一:解释
官网:https://spark.apache.org/docs/latest/sql-getting-started.html
这种场景是生活中的常态
When case classes cannot be defined ahead of time (for example, the structure of records is encoded in a string, or a text dataset will be parsed and fields will be projected differently for different users), a DataFrame can be created programmatically with three steps.
Create an RDD of Rows from the original RDD;
Create the schema represented by a StructType matching the structure of Rows in the RDD created in Step 1.
Apply the schema to the RDD of Rows via createDataFrame method provided by SparkSession.
二:操作
package g5.learning
import org.apache.spark.sql.types.{LongType, StructField, StructType,StringType}
import org.apache.spark.sql.{Row, SparkSession}
object DFApp {
def main(args: Array[String]): Unit = {
val sparksession= SparkSession.builder().appName("DFApp")
.master("local[2]")
.getOrCreate()
//inferReflection(sparksession)
programmatically(sparksession)
sparksession.stop()
}
//第二种方法是编程的形式
def programmatically(sparkSession: SparkSession)={
val info = sparkSession.sparkContext.textFile("file:///E:\\data.txt")
//Create an RDD of Rows from the original RDD;
import sparkSession.implicits._
val rdd =info.map(_.split("\t")).map(x=>Row(x(0),x(1),x(2).toLong))
//这个rdd是个row类型
//Create the schema
val struct =StructType(Array(
StructField("ip", StringType,true),
StructField("time", StringType,false) ,
StructField("responseSize",LongType,false)
))
//Apply the schema to the RDD of Rows via createDataFrame method provided by SparkSession.
val df = sparkSession.createDataFrame(rdd,struct)
df.show()
}
}
三:注意
1.这种类型要比官网更好,适合大部分类型
2.要注意算子的转换(开始的时候,找算子也是遇到了很多麻烦,算子很多,要注意挑选自己的需求)
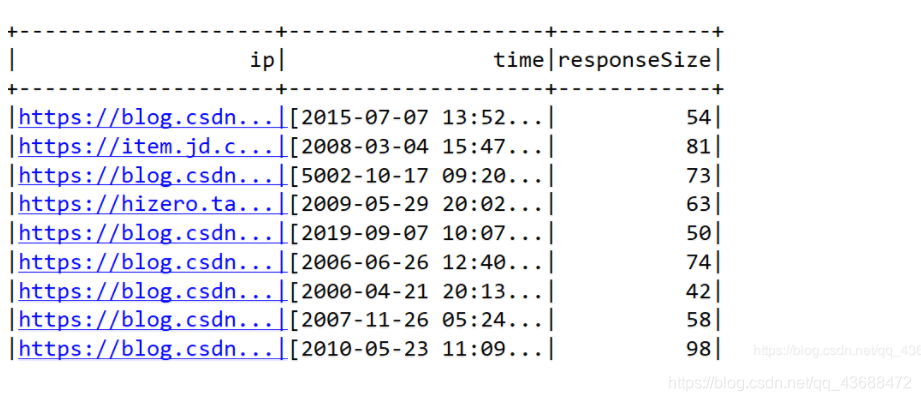
四:结果