com:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>sunxj-hdm.myhd.com:18141</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>如下图所示:

属性说明:
- master节点配置ResourceManager 和 NodeManager:
| 参数 | 属性值 | 解释 |
| yarn.resourcemanager.address | 客户端对ResourceManager主机通过 host:port 提交作业 | host:port |
| yarn.resourcemanager.scheduler.address | ApplicationMasters 通过ResourceManager主机访问host:port跟踪调度程序获资源 | host:port |
| yarn.resourcemanager.resource-tracker.address | NodeManagers通过ResourceManager主机访问host:port | host:port |
| yarn.resourcemanager.admin.address | 管理命令通过ResourceManager主机访问host:port | host:port |
| yarn.resourcemanager.webapp.address | ResourceManager web页面host:port. | host:port |
| yarn.resourcemanager.scheduler.class | ResourceManager 调度类(Scheduler class) | CapacityScheduler(推荐),FairScheduler(也推荐),orFifoScheduler |
| yarn.scheduler.minimum-allocation-mb | 每个容器内存最低限额分配到的资源管理器要求 | 以MB为单位 |
| yarn.scheduler.maximum-allocation-mb | 资源管理器分配给每个容器的内存最大限制 | 以MB为单位 |
| yarn.resourcemanager.nodes.include-path/ yarn.resourcemanager.nodes.exclude-path |
NodeManagers的permitted/excluded列表 | 如有必要,可使用这些文件来控制允许NodeManagers列表 |
- slave节点配置NodeManager
| 参数 | 属性值 | 解释 |
| yarn.nodemanager.resource.memory-mb | givenNodeManager即资源的可用物理内存,以MB为单位 | 定义在节点管理器总的可用资源,以提供给运行容器 |
| yarn.nodemanager.vmem-pmem-ratio | 最大比率为一些任务的虚拟内存使用量可能会超过物理内存率 | 每个任务的虚拟内存的使用可以通过这个比例超过了物理内存的限制。虚拟内存的使用上的节点管理器任务的总量可以通过这个比率超过其物理内存的使用 |
| yarn.nodemanager.local-dirs | 数据写入本地文件系统路径的列表用逗号分隔 | 多条存储路径可以提高磁盘的读写速度 |
| yarn.nodemanager.log-dirs | 本地文件系统日志路径的列表逗号分隔 | 多条存储路径可以提高磁盘的读写速度 |
| yarn.nodemanager.log.retain-seconds | 10800 | 如果日志聚合被禁用。默认的时间(以秒为单位)保留在节点管理器只适用日志文件 |
| yarn.nodemanager.remote-app-log-dir | logs | HDFS目录下的应用程序日志移动应用上完成。需要设置相应的权限。仅适用日志聚合功能 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 后缀追加到远程日志目录。日志将被汇总到yarn.nodemanager.remoteapplogdir/yarn.nodemanager.remoteapplogdir/{user}/${thisParam} 仅适用日志聚合功能。 |
| yarn.nodemanager.aux-services | mapreduce-shuffle | Shuffle service 需要加以设置的Map Reduce的应用程序服务 |
16、使用如下命令打开slaves文件
sudo vim etc/hadoop/slaves 把原本的localhost删掉,然后分别改为:sunxj-hds1.myhd.com,sunxj-hds2.myhd.com ,如下图所示:

17、配置hadoop环境变量,使用sudo vim /etc/profile打开文件,在末尾添加入下代码:
export HADOOP_HOME=/usr/hadoop-2.7.7
export PATH="$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop如下图所示:

18、输入如下命令使配置立即生效
source /etc/profile 19、使用如下命令:
scp -r hadoop-2.7.7 [email protected]:/home/sunftp/ftpdir/将hadoop-2.7.7传给slave1,如下图所示:

20、然后在slave1上将hadoop-2.7.7移动到usr目录,使用如下命令进行移动
sudo mv /home/sunftp/ftpdir/hadoop-2.7.7 /usr/如下图所示:

21、用同样办法拷贝到slave2上。
22、在两个slave上执行16~17步。
23、在master主机上执行,此时使用hadoop用户登录通过如下命令进行格式化
hdfs namenode -format此时会出现两个异常
8/12/25 00:45:19 WARN namenode.NameNode: Encountered exception during format:
java.io.IOException: Cannot remove current directory: /usr/hadoop-2.7.7/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:335)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:564)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:585)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:179)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1015)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1457)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1582)
18/12/25 00:45:19 ERROR namenode.NameNode: Failed to start namenode.
java.io.IOException: Cannot remove current directory: /usr/hadoop-2.7.7/hdfs/name/current
at org.apache.hadoop.hdfs.server.common.Storage$StorageDirectory.clearDirectory(Storage.java:335)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:564)
at org.apache.hadoop.hdfs.server.namenode.NNStorage.format(NNStorage.java:585)
at org.apache.hadoop.hdfs.server.namenode.FSImage.format(FSImage.java:179)
at org.apache.hadoop.hdfs.server.namenode.NameNode.format(NameNode.java:1015)
at org.apache.hadoop.hdfs.server.namenode.NameNode.createNameNode(NameNode.java:1457)
at org.apache.hadoop.hdfs.server.namenode.NameNode.main(NameNode.java:1582)
18/12/25 00:45:19 INFO util.ExitUtil: Exiting with status 1
如下图所示:

24、意思是对/usr/hadoop-2.7.7/hdfs/name/current目录没有写入权限,只需使用如下命令添加写入权限:
sudo chmod -R 777 /usr/hadoop-2.7.7为保持一致,也需要在slave1和slave2上执行,然后再次格式化,如下图所示:


25、在master上开启hadoop,使用start-all.sh 启动,如下图所示:

26、然后输入yes回车,然后只要是出现此界面都输入yes即可,如下图所示:

27、然后在master节点上输入jps命令查看hadoop进程,此时master主节点有4个ResourceManager,Jps, NameNode, SecondaryNamenode,如下图所示:

28、两个从节点slave1和slave2的hadoop进程,如下图所示:
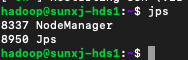
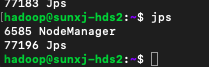
29、正常情况应该还有一个DataNode进程,但是此处没有启动,这种情况分为两种原因,一种是第一次格式化后第一次启动,slave1和slave2上没有DataNode进程,另一种已经启动过一次或者多次重新格式化后在slave1和slave2上没有DataNode进程,下面分两种情况分析:
第一种情况:
(1)只需要在slave1和slave2上更改hdfs-site.xml 配置文件,由于两个从节点上的hadoop是从master节点拷贝过的,因此需要单独更改两个节点上的hdfs-site.xml 文件,通过如下命令进行编辑slave1节点上的配置文件:
sudo vim /usr/hadoop-2.7.7/etc/hadoop/hdfs-site.xml 如下图所示:
更改为:

(2)在slave2上也是同样的修改,保存退出。
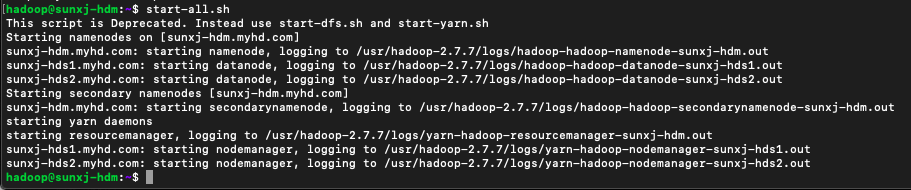
(3)在master节点上在次启动hadoop即可,如下图所示:
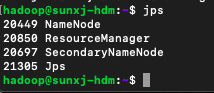
(4)查看master节点进程,如下图所示:
slave1节点的进程,如下图所示:
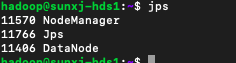
slave2节点的进程,如下图所示:
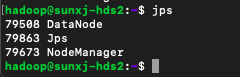
(5)到此hadoop集群环境安装完毕。
第二种情况:
此种情况有3个方法来解决:
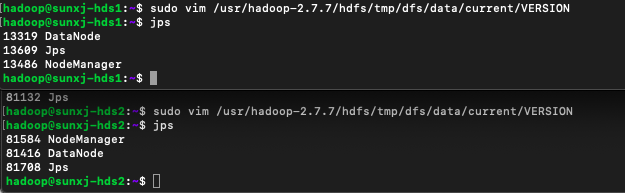
(1)将slave1和slave2上/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION文件中的clusterID替换到master上/usr/hadoop-2.7.7/hdfs/name/current/VERSION文件中的clusterID
<1> 先暂停master上的hadoop,输入如下指令停止:
stop-all.sh 如下图所示:

<2> 查看master、slave1和slave2进程情况,如下图所示:
master进程:
![]()
slave1进程:
![]()
slave2进程:
![]()
<3> 说明hadoop已停止,现在重新格式化,如下图所示:

<4> 然后在master启动hadoop,查看slave1和slave2的进程情况,如下图所示:
slave1进程:
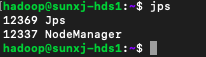
slave2进程:

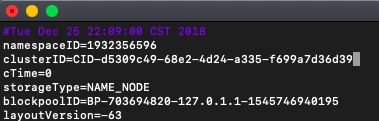
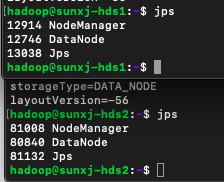
<5> 由此可以看出只要重新格式化后就无法启动DataNode进程,现在先停止hadoop,然后来查看master上、slave1、slave2上的clusterID, 在master上有两个地方有clusterID,位置在:
/usr/hadoop-2.7.7/hdfs/name/current/VERSION
/usr/hadoop-2.7.7/hdfs/tmp/dfs/namesecondary/current/VERSION查看的clusterID如下图所示,此时有多处的值不同

<6> slave1和slave2上的clusterID的位置在:
/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION查看的clusterID如下图所示,由图可知两台上的clusterID是相同的,也与master上的/usr/hadoop-2.7.7/hdfs/tmp/dfs/namesecondary/current/VERSION中的clusterID相同。

<7> 我们先将master上的/usr/hadoop-2.7.7/hdfs/name/current/VERSION位置的clusterID值更改为slave节点上的clusterID(注意:先将原来的ID保存,以便将master上的clusterID替换到slave上),使用如下命令进行编辑:
<8> 保存退出,然后启动hadoop,然后查看slave1和slave2上的进程已经有DataNode进程了,如下图所示:
(2)将master上/usr/hadoop-2.7.7/hdfs/name/current/VERSION文件中的clusterID替换到slave1和slave2上/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION文件中的clusterID
<1>先停止master上的hadoop,然后将保存下来的clusterID替换master、slave1和slave2上在master使用如下命令编辑:
sudo vim /usr/hadoop-2.7.7/hdfs/name/current/VERSION在slave1和slave2上使用如下命令编辑:
sudo vim /usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/VERSION<2>在master启动hadoop,然后查看slave1和slave2上的进程已经有DataNode进程了,如下图所示:
(3)还有可以将slave1和slave2的文件删除/usr/hadoop-2.7.7/hdfs/tmp/dfs/data/current/目录中的VERSION文件删除,首先停止hadoop,然后再次格式化,并将VERSION删除,在启动hadoop,然后查看slave1和slave2上的进程已经有DataNode进程了,如下图所示:

(4)由以上3中办法中只有第一种是最方便的,由于重新格式化后只有master节点上与其他的slave节点clusterID不同,而所有的slave的clusterID是相同的,因此只需要更改一处即可,而第二种和第三种方法都需要操作多台机才行。
七、用自带的样例测试hadoop集群能不能正常跑任务
1、使用如下命令测试:
hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10此命令是用来求圆周率,pi是类名,第一个10表示Map次数,第二个10表示随机生成点的次数,由于是在一台机器虚拟出了3个系统来运行,所以计算这个有点久,目前是在运行状态,如下图所示:

用这个命令运行了一天,结果还是这个状态,不知道怎么回事。
2、现在使用另一个测试,hadoop自带的wordcount例子,这个是统计单词个数的,首先要在hdfs系统中创建文件夹,要查看hdfs系统可以通过hadoop fs -ls来查看hdfs系统的文件以及目录情况,如下图所示:

3、使用如下命令在hdfs中创建一个word_count_input文件夹:
hadoop fs -mkdir word_count_input如下图所示:

4、然后使用如下命令在本地创建两个文件file1.txt和file2.txt:
sudo vim file1.txt然后在file1.txt输入如下内容,由此可以看到:hello 5,hadoop 4,sunxj 2 win 1:
hello hadoop
hello sunxj
hello hadoop
hello hadoop
hello win
sunxj hadoop在file2.txt输入如下内容,由此可以看到:hello 2,linux 2,window 2:
linux window
hello linux
hello window如下图所示:
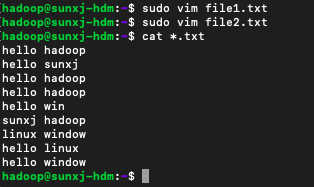
由此可以计算出world的个数分别为:hello有7个,hadoop有4,sunxj有2个,win有1个inux,有2个,window有2个。
5、通过如下命令将file1.txt和file2.txt文件上传到hdfs系统的word_count_input文件夹中:
hadoop fs -put file*.txt word_count_input如下图所示:

6、然后使用如下命令运行wordcount:
hadoop jar /usr/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount word_count_input word_count_output其中wordcount是类名,word_count_input是输入文件夹目录,word_count_output是输出目录,如下图所示:

7、在图中出现了拒绝连接:
18/12/26 20:51:23 INFO client.RMProxy: Connecting to ResourceManager at sunxj-hdm.myhd.com/192.168.0.109:18040
18/12/26 20:51:24 INFO input.FileInputFormat: Total input paths to process : 2
18/12/26 20:51:24 INFO mapreduce.JobSubmitter: number of splits:2
18/12/26 20:51:25 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545828647598_0001
18/12/26 20:51:25 INFO impl.YarnClientImpl: Submitted application application_1545828647598_0001
18/12/26 20:51:25 INFO mapreduce.Job: The url to track the job: http://sunxj-hdm.myhd.com:18088/proxy/application_1545828647598_0001/
18/12/26 20:51:25 INFO mapreduce.Job: Running job: job_1545828647598_0001
18/12/26 20:57:28 INFO mapreduce.Job: Job job_1545828647598_0001 running in uber mode : false
18/12/26 20:57:28 INFO mapreduce.Job: map 0% reduce 0%
18/12/26 20:57:28 INFO mapreduce.Job: Job job_1545828647598_0001 failed with state FAILED due to: Application application_1545828647598_0001 failed 2 times due to Error launching appattempt_1545828647598_0001_000002. Got exception: java.net.ConnectException: Call From sunxj-hdm/127.0.0.1 to localhost:37113 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.GeneratedConstructorAccessor47.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:792)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:732)
at org.apache.hadoop.ipc.Client.call(Client.java:1480)
at org.apache.hadoop.ipc.Client.call(Client.java:1413)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy83.startContainers(Unknown Source)
at org.apache.hadoop.yarn.api.impl.pb.client.ContainerManagementProtocolPBClientImpl.startContainers(ContainerManagementProtocolPBClientImpl.java:96)
at sun.reflect.GeneratedMethodAccessor14.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:191)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:102)
at com.sun.proxy.$Proxy84.startContainers(Unknown Source)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.launch(AMLauncher.java:118)
at org.apache.hadoop.yarn.server.resourcemanager.amlauncher.AMLauncher.run(AMLauncher.java:250)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.ConnectException: 拒绝连接
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:495)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:615)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:713)
at org.apache.hadoop.ipc.Client$Connection.access$2900(Client.java:376)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1529)
at org.apache.hadoop.ipc.Client.call(Client.java:1452)
... 15 more
. Failing the application.
18/12/26 20:57:28 INFO mapreduce.Job: Counters: 0
8、出现此错误则需要将master、slave1、slave2上的/etc/hosts文件中所有127.0.01的注释掉,如下图所示:

9、然后停止hadoop然后在启动,继续执行第6步即可,如下打印信息说明执行成功:
18/12/26 21:44:36 INFO client.RMProxy: Connecting to ResourceManager at sunxj-hdm.myhd.com/192.168.0.109:18040
18/12/26 21:44:37 INFO input.FileInputFormat: Total input paths to process : 2
18/12/26 21:44:37 INFO mapreduce.JobSubmitter: number of splits:2
18/12/26 21:44:38 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545831828732_0001
18/12/26 21:44:38 INFO impl.YarnClientImpl: Submitted application application_1545831828732_0001
18/12/26 21:44:38 INFO mapreduce.Job: The url to track the job: http://sunxj-hdm.myhd.com:18088/proxy/application_1545831828732_0001/
18/12/26 21:44:38 INFO mapreduce.Job: Running job: job_1545831828732_0001
18/12/26 21:44:54 INFO mapreduce.Job: Job job_1545831828732_0001 running in uber mode : false
18/12/26 21:44:54 INFO mapreduce.Job: map 0% reduce 0%
18/12/26 21:45:10 INFO mapreduce.Job: map 100% reduce 0%
18/12/26 21:45:18 INFO mapreduce.Job: map 100% reduce 100%
18/12/26 21:45:19 INFO mapreduce.Job: Job job_1545831828732_0001 completed successfully
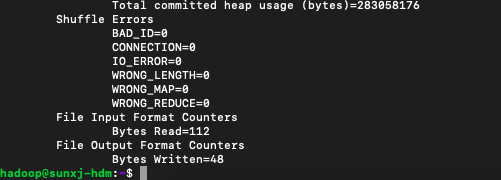
18/12/26 21:45:20 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=90
FILE: Number of bytes written=369023
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=380
HDFS: Number of bytes written=48
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=26359
Total time spent by all reduces in occupied slots (ms)=6412
Total time spent by all map tasks (ms)=26359
Total time spent by all reduce tasks (ms)=6412
Total vcore-milliseconds taken by all map tasks=26359
Total vcore-milliseconds taken by all reduce tasks=6412
Total megabyte-milliseconds taken by all map tasks=26991616
Total megabyte-milliseconds taken by all reduce tasks=6565888
Map-Reduce Framework
Map input records=9
Map output records=18
Map output bytes=184
Map output materialized bytes=96
Input split bytes=268
Combine input records=18
Combine output records=7
Reduce input groups=6
Reduce shuffle bytes=96
Reduce input records=7
Reduce output records=6
Spilled Records=14
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=407
CPU time spent (ms)=7380
Physical memory (bytes) snapshot=526221312
Virtual memory (bytes) snapshot=5854740480
Total committed heap usage (bytes)=283058176
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=112
File Output Format Counters
Bytes Written=48如下图所示:

10、此时在看word_count_output文件夹,如下图所示:

11、然后使用如下命令打印:
hadoop fs -cat word_count_output/part-r-00000如下图所示:

与我们统计的相同:hello有7个,hadoop有4,sunxj有2个,win有1个inux,有2个,window有2个
12、然后在次运行第一个例子即可成功,如下打印信息:
Number of Maps = 10
Samples per Map = 10
Wrote input for Map #0
18/12/26 22:04:48 WARN hdfs.DFSClient: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1252)
at java.lang.Thread.join(Thread.java:1326)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeResponder(DFSOutputStream.java:716)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.closeInternal(DFSOutputStream.java:684)
at org.apache.hadoop.hdfs.DFSOutputStream$DataStreamer.run(DFSOutputStream.java:680)
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Starting Job
18/12/26 22:04:48 INFO client.RMProxy: Connecting to ResourceManager at sunxj-hdm.myhd.com/192.168.0.109:18040
18/12/26 22:04:49 INFO input.FileInputFormat: Total input paths to process : 10
18/12/26 22:04:49 INFO mapreduce.JobSubmitter: number of splits:10
18/12/26 22:04:49 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1545831828732_0002
18/12/26 22:04:49 INFO impl.YarnClientImpl: Submitted application application_1545831828732_0002
18/12/26 22:04:49 INFO mapreduce.Job: The url to track the job: http://sunxj-hdm.myhd.com:18088/proxy/application_1545831828732_0002/
18/12/26 22:04:49 INFO mapreduce.Job: Running job: job_1545831828732_0002
18/12/26 22:04:59 INFO mapreduce.Job: Job job_1545831828732_0002 running in uber mode : false
18/12/26 22:04:59 INFO mapreduce.Job: map 0% reduce 0%
18/12/26 22:06:59 INFO mapreduce.Job: map 40% reduce 0%
18/12/26 22:07:31 INFO mapreduce.Job: map 100% reduce 0%
18/12/26 22:07:51 INFO mapreduce.Job: map 100% reduce 100%
18/12/26 22:07:52 INFO mapreduce.Job: Job job_1545831828732_0002 completed successfully
18/12/26 22:07:53 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=226
FILE: Number of bytes written=1356190
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2750
HDFS: Number of bytes written=215
HDFS: Number of read operations=43
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=10
Launched reduce tasks=1
Data-local map tasks=10
Total time spent by all maps in occupied slots (ms)=1497386
Total time spent by all reduces in occupied slots (ms)=15618
Total time spent by all map tasks (ms)=1497386
Total time spent by all reduce tasks (ms)=15618
Total vcore-milliseconds taken by all map tasks=1497386
Total vcore-milliseconds taken by all reduce tasks=15618
Total megabyte-milliseconds taken by all map tasks=1533323264
Total megabyte-milliseconds taken by all reduce tasks=15992832
Map-Reduce Framework
Map input records=10
Map output records=20
Map output bytes=180
Map output materialized bytes=280
Input split bytes=1570
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=280
Reduce input records=20
Reduce output records=0
Spilled Records=40
Shuffled Maps =10
Failed Shuffles=0
Merged Map outputs=10
GC time elapsed (ms)=9878
CPU time spent (ms)=78120
Physical memory (bytes) snapshot=1685659648
Virtual memory (bytes) snapshot=21453107200
Total committed heap usage (bytes)=1317511168
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1180
File Output Format Counters
Bytes Written=97
Job Finished in 184.711 seconds
Estimated value of Pi is 3.20000000000000000000如下图所示:


13、此时会有一个异常,不影响程序运行,不知道如何解决。
八、通过web查看集群运行情况,首先查看
1、YARN的web页面,则是在master机器上,然后端口是用yarn-site.xml配置文件中的yarn.resourcemanager.webapp.address指定的,我们配置的是18088,那么在浏览器中输入:http://192.168.0.109:18088即可打开界面,如下图所示:

界面中显示的记录则是执行的任务个数。
2、HDFS界面在master上打开,如果没有更改端口,则默认的端口是50070:http://192.168.0.109:50070,如下图所示:




3、由于没有在yarn-site.xml文件中配置历史服务器,所以HistoryServer的管理界面无法查看,如果有历史服务器,则可以在yarn-site.xml中增加如下配置即可:
<!--配置历史服务器-->
<property>
<name>mapreduce.jobhistory.address</name>
<value>192.168.1.105:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.105:19888</value>
</property>
然后使用mr-jobhistory-daemon.sh start historyserver启动即可。