JOB
启动JobScheduler
在JobScheduler的启动过程中,启动了ReceiverTracker和JobGenerator。
def start(): Unit = synchronized {
// 如果JobScheduler已经启动,则退出
if (eventLoop != null) return // scheduler has already been started
logDebug("Starting JobScheduler")
eventLoop = new EventLoop[JobSchedulerEvent]("JobScheduler") {
override protected def onReceive(event: JobSchedulerEvent): Unit = processEvent(event)
override protected def onError(e: Throwable): Unit = reportError("Error in job scheduler", e)
}
eventLoop.start()
// attach rate controllers of input streams to receive batch completion updates
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
// 启动Spark Streaming的消息总线
listenerBus.start()
// 实例化ReceiverTracker
receiverTracker = new ReceiverTracker(ssc)
inputInfoTracker = new InputInfoTracker(ssc)
val executorAllocClient: ExecutorAllocationClient = ssc.sparkContext.schedulerBackend match {
case b: ExecutorAllocationClient => b.asInstanceOf[ExecutorAllocationClient]
case _ => null
}
executorAllocationManager = ExecutorAllocationManager.createIfEnabled(
executorAllocClient,
receiverTracker,
ssc.conf,
ssc.graph.batchDuration.milliseconds,
clock)
executorAllocationManager.foreach(ssc.addStreamingListener)
// 启动ReceiverTracker和JobGenerator
receiverTracker.start()
jobGenerator.start()
executorAllocationManager.foreach(_.start())
logInfo("Started JobScheduler")
}
1. 启动ReceiverTracker
启动receiverTracker先调用ReceiverTracker.launchReceivers方法。该方法会向ReceiverTrackerEndpoint终端点发送StartAllReceiverr消息,通知其分发并启动所有流数据接收器Receiver
/** Start the endpoint and receiver execution thread. */
def start(): Unit = synchronized {
if (isTrackerStarted) {
throw new SparkException("ReceiverTracker already started")
}
if (!receiverInputStreams.isEmpty) {
endpoint = ssc.env.rpcEnv.setupEndpoint(
"ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv))
if (!skipReceiverLaunch)
// 调用ReceiverTracker.launchReceivers方法。
launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
}
}
1.1 ReceiverTracker向ReceiverTrackerEndpoint发送消息
/**
* Get the receivers from the ReceiverInputDStreams, distributes them to the
* worker nodes as a parallel collection, and runs them.
*/
private def launchReceivers(): Unit = {
val receivers = receiverInputStreams.map { nis =>
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
}
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
endpoint.send(StartAllReceivers(receivers))
}
1.2 ReceiverTrackerEndpoint收到消息
ReceiverTrackerEndpoint收到StartAllReceivers消息后,具体做了以下工作:
override def receive: PartialFunction[Any, Unit] = {
// Local messages
case StartAllReceivers(receivers) =>
println("======ReceiverTracker--->receive()")
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
......
}
1.2.1 获取executor列表
/**
* Get the list of executors excluding driver
*/
private def getExecutors: Seq[ExecutorCacheTaskLocation] = {
println("======ReceiverTracker--->getExecutors()")
if (ssc.sc.isLocal) {
println("======isLocal======")
val blockManagerId = ssc.sparkContext.env.blockManager.blockManagerId
println(Seq(ExecutorCacheTaskLocation(blockManagerId.host, blockManagerId.executorId)))
Seq(ExecutorCacheTaskLocation(blockManagerId.host, blockManagerId.executorId))
} else {
ssc.sparkContext.env.blockManager.master.getMemoryStatus.filter { case (blockManagerId, _) =>
blockManagerId.executorId != SparkContext.DRIVER_IDENTIFIER // Ignore the driver location
}.map { case (blockManagerId, _) =>
ExecutorCacheTaskLocation(blockManagerId.host, blockManagerId.executorId)
}.toSeq
}
}
如果是本地模式
如果不是本地模式
- 调用BlockManagerMaster的getMemoryStatus方法。返回每个block manager的内存状态
返回值的类型是:Map[BlockManagerId, (Long1, Long2)] 返回值的类型是:Map[BlockManagerId, (Long1, Long2)]
Long1: 为该block manager分配的最大内存
Long2: 剩余的内存 - 进行过滤。过滤掉driver上的的Map[BlockManagerId, (Long1, Long2)] ,只保留worker上的Map[BlockManagerId, (Long1, Long2)]
- 通过map操作,把所有worker上的Map[BlockManagerId, (Long1, Long2)] ,转换成ExecutorCacheTaskLocation
- 把所有的ExecutorCacheTaskLocation(IP+Port+executorID)以序列形式返回。
1.2.2 调用scheduleReceivers方法,启动Receiver
receiver有优先位置如何启动?
receiver没有优先位置如何启动?
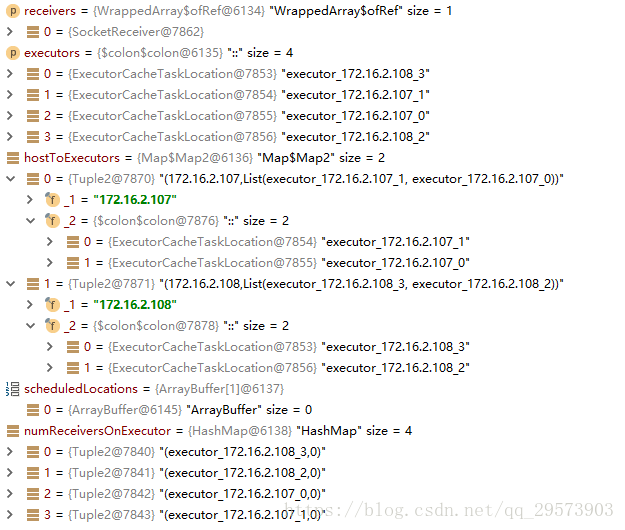
// For those receivers that don't have preferredLocation, make sure we assign at least one
// executor to them.
for (scheduledLocationsForOneReceiver <- scheduledLocations.filter(_.isEmpty)) {
// Select the executor that has the least receivers
val (leastScheduledExecutor, numReceivers) = numReceiversOnExecutor.minBy(_._2)
scheduledLocationsForOneReceiver += leastScheduledExecutor
numReceiversOnExecutor(leastScheduledExecutor) = numReceivers + 1
}
启动Receiver
首先会为每一个receiver按照一定的策略指定一个executor,然后调用startReceiver(receiver, executors)在指定的executor上启动receiver
/**
* Start a receiver along with its scheduled executors
*/
private def startReceiver(
receiver: Receiver[_],
scheduledLocations: Seq[TaskLocation]): Unit = {
......
val checkpointDirOption = Option(ssc.checkpointDir)
val serializableHadoopConf =
new SerializableConfiguration(ssc.sparkContext.hadoopConfiguration)
// Function to start the receiver on the worker node
val startReceiverFunc: Iterator[Receiver[_]] => Unit =
(iterator: Iterator[Receiver[_]]) => {
if (!iterator.hasNext) {
throw new SparkException(
"Could not start receiver as object not found.")
}
if (TaskContext.get().attemptNumber() == 0) {
val receiver = iterator.next()
assert(iterator.hasNext == false)
val supervisor = new ReceiverSupervisorImpl(
receiver, SparkEnv.get, serializableHadoopConf.value, checkpointDirOption)
supervisor.start()
supervisor.awaitTermination()
} else {
// It's restarted by TaskScheduler, but we want to reschedule it again. So exit it.
}
}
// Create the RDD using the scheduledLocations to run the receiver in a Spark job
val receiverRDD: RDD[Receiver[_]] =
if (scheduledLocations.isEmpty) {
ssc.sc.makeRDD(Seq(receiver), 1)
} else {
val preferredLocations = scheduledLocations.map(_.toString).distinct
ssc.sc.makeRDD(Seq(receiver -> preferredLocations))
}
receiverRDD.setName(s"Receiver $receiverId")
ssc.sparkContext.setJobDescription(s"Streaming job running receiver $receiverId")
ssc.sparkContext.setCallSite(Option(ssc.getStartSite()).getOrElse(Utils.getCallSite()))
val future = ssc.sparkContext.submitJob[Receiver[_], Unit, Unit](
receiverRDD, startReceiverFunc, Seq(0), (_, _) => Unit, ())
// We will keep restarting the receiver job until ReceiverTracker is stopped
future.onComplete {
case Success(_) =>
if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
case Failure(e) =>
if (!shouldStartReceiver) {
onReceiverJobFinish(receiverId)
} else {
logError("Receiver has been stopped. Try to restart it.", e)
logInfo(s"Restarting Receiver $receiverId")
self.send(RestartReceiver(receiver))
}
}(ThreadUtils.sameThread)
logInfo(s"Receiver ${receiver.streamId} started")
}