前记: 深度学习的发展使得在此之前以机器学习为主流算法的相关实现变得简单,而且准确率更高,效果更好,在图像检索这一块儿,目前有谷歌的以图搜图,百度的以图搜图,而百度以图搜图的关键技术叫做“感知哈希算法”,这是一个很简单且快速的算法,其原理在于针对每一张图片都生成一个特定的“指纹”,然后采取一种相似度的度量方式得出两张图片的近似程度,具体见之前的一篇博客哈希算法-图片相似度计算。
而深度学习在图像领域的快速发展,在于它能学习到图片的相关特征,评价一个深度模型的好坏往往在于它学习到有用的特征程度的多少,在提取特征这方面而言,目前神经网络有着不可替代的优势。而图像检索往往也是基于图像的特征比较,看特征匹配的程度有多少,从而检索出相似度高的图片。
基于vgg16网络提取图像特征
我们都知道,vgg网络在图像领域有着广泛的应用,后续许多层次更深,网络更宽的模型都是基于此扩展的,vgg网络能很好的提取到图片的有用特征,本次实现是基于Keras实现的,提取的是最后一层卷积特征。
提取特征
# extract_cnn_vgg16_keras.py
# -*- coding: utf-8 -*-
import numpy as np
from numpy import linalg as LA
from keras.applications.vgg16 import VGG16
# from keras.applications.resnet50 import ResNet50
# from keras.applications.densenet import DenseNet121
from keras.preprocessing import image
from keras.applications.vgg16 import preprocess_input as preprocess_input_vgg
# from keras.applications.resnet50 import preprocess_input as preprocess_input_resnet
# from keras.applications.densenet import preprocess_input as preprocess_input_densenet
class VGGNet:
def __init__(self):
# weights: 'imagenet'
# pooling: 'max' or 'avg'
# input_shape: (width, height, 3), width and height should >= 48
self.input_shape = (224, 224, 3)
self.weight = 'imagenet'
self.pooling = 'max'
# include_top:是否保留顶层的3个全连接网络
# weights:None代表随机初始化,即不加载预训练权重。'imagenet'代表加载预训练权重
# input_tensor:可填入Keras tensor作为模型的图像输出tensor
# input_shape:可选,仅当include_top=False有效,应为长为3的tuple,指明输入图片的shape,图片的宽高必须大于48,如(200,200,3)
#pooling:当include_top = False时,该参数指定了池化方式。None代表不池化,最后一个卷积层的输出为4D张量。‘avg’代表全局平均池化,‘max’代表全局最大值池化。
#classes:可选,图片分类的类别数,仅当include_top = True并且不加载预训练权重时可用。
self.model_vgg = VGG16(weights = self.weight, input_shape = (self.input_shape[0], self.input_shape[1], self.input_shape[2]), pooling = self.pooling, include_top = False)
# self.model_resnet = ResNet50(weights = self.weight, input_shape = (self.input_shape[0], self.input_shape[1], self.input_shape[2]), pooling = self.pooling, include_top = False)
# self.model_densenet = DenseNet121(weights = self.weight, input_shape = (self.input_shape[0], self.input_shape[1], self.input_shape[2]), pooling = self.pooling, include_top = False)
self.model_vgg.predict(np.zeros((1, 224, 224 , 3)))
# self.model_resnet.predict(np.zeros((1, 224, 224, 3)))
# self.model_densenet.predict(np.zeros((1, 224, 224, 3)))
'''
Use vgg16/Resnet model to extract features
Output normalized feature vector
'''
#提取vgg16最后一层卷积特征
def vgg_extract_feat(self, img_path):
img = image.load_img(img_path, target_size=(self.input_shape[0], self.input_shape[1]))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input_vgg(img)
feat = self.model_vgg.predict(img)
# print(feat.shape)
norm_feat = feat[0]/LA.norm(feat[0])
return norm_feat
#提取resnet50最后一层卷积特征
def resnet_extract_feat(self, img_path):
img = image.load_img(img_path, target_size=(self.input_shape[0], self.input_shape[1]))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input_resnet(img)
feat = self.model_resnet.predict(img)
# print(feat.shape)
norm_feat = feat[0]/LA.norm(feat[0])
return norm_feat
#提取densenet121最后一层卷积特征
def densenet_extract_feat(self, img_path):
img = image.load_img(img_path, target_size=(self.input_shape[0], self.input_shape[1]))
img = image.img_to_array(img)
img = np.expand_dims(img, axis=0)
img = preprocess_input_densenet(img)
feat = self.model_densenet.predict(img)
# print(feat.shape)
norm_feat = feat[0]/LA.norm(feat[0])
return norm_feat
将特征以及对应的文件名保存为h5文件
# index.py
# -*- coding: utf-8 -*-
import os
import h5py
import numpy as np
import argparse
from extract_cnn_vgg16_keras import VGGNet
'''
Returns a list of filenames for all jpg images in a directory.
'''
def get_imlist(path):
return [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
'''
Extract features and index the images
'''
if __name__ == "__main__":
database = './data/picture'
index = 'vgg_featureCNN.h5'
img_list = get_imlist(database)
print("--------------------------------------------------")
print(" feature extraction starts")
print("--------------------------------------------------")
feats = []
names = []
model = VGGNet()
for i, img_path in enumerate(img_list):
norm_feat = model.vgg_extract_feat(img_path) #修改此处改变提取特征的网络
img_name = os.path.split(img_path)[1]
feats.append(norm_feat)
names.append(img_name)
print("extracting feature from image No. %d , %d images in total" %((i+1), len(img_list)))
feats = np.array(feats)
# print(feats)
# directory for storing extracted features
# output = args["index"]
output = index
print("--------------------------------------------------")
print(" writing feature extraction results ...")
print("--------------------------------------------------")
h5f = h5py.File(output, 'w')
h5f.create_dataset('dataset_1', data = feats)
# h5f.create_dataset('dataset_2', data = names)
h5f.create_dataset('dataset_2', data = np.string_(names))
h5f.close()
选一张测试图片测试检索效果
相似度采用余弦相似度度量
# test.py
# -*- coding: utf-8 -*-
from extract_cnn_vgg16_keras import VGGNet
import numpy as np
import h5py
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import argparse
query = './data/picture/bird.jpg'
index = 'vgg_featureCNN.h5'
result = './data/picture'
# read in indexed images' feature vectors and corresponding image names
h5f = h5py.File(index,'r')
# feats = h5f['dataset_1'][:]
feats = h5f['dataset_1'][:]
print(feats)
imgNames = h5f['dataset_2'][:]
print(imgNames)
h5f.close()
print("--------------------------------------------------")
print(" searching starts")
print("--------------------------------------------------")
# read and show query image
# queryDir = args["query"]
queryImg = mpimg.imread(query)
plt.title("Query Image")
plt.imshow(queryImg)
plt.show()
# init VGGNet16 model
model = VGGNet()
# extract query image's feature, compute simlarity score and sort
queryVec = model.vgg_extract_feat(query) #修改此处改变提取特征的网络
print(queryVec.shape)
print(feats.shape)
scores = np.dot(queryVec, feats.T)
rank_ID = np.argsort(scores)[::-1]
rank_score = scores[rank_ID]
# print (rank_ID)
print (rank_score)
# number of top retrieved images to show
maxres = 3 #检索出三张相似度最高的图片
imlist = []
for i,index in enumerate(rank_ID[0:maxres]):
imlist.append(imgNames[index])
# print(type(imgNames[index]))
print("image names: "+str(imgNames[index]) + " scores: %f"%rank_score[i])
print("top %d images in order are: " %maxres, imlist)
# show top #maxres retrieved result one by one
for i,im in enumerate(imlist):
image = mpimg.imread(result+"/"+str(im, 'utf-8'))
plt.title("search output %d" %(i+1))
plt.imshow(image)
plt.show()
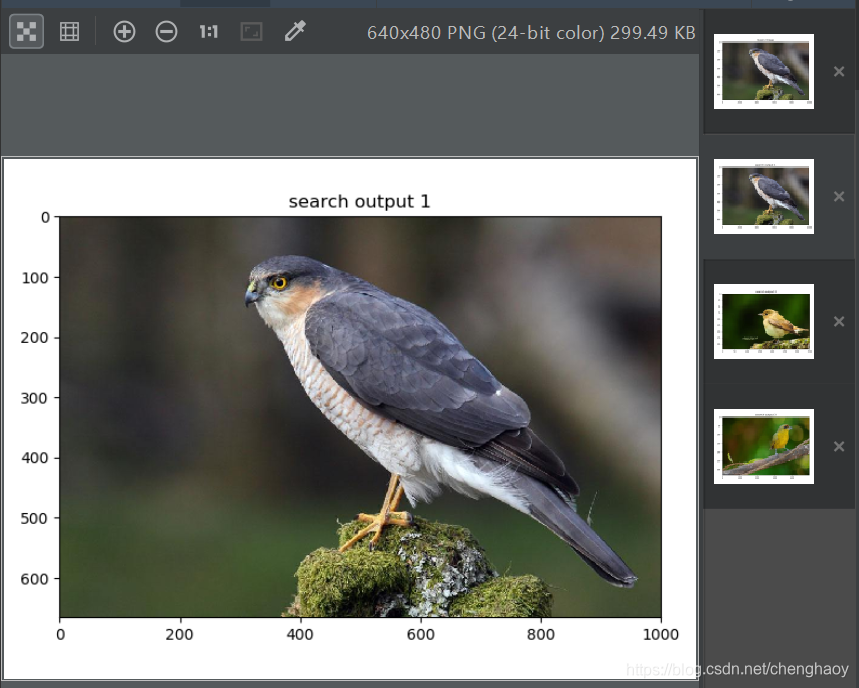
以一张小鸟的图片为例测试结果如下:

第一张为测试图片,后面三张为检索图片,可以看出效果相当好了。
如果想用Resnet或者Densenet提取特征,只需针对上述代码做出相应的修改,去掉注释修改部分代码即可。
参考文献:
https://github.com/willard-yuan/flask-keras-cnn-image-retrieval
https://www.zhihu.com/question/29467370
http://yongyuan.name/blog/layer-selection-and-finetune-for-cbir.html