读取excel表
要读取的excel表的如下所示
读取excel表的代码如下:
dtrcolumns = ['year-month-day','start-time','end-time','user-id','gender','age'] #要读取的excel表的属性的列表,可以只读取一部分 path = '....xlsx' #excel表的路径 frame = pd.read_excel(path,names=dtrcolumns) #读取excel文件到Frame多个相同属性的Frame可以用concat连接起来
for path in pathlist: frame = pd.read_excel(path,names=dtrcolumns) dtrpieces.append(frame) dtr_primary = pd.concat(dtrpieces,ignore_index=True)用逻辑判断来过滤掉某些数据记录,去重
过滤掉某些属性不符合要求的记录,如缺失,异常值
dtr_notnull = dtr_primary[dtr_primary['gender'].notnull()&dtr_primary['age'].notnull()&(dtr_primary['age']>0)&(dtr_primary['age']<90)]根据某些列或列组合来去除重复记录
dtr_user_gender_age = dtr_notnull[['user-id','gender','age']].drop_duplicates()某些键值(如本数据中的用户ID)的集合运算
set_dtr_userid = set(dtr_user['user-id']) #用户ID的集合 set_cdr_userid = set(cdr_user['user-id']) user_target = set_dtr_userid & set_cdr_userid # #两个用户ID集的交集接下来要用到的两个Frame
- groupby函数

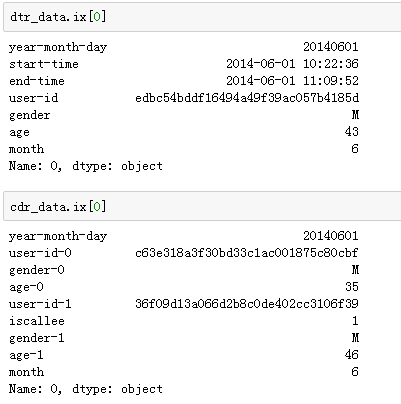
user_df = dtr_data[['user-id','gender','age']].drop_duplicates() #以user-id,gender和age为键值,生成新的Frame,即user_df
cdr_in = cdr_data[cdr_data['iscallee']==1].groupby('user-id-0').size()#将cdr_data中满足一定要求的记录摘出来,然后按user-id-0分组,统计每组的个数,即满足要求的记录中每个user的记录的个数。
cdr_in.name = 'in_sum' #cdr_in是个Series,这一行给其命名。join 函数
五种 JOIN 方式: 内连接(INNER), 全外连接(FULL OUTER), 左外连接(LEFT OUTER,简称左连接), 右外连接(RIGHT OUTER,简称右连接)和交叉连接(CROSS),见链接.user_df = user_df.join(cdr_in,on='user-id',how = 'left') #接入电话数映射map(自定义函数)
划分
def age_class(n): # 对年龄进行划分的函数 if n < 25: return 'Y' # Young (18-24), elif n < 35: return 'YA' # Young-Adult (25-34) elif n < 50: return 'MA' # Middle-Age (35-49) else: return 'S' # Senior (> 49). Ageclass = user_df.age.map(age_class) Ageclass.name = 'age_class' user_df['age_class'] = Ageclass #年龄的四个分类特征更新
def ymd_frome_timestamp(timestamp): # 将时间戳字符串“2014-01-03”变成 “20140103” return int(str(timestamp)[:10].replace('-','')) # 用户过夜上网的频率 is_overnight = dtr_data['start-time'].map(ymd_frome_timestamp)!= dtr_data['year-month-day'] dtr_data['is_overnight'] = is_overnight
根据属性名删除某一列
user_df = user_df.drop('in_M_sum',axis=1)#透视图
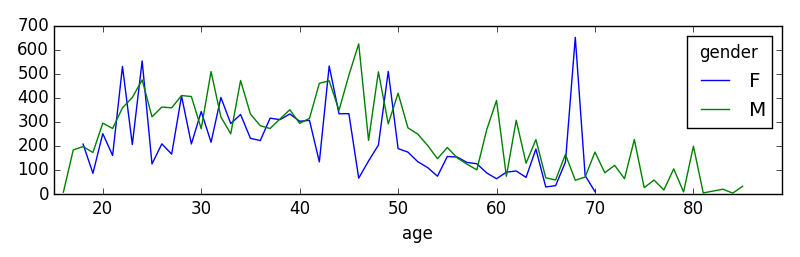
user_df.pivot_table(values='in_sum',index='age',columns='gender',aggfunc=np.std).plot(kind = 'line')