一:解读
官网:https://spark.apache.org/docs/latest/sql-getting-started.html
The first method uses reflection to infer the schema of an RDD that contains specific types of objects. This reflection-based approach leads to more concise code and works well when you already know the schema while writing your Spark application.
第一种方法使用反射来推断包含特定类型对象的RDD的模式。当您在编写Spark应用程序时已经了解了模式时,这种基于反射的方法会导致更简洁的代码,并且工作得很好。
二:操作
package g5.learning
import org.apache.spark.sql.SparkSession
object DFApp {
def main(args: Array[String]): Unit = {
val sparksession= SparkSession.builder().appName("DFApp")
.master("local[2]")
.getOrCreate()
inferReflection(sparksession)
sparksession.stop()
}
//创建RDD
def inferReflection(sparkSession: SparkSession)={
val info = sparkSession.sparkContext.textFile("file:///E:\\data.txt")
//取字段 这里是用sparkContext写的
// info.map(x=> {
// val temp = x.split("\t")
// (temp(0),temp(1),temp(2))
// })
// info.take(3).foreach(println)
//这里要注意类型转换
import sparkSession.implicits._
val df =info.map(_.split("\t")).map(x=>Info(x(0),x(1),x(2).toLong)).toDF()
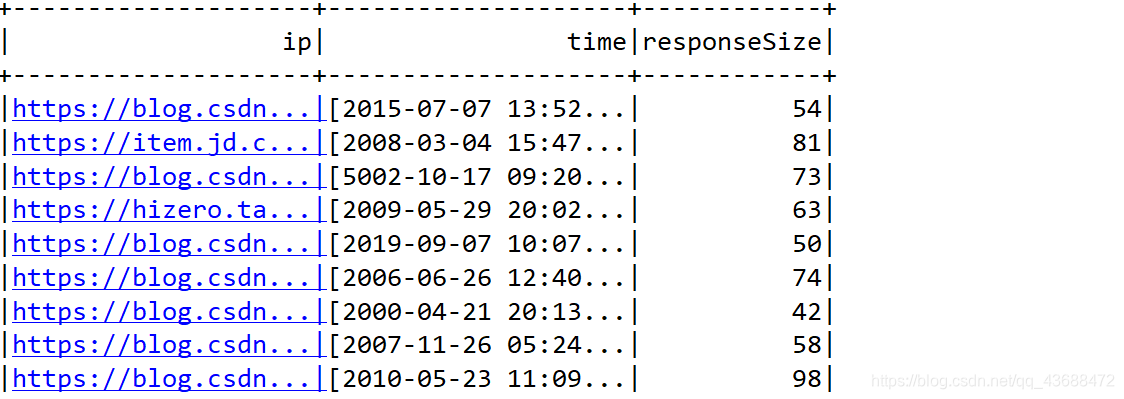
df.show()
//代表是时间相同的流量和(行)
df.groupBy("time").sum("responseSize").show()
//存在的试图一张表
df.createGlobalTempView("info")
sparkSession.sql("select time,sum(responseSize) from info group by time").show()
}
case class Info(ip:String,time:String,responseSize:Long)
}
//这种格式是知道数据格式和类型
三:结果