初识模块
python的强大之处在于他有非常强大的标准库和第三方库,甚至在必须的时候,我们可以为自己的程序编写需要的模块(库);
标准库:不需要安装,直接“import”导入即可使用的库(模块),这样的库就叫做标准库;
第三方库:必须要下载安装才能使用的库,为第三方库;
python下的库存放在一个固定的目录下面:
import sys print(sys.path)

默认情况下,python解释器在寻找库文件的时候,先找与运行文件为同一目录下的库文件,如果没有,再去寻找“X:\...\python37-32\lib\ste-packages”目录和“X:\...\python37-32\lib\”目录;而前者目录一般存放第三方库文件,后者目录则用来存放标准库文件;
【首先在导入库名的时候需要注意:文件取名的时候不能和库名相同;】
sys标准库
sys提供了python程序与参数之间的交互方式:上图我们使用了sys.path方法,它用来查看python程序的环境变量路径;
sys.argv 方法:用来传递参数给python程序
文件名:sys.argv.py import sys print(sys.argv) 运行: C:\>python sys.argv.py 1 2 3
['sys.argv.py','1','2','3']
这里面的“1 2 3”则会以列表的形式在程序里面导入进来,如果你需要提取对应列表中的参数,则在输入的时候加上下标值即可,例如:sys.argv[0];
os标准库
调用windows系统下的命令以及相关程序;
调用os.system()方法来调取命令:
import os
cmd_os = os.system("dir")
print("-->",cmd_os)
这里print的参数为0,而cmd_os没有真实的存储os.system("dir")的值,而是仅仅只是显示下,而存储的只是一个状态码,类似于Linux系统下的echo $?所返回的值一样;
cmd_os = os.popen("dir").read()
这样的话就可以将数据存储在cmd_os中,且通过read()函数来读取该数据;
os.mkdir():在当前文件目录下面来创建新的目录;
import os
os.mkdir("new_dir")
pyc文件
1、python是一门解释型的语言
pyc文件是通过python编译器对python程序进行编译后的二进制文件,一般存放在目录"..\Python\Python37-32\Lib\__pycache__"下面,当python程序修改了以后,pyc文件就会自动更新,这样就节约了我们编译文件的时间;
2、解释型语言和编译型语言
计算机是不能识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来将高级语言装换为计算机能够读懂的语言,这个过程分为两类:第一类是编译,第二种就是解释;
编译型语言在程序执行之前会通过编译器将程序整体编译一次,再进行执行,典型的编译语言就是C语言;
解释型语言就没有这个过程,而是通过程序运行一句,解释一句,逐步解释,最典型的例子就是Ruby;
编译型语言在程序执行之前就做了“翻译”,所以在执行程序的时候不需要再编译程序,所以程序执行速度会比较快;所以效率上面来说,编译型语言要比解释型语言效率要高;
3、python到底是什么?
其实python和JAVA、C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单的解释一下python运行过程:
当我们在命令行中输入python hello.py时,其实是激活了python的“解释器”,告诉“解释器”:我要开始工作了;python则这时候帮助我们进行下预编译。
4、简述python的运行过程
我们先了解下PyCodeObject和pyc文件;
PyCodeObject则是python编译器真正编译器成的结果,当我们运行python程序的时候,编译的结果则会保存在内存中的PyCodeObject中,当Python程序运行结束后,python解释器则将PyCodeObject写回到pyc文件中;
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复以上的过程;
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的持久化的保存方式。
初识数据类型
数字类型
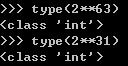
整数型:在python3版本下不再分长整形与短整型,如果数据过大(大于2**32)不再需要特定指定数据类型了;
浮点型:浮点型数据可以理解为就是小数,但是小数一定是浮点类型,但是浮点数不仅仅只有小数这一类数;

浮点型可以表示为常见的1.xxx也可以通过e的方式来表示,如上图;
复数:-5+4j,complex,这种数据类型一般在物理工程上面使用的较多,对于python编程使用较少;注意:这里不是以i来表示复数,而是以j来表示;

布尔值
表示“真”“假”和以及“0”“1”
字符串
string类型,一般使用冒号来表示字符串数据类型,一般输入的数据默认就会是字符串类型;
*字符串类型必须区分bytes类型
bytes类型
数据传输需要将原本的字符串类型数据转换成为字节类型数据,因为我们传统的以太网只能传递字节类型数据!!!
python3下面严格的区分了str和bytes数据类型;所以再网络编程中,需要进行数据传输的时候,需要进字符串转换成二进制;
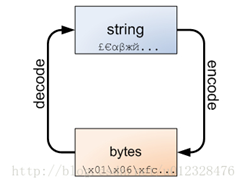
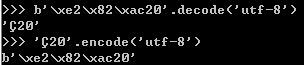
注意:这里在二进制数据转换为字符串的时候需要在最前面加上b,这个b表示就是二进制数据;
*列表
【列表和字典是我们将来编程使用最多的数据类型!!!】
如果我们想存储很多的数据,使用字符串伙子字符的形式来存储就非常麻烦了,这时候,我们需要通过类表的方式来进行数据存储;
同时,列表通过数据嵌套的方式可以存储关联数据,这一点非常方便;
列表数据和元组的区别是,列表还可以通过一系列的方式来对数据进行修改,而元组则可以理解为一个无法修改的列表数据;
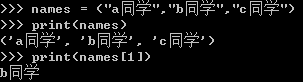
names = ["a同学","b同学","c同学","d同学","e同学","f同学"] print(names) print(names[0])
列表数据有自己的下标,调用方式如上:names[0],则表示调用"a同学";下标以此类推;
*列表的切片*
print(names[1:3])
#b同学和c同学会被打印出来
列表在切片打印的时候,会“顾头不顾尾”;
print(names[-3:-1])
#-1表示最后一位数据,也就是f同学,-3则是d同学,所以这里会打印d同学,e同学;
print(names[-3:])
#这样的话,在最后一位的f同学也会被打印出来;同理,如果想从下标0的数据开始打印,也可这样写:
print(names[:3])
倒叙切片注意需要从编号较小的数据开始;0下标或者-1下标可以不用写;
print(names[:])
#所以,这样也可以表示names列表下的所有数据;
相关常见方法:
1、追加值到列表中去:
names.append("g同学")
默认追加数据到原列表的最后中;如果想将数据插入到类表中的特定位置,比如c同学前面,这样就需要通过insert方法,加上下标来实现:
names.insert(2) #要写在哪里,就将下标写在insert方法中,这样原本在该下标下的数据就会向后推一位
2、修改列表中的值:
names[2] = "x同学"
修改列表中的数据,可以直接替换就可以了;
3、删除列表中的值:
names.remove("x同学")
del names[2]
names.pop[1] #如果不输入下标就是默认删除最后一位数据
4、查找列表中的数据
print(names.index("a同学"))
print(names(names.index("a同学")))
输出“a同学”这个数据的下标,打印"a同学"下标所对应的数据;
5、统计列表中的数据
print(names.count("a同学"))
统计列表中出现"a同学"这个数据的次数;
6、其他列表中的方法
names.clear() #清除列表内容 names.reverse() #列表中的数据进行翻转 names.sort() #对列表中的数据进行排序,顺序:特殊符号---数字--字母 names2 = ["f同学","g同学"] names.extend(names2) #扩展列表,将names2这个列表的数据与names这个列表数据融合在一块
del names #删除整个列表
7、列表的复制
列表数据的复制分为浅复制与完全复制,这两个概念就有点像Linux系统下的硬连接与软连接的区别,浅复制就好像软连接,只关联数据的第一层,如果列表有多层嵌套,使用copy()方法来进行赋值,则没办法修改后几层的数据;
names = ["1","2",["3","4"]]
names3 = names.copy()
names[2][0] = 100
print(names)
print(names3)
只额时候name和names两个数据指向的为同一个内存数据,所以,names和names3显示的数据为一样的,这种情况就叫做浅复制;
完全复制则为腾出一个新的内存空间来存放这个数据;
import copy names = ["1","2",["3","4"]] names3 = copy.deepcopy(names)
deepcopy的方式则为深copy的方法,但是一般不建议这样copy列表,如果列表数据量很大,则这种复制方式对设备性能要求比较高;
8、列表的循环
names = ["1","2","3"] #print(names[0:-1:2]以2为步长来进行数据输出),0和-1都可以省略names[::2]
for i in names: print(i)
可以添加步长,实现列表的循环;
元组
元组数据就是不能变更的列表;