梯度提升随机树GBDT
1.基本概念
GBDT是一种基于集成思想的决策树模型,本质是基于残差学习。
特点在于:可处理各种类型的数据;有着较高的准确率;对异常值的鲁棒性强;不能并行训练数据
2.GBDT训练过程
GBDT采用加法模型,通过不断减小训练过程产生的残差,以此对数据进行回归或分类。GBDT进行多轮迭代,每轮迭代产生一个弱分类器CART回归树,该分类器是在上一轮分类器的残差结果基础上训练得到的。对弱分类器的要求是低方差、高偏差(低方差保证模型不会过拟合+高偏差在训练过程中会减小,以此提高精度)。为了使损失函数尽可能快地减小,用损失函数的负梯度作为残差的近似值,然后去拟合CART回归树。
3.GBDT损失函数
(分类):指数损失函数 + 对数似然损失函数
(回归):均方差 + 绝对损失 + Huber损失 + 分位数损失
4.GBDT正则化
方式: 设置步长 + 子采样 + 剪枝操作
5.GBDT选择特征
实质是CART树生成过程,包括选择特征及切分点
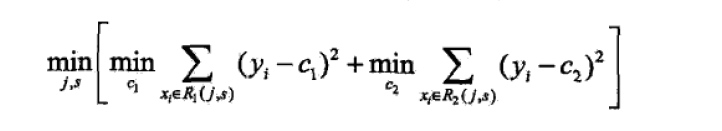
(代码实现)
def chooseBestFeatandSplit(dataSet):
globalBestLoss = np.Inf
globalBestFeatIndex = -1
globalBestSplit = 0
dim = dataSet.shape[1]-1
for i in range(dim):
featMat = dataSet[:,i]
tmpLoss = []
for value in featMat:
R1 = dataSet[featMat<=value]
R2 = dataSet[featMat>value]
c1 = np.mean(R1[:,-1]) if len(R1) else 0
c2 = np.mean(R2[:,-1]) if len(R2) else 0
L = np.sum((R1[:,-1]-c1)**2)+np.sum((R2[:,-1]-c2)**2)
tmpLoss.append(L)
index = np.argmin(np.array(tmpLoss))
localBestSplit = dataSet[index,i]
localBestLoss = tmpLoss[index]
print('特征= ',i,' 最佳切分点= ',localBestSplit,' 对应损失= ',localBestLoss)
if localBestLoss < globalBestLoss:
globalBestLoss = localBestLoss
globalBestFeatIndex = i
globalBestSplit = localBestSplit
print('最优特征= ',globalBestFeatIndex,' 最优切分点= ',globalBestSplit)
6.GBDT分类
在类别数为K条件下,在每轮迭代中实质上要同时训练K棵CART回归树,得到K个预测模型F(X),并计算残差e(X)=Y-F(X)
在下一轮迭代中,用数据点(X,e(X))分别去拟合K棵CART回归树,以此类推,得到最终的模型。
(1)将Label进行one-hot编码
from sklearn.preprocessing import OneHotEncoder
onehotEncoder = OneHotEncoder(sparse=False)
Y = onehotEncoder.fit_transform(labels.reshape(-1,1))
(2)重构数据集dataSet
矩阵Y的大小为(num x K),num表示样本数;K表示类别数
对于第k棵数,dataSet = np.hstack((x,Y[:,k].reshape(-1,1)))(将Y的第k列取出作为重构数据集的Label)
(3)选择最优特征和切分点
(4)得到每轮预测模型
![]()
(5)得到最终的预测模型
经过M轮迭代,第k个加总模型为:

用softmax函数将预测值转换为概率,即:

p(k)表示样本属于类别k的概率,选择最大概率所在的类别作为预测输出。