【Tensorflow专题-02】使用tensorflow实现神经网络
前向传播算法
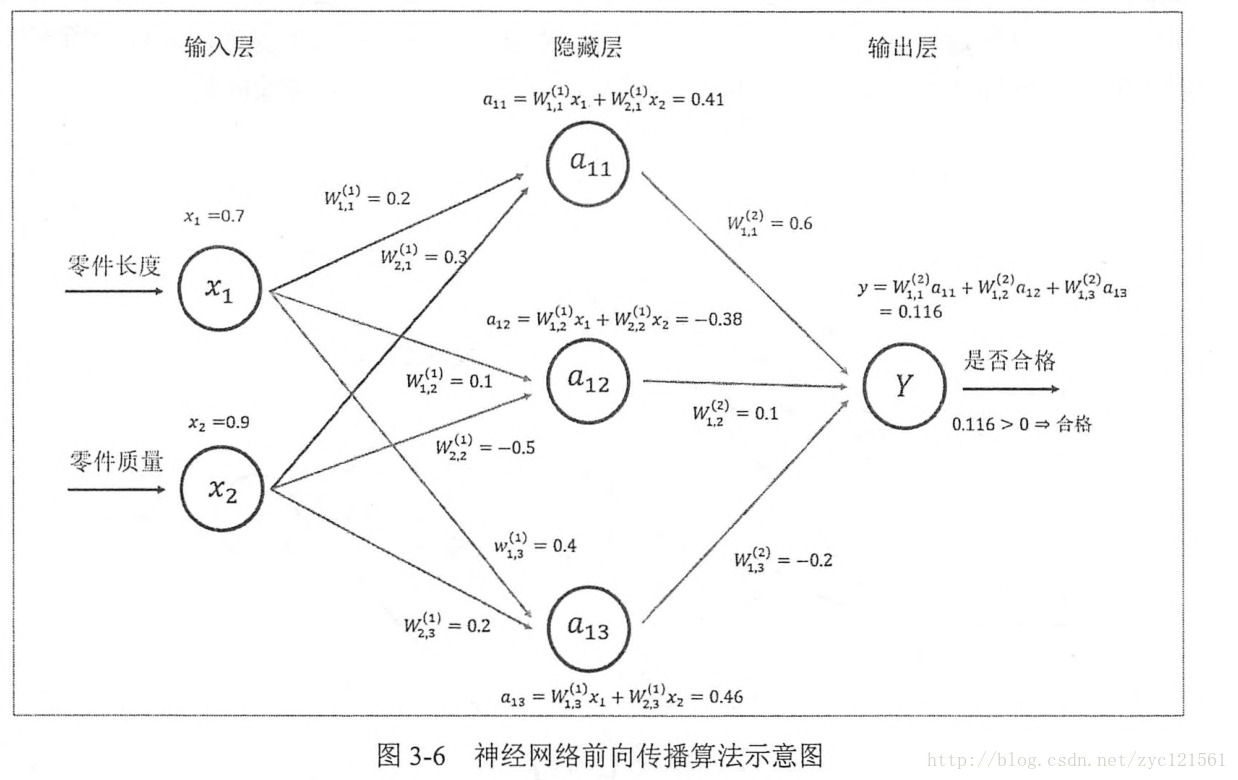
如下示意了一个三层的神经网络前向传播过程
传播过程有三个重要参数,分别是:权重W,节点取值a及输出y,表示为矩阵如下:
W(1)=⎡⎣⎢⎢⎢⎢W(1)1,1W(1)2,1W(1)3,1W(1)1,2W(1)2,2W(1)3,2W(1)1,3W(1)2,3W(1)3,3⎤⎦⎥⎥⎥⎥ a(1)=[a11,a12,a13]=xW(1)=[x1,x2]⎡⎣⎢⎢⎢⎢W(1)1,1W(1)2,1W(1)3,1W(1)1,2W(1)2,2W(1)3,2W(1)1,3W(1)2,3W(1)3,3⎤⎦⎥⎥⎥⎥ [y]=a(1)W(2)=[a11,a12,a13]⎡⎣⎢⎢⎢⎢W(2)1,1W(2)2,1W(2)3,1⎤⎦⎥⎥⎥⎥ 在Tensorflow中表示上述运算过程
a=tf.matmul(x,w1) y=tf.matmul(a,w2)神经网络参数及Tensorflow变量
- 变量的生成:使用
tf.Variable()命令,示意如下:
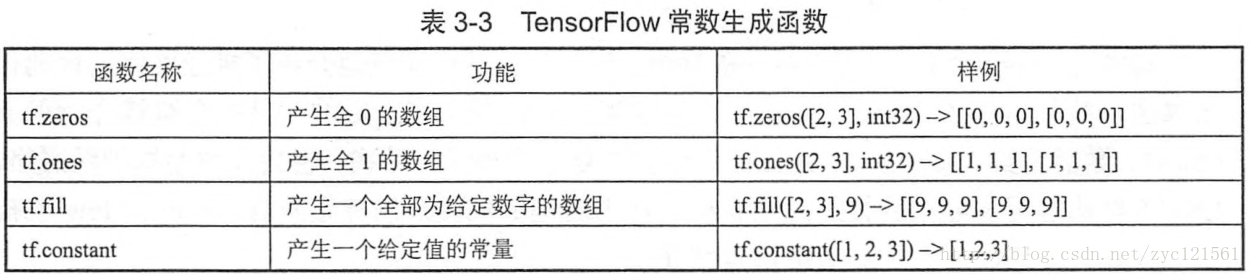
w=tf.Variable(tf.random_normal([2,3],mean=0,stddev=2))关于Tensorflow中的随机数生成,参考下表
以及常用来初始化变量的函数- 参数:偏置项(
bias)
biases=tf.Variable(tf.zeros([3]))- 一个综合性的前向传播例子
# 一个综合性的介绍前向传播及参数的例子 # author = yooongchun # time = 20180102 import tensorflow as tf w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) x=tf.constant([[0.7,0.9]]) a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: tf.global_variables_initializer().run() print(sess.run(y)) # 运算结果:[[ 3.95757794]]- 变量的生成:使用
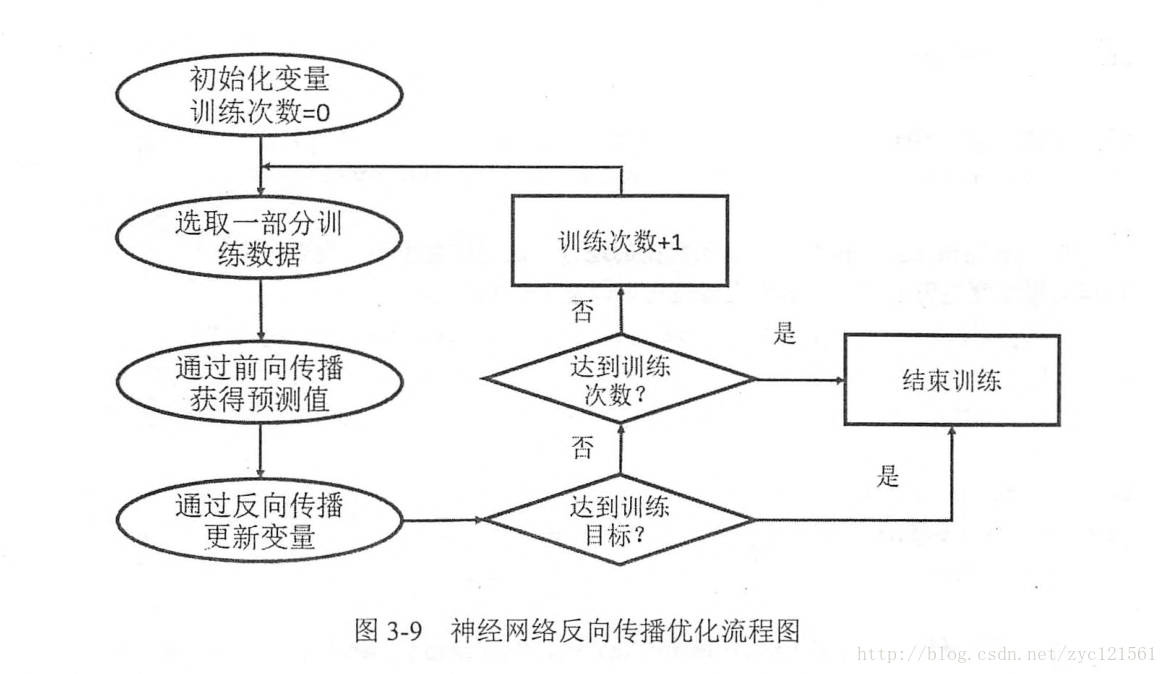
反向传播算法(
backpropagation):神经网络优化算法,如下示意图展示了一个完整的反向传播流程
对于输入,使用
placeholder来表示一个位置,而不是使用常量来表示,这避免了在迭代中生成大量数据占用过多空间的问题下面给出一个使用
placeholder来实现前向传播算法的实例:# TensorFlow 使用Placeholder的前向传播算法例子 # author = yooongchun # time = 20180102 import tensorflow as tf w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) x=tf.placeholder(tf.float32,shape=(1,2),name='input') a=tf.matmul(x,w1) y=tf.matmul(a,w2) with tf.Session() as sess: tf.global_variables_initializer().run() print(sess.run(y,feed_dict={x:[[0.7,0.9]]})) #结果:[[ 3.95757794]]损失函数:刻画训练值与真实值之间的差距,这里给出一个二分类问题中常用的损失函数:交叉熵(
cross entropy)cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0)))#交叉熵 learning_rate=0.001#学习率 train_step=tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)#反向传播优化一个完整的实例:在一个模拟数据集上展示完整的训练过程
# TensorFlow 在模拟训练集上展示完整的训练过程 # author = yooongchun # time = 20180102 import tensorflow as tf from numpy.random import RandomState # 定义训练集大小 batch_size=8 # 定义神经网络参数 w1=tf.Variable(tf.random_normal([2,3],stddev=1,seed=1)) w2=tf.Variable(tf.random_normal([3,1],stddev=1,seed=1)) # 输入的placeholder # None参数表示训练集数据放到了一个batch中 x=tf.placeholder(tf.float32,shape=(None,2),name='input') y_=tf.placeholder(tf.float32,shape=(None,1),name='y-input') # 定义神经网络前向传播过程 a=tf.matmul(x,w1) y=tf.matmul(a,w2) # 定义损失函数和反向传播算法 cross_entropy=-tf.reduce_mean(y_*tf.log(tf.clip_by_value(y,1e-10,1.0))) train_step=tf.train.AdamOptimizer(0.001).minimize(cross_entropy) # 生成随机数模拟数据集 rdm=RandomState(1) dataset_size=128 X=rdm.rand(dataset_size,2) # 定义标签 # 取值为0,1 Y=[[int(x1+x2<1)] for (x1,x2) in X] # 创建会话进行训练 with tf.Session() as sess: tf.global_variables_initializer().run() print('w1=',sess.run(w1),'\n','w2=',sess.run(w2)) # 设定训练轮数 STEPS=50001 for i in range(STEPS): start=(i*batch_size)%dataset_size end=min(start+batch_size,dataset_size) # 选择样本训练 sess.run(train_step,feed_dict={x:X[start:end],y_:Y[start:end]}) # 每1000步打印一次数据信息 if i%1000==0: total_cross_entropy=sess.run(cross_entropy,feed_dict={x:X,y_:Y}) print("After %d training step(s),cross entropy on all data is %g"%(i,total_cross_entropy)) # 训练完成后的参数 print('w1=',sess.run(w1),'\nw2=',sess.run(w2))结果如下:
w1= [ [-0.81131822 1.48459876 0.06532937] [-2.4427042 0.0992484 0.59122431]] w2= [ [-0.81131822] [ 1.48459876] [ 0.06532937]] After 0 training step(s),cross entropy on all data is 0.0674925 After 1000 training step(s),cross entropy on all data is 0.0163385 After 2000 training step(s),cross entropy on all data is 0.00907547 After 3000 training step(s),cross entropy on all data is 0.00714436 After 4000 training step(s),cross entropy on all data is 0.00578471 w1= [ [-1.96182752 2.58235407 1.68203771] [-3.46817183 1.06982315 2.11788988]] w2= [ [-1.82471502] [ 2.68546653] [ 1.41819501]]