目录:
5.1.8、reduceByKey(func, [num Tasks])
5.1.9、join(otherStream, [numTasks])
5.1.10、cogroup(otherStream, [numTasks])
5、SparkStreaming中的操作函数分析
根据Spark官方文档中的描述,在Spark Streaming应用中,一个DStream对象可以调用多种操作,主要分为以下几类。
- Transformations 普通的转换操作
- Window Operations 窗口转换操作
- Join Operations 合并操作
- Output Operations 输出操作
5.1、Transformations
普通的转换操作如下表所示:
| Transformation |
Meaning |
| map(func) |
利用方法func对源DStream中的元素分别进行处理,并返回一个新的DStream。 |
| flatMap(func) |
和map类似,不过每个输入元素可以被映射为0或多个输出元素。 |
| filter(func) |
选取被func方法计算后返回true的元素,形成新的DSteeam并返回。 |
| repartition(numPartitions) |
通过增加或减少分区数改变DStream的并行度。 |
| union(otherStream) |
将源DStream和otherDStream中所有元素取并集,形成一个新的DStream并返回。 |
| count() |
计算DStream中的每个RDD中的元素个数,每个RDD返回一个“单元素RDD”,这些单元素RDD组成新的DStream并返回。 |
| reduce(func) |
对DStream中每个RDD中的所有元素分别进行聚合,每个RDD生成一个单元素RDD,这些单元素RDD组成新的DStream并返回,func函数接受两个参数并有一个返回值,且func操作必须是associative和 commutative,这样才能支持并行计算。 |
| countByValue() |
对元素类型为K的DStream调用该方法,将返回类型为(K,Long)键值对的新DStream。“键”对应的“值”是该“键”在源DStream中每个RDD中的出现频率。 |
| reduceByKey(func, [numTasks]) |
当对元素类型为(K, V)对的DStream调用该方法,返回(K,V)对类型的新DStream,其中使用给定的reduce函数聚合每个键的值。注意:默认情况下,它使用Spark的默认并行任务数(本地模式下为2,群集模式中的并行数由属性spark.default.parallelism指定)进行分组。您可以传递一个可选的numTasks参数来设置task的数量。 |
| join(otherStream, [numTasks]) |
当源DStream类型为(K, V),otherStream类型为(K, W)时,返回一个新的类型为(K, (V,W))的DStream。 |
| cogroup(otherStream, [numTasks]) |
当源DStream类型为(K, V),otherStream类型为(K, W)时,返回一个新的类型为(K, Seq[V], Seq[W])的DStream。 |
| transform(func) |
通过对源DStream的每个RDD应用RDD-to-RDD函数来返回一个新的DStream。这可以用于对DStream进行任意RDD操作。 |
| updateStateByKey(func) |
返回一个新的“state”DStream,其中通过对key的先前状态和新的values应用给定的方法func,将计算结果用来更新每个key的状态。这可以用于维护每个key的任意的状态数据。 |
5.1.1、map(func)
map操作需要传入一个函数当做参数,具体调用形式为:
JavaDStream<String> b = a.map(func);
主要作用是,对DStream对象a,将func函数作用到a中的每个元素上并生成一个新的元素,得到DStream对象b中包含的这些新元素。
下面示例代码的作用是,在接收到的一行消息后面拼接一个”_NEW”字符串。
JavaDStream<String> linesNew = lines.map(line -> line + "_NEW");
服务端:
![]()
客户端:

注意与接下来的flatMap操作比较。
5.1.2、flatMap(func)
类似于上面的map操作,具体调用形式为:
JavaDStream<String> b = a.flatMap(func);
主要作用是,对DStream对象a,将func函数作用到a中的每个元素上并生成0个或多个新元素,得到的DStream对象b包含这些新的元素。
下面示例代码的作用是,在接收到的一行消息lines后,将lines根据空格进行分割,分割成若干个单词。
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
服务端:
![]()
客户端:

map和flatMap的区别:
map函数会对每一条输入进行指定的操作,然后为每一条输入返回一个对象。
而flatMap函数则是两个操作的集合——正是“先映射后扁平化”:
操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象。
操作2:最后将所有对象合并为一个对象。

5.1.3、filter(func)
filter传入一个func函数,具体调用形式为:
JavaDStream<String> b = a.filter(func);
对DStream对象a中的每一个元素,应用func方法进行计算,如果func返回结果为true,则保留该元素,否则丢弃该元素,返回一个新的DStream对象b。
下面示例代码中,对words进行判断,去除”hello”这个单词。
JavaDStream<String> filterWords = words.filter(word -> !word.equals("hello"));
服务端:
![]()
客户端:

5.1.4、union(otherStream)
这个操作将两个DStream进行合并,生成一个包含着两个DStream中所有元素的的新DStream对象。
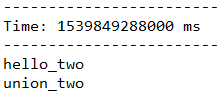
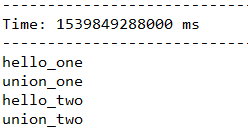
下面代码,首先将输入的每个单词后面分别拼接一个”_one”和”_two”,最后将这两个DStream合并成一个新的DStream。
JavaDStream<String> wordsOne = words.map(word -> word + "_one");
JavaDStream<String> wordsTwo = words.map(word -> word + "_two");
JavaDStream<String> unionWords = wordsOne.union(wordsTwo);
服务端:
![]()
客户端:

结果:

5.1.5、count()
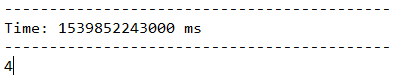
统计DStream中每个RDD包含的元素的个数,得到一个新的DStream,这个DStream只包含一个元素,这个元素是对语句单词统计数值。
JavaDStream<Long> wordsCount = words.count();
运行结果如下,一行输入4个单词,打印的结果也为4。
服务端:
![]()
客户端:

结果:
5.1.6、reduce(func)
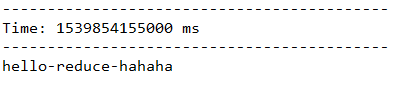
返回一个包含一个元素的DStream,传入的func方法会作用在调用者的每个元素上,将其中的元素顺次的两两进行计算。
下面的代码,将每一个单词用"-"符号进行拼接。
服务端:
![]()
客户端:

结果:
5.1.7 countByValue()
某个DStream中的元素类型为K,调用这个方法后,返回的DStream的元素为(K, Long)对,后面这个Long值是原DStream中每个RDD元素key出现的频率。
以下代码统计words中不同单词的个数:
JavaDStream<Long> countByValueWords = words.countByValue();
服务端:
![]()
客户端:

结果:
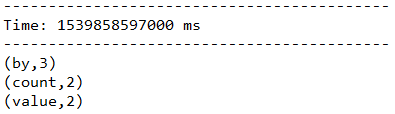
5.1.8、reduceByKey(func, [num Tasks])
调用这个操作的DStream是以(K, V)的形式出现,返回一个新的元素格式为(K, V)的DStream。返回结果中,K为原来的K,V是由K经过传入func计算得到的。还可以传入一个并行计算的参数,在local模式下,默认为2。在其他模式下,默认值由参数spark.default.parallelism确定。
下面代码将words转化成(word, 1)的形式,再以单词为key,个数为value,进行word count。
JavaPairDStream<String, Integer> pairs = words.mapToPair(word -> new Tuple2<>(word, 1));
JavaPairDStream<String, Integer> wordCounts = pairs.reduceByKey((a,b) -> (a + b));
服务端:
![]()
客户端:

结果:
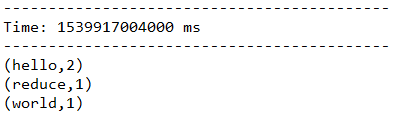
5.1.9、join(otherStream, [numTasks])
由一个DStream对象调用该方法,元素内容为(K, V),传入另一个DStream对象,元素内容为(K, W),返回的DStream中包含的内容是(K, (V, W))。这个方法也可以传入一个并行计算的参数,该参数与reduceByKey中是相同的。
下面代码中,首先将words转化成(word, (word + “_one”))和(word, (word + “_two”))的形式,再以word为key,将后面的value合并到一起。
服务端:
![]()
客户端:

结果:

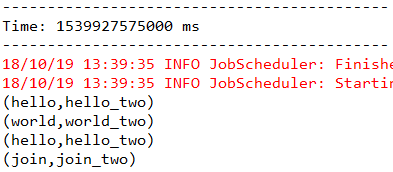

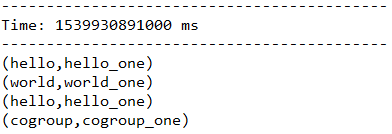
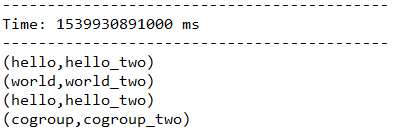
5.1.10、cogroup(otherStream, [numTasks])
由一个DStream对象调用该方法,元素内容为(k, V),传入另一个DStream对象,元素内容为(k, W),返回的DStream中包含的内容是(k, (Seq[V], Seq[W]))。这个方法也可以传入一个并行计算的参数,该参数与reduceByKey中是相同的。
下面代码首先将words转化成(word, (word + "_one"))和(word, (word + "_two"))的形式,再以word为key,将后面的value合并到一起。
服务端:
![]()
客户端:

结果:
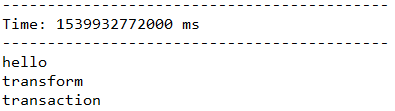
5.1.11、transform(func)
在Spark-Streaming官方文档中提到,DStream的transform操作极大的丰富了DStream上能够进行的操作内容。
使用transform操作后,除了可以使用DStream提供的一些转换方法之外,还能够直接调用任意的调用RDD上的操作函数。
比如下面的代码中,使用transform完成将一行语句分割成单词的功能。
JavaDStream<String> words = lines.transform(line -> line.
flatMap(a -> Arrays.asList(a.split(" ")).iterator()
));
服务端:
![]()
客户端:

结果:
5.1.12、updateStateByKey(func)
updateStateByKey操作以DStream中的数据进行按key做reduce操作,然后对各个批次的数据进行累加。在有新的数据持续更新时保持任意的状态。要使用这个操作要操作两个步骤。
1、 定义状态:可以是任意的数据类型。
2、 定义状态更新函数:使用更新函数来指定如何使用先前状态和输入流中的新值更新状态。
从输入流中的新值更新状态。对于有状态操作,要不断的把当前和历史的时间切片的RDD累加计算,随着时间的流失,计算的数据规模会变得越来越大。
在每个批处理中,Spark都将对所有现有键应用状态更新函数,而不管它们在批处理中是否有新数据。如果update函数返回None,那么key-value对将被消除。
让我们举个例子来说明这一点。假设您希望在文本数据流中维护每个单词的运行计数。在这里,运行计数是状态,它是一个整数。我们将更新功能定义为:
Function2<List<Integer>, Optional<Integer>, Optional<Integer>> updateFunction =
(values, state) -> {
Integer newSum = ... // 添加新值与之前的运行计数以获得新计数
return Optional.of(newSum);
};这是在一个包含单词的DStream上应用(比如说,在上述示例中包含(word,1)键值对的DStream。
将为每个单词调用更新函数,其中newValues具有1的顺序(来自(word, 1)键值对)具有runningCount持有先前的计数。
需注意:使用updateStateByKey需要配置检查点目录。
即如果要不断的更新每一个key的state,就一定会涉及到状态的保存和容错,这个时候就需要开启checkpoint机制和功能,需要说明的是checkpoint的数据可以保存在一些存储在文件系统上的内容。例如:程序未处理的但已经拥有状态的数据。
报错解决问题做checkpoint,开启checkpoint机制,把checkpoint中的数据放在这里设置的目录中。生产环境下一般放在HDFS中。
jssc.checkpoint("hdfs://192.1.101.61:9000/in/ch");