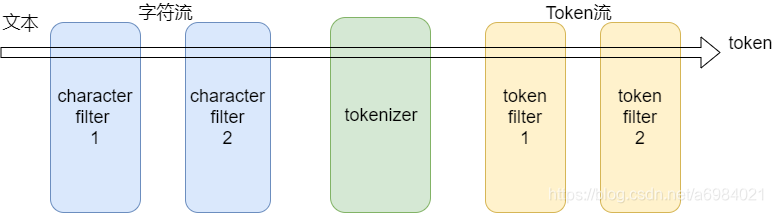
在Java开发中无论是内置的分析器(analyzer),还是自定义的分析器(analyzer),都由三种构件块组成的:character filters , tokenizers , token filters。
内置的analyzer将这些构建块预先打包到适合不同语言和文本类型的analyzer中。Character filters (字符过滤器)字符过滤器以字符流的形式接收原始文本,并可以通过添加、删除或更改字符来转换该流。
举例来说,一个字符过滤器可以用来把阿拉伯数字(٠١٢٣٤٥٦٧٨٩)转成成Arabic-Latin的等价物(0123456789)。
一个分析器可能有0个或多个字符过滤器,它们按顺序应用。
(PS:类似Servlet中的过滤器,或者拦截器,想象一下有一个过滤器链)Tokenizer (分词器)一个分词器接收一个字符流,并将其拆分成单个token (通常是单个单词),并输出一个token流。例如,一个whitespace分词器当它看到空白的时候就会将文本拆分成token。
它会将文本“Quick brown fox!”转换为[Quick, brown, fox!](PS:Tokenizer 负责将文本拆分成单个token ,这里token就指的就是一个一个的单词。就是一段文本被分割成好几部分,相当于Java中的字符串的 split )分词器还负责记录每个term的顺序或位置,以及该term所表示的原单词的开始和结束字符偏移量。
(PS:文本被分词后的输出是一个term数组)一个分析器必须只能有一个分词器Token filters (token过滤器)token过滤器接收token流,并且可能会添加、删除或更改tokens。
例如,一个lowercase token filter可以将所有的token转成小写。stop token filter可以删除常用的单词,比如 the 。
synonym token filter可以将同义词引入token流。
不允许token过滤器更改每个token的位置或字符偏移量。一个分析器可能有0个或多个token过滤器,它们按顺序应用。
小结&回顾analyzer(分析器)是一个包,这个包由三部分组成,分别是:character filters (字符过滤器)、tokenizer(分词器)、token filters(token过滤器)一个analyzer可以有0个或多个character filters一个analyzer有且只能有一个tokenizer一个analyzer可以有0个或多个token filterscharacter filter 是做字符转换的,它接收的是文本字符流,输出也是字符流tokenizer 是做分词的,它接收字符流,输出token流(文本拆分后变成一个一个单词,这些单词叫token)token filter 是做token过滤的,它接收token流,输出也是token流由此可见,整个analyzer要做的事情就是将文本拆分成单个单词,文本 ----> 字符 ----> token
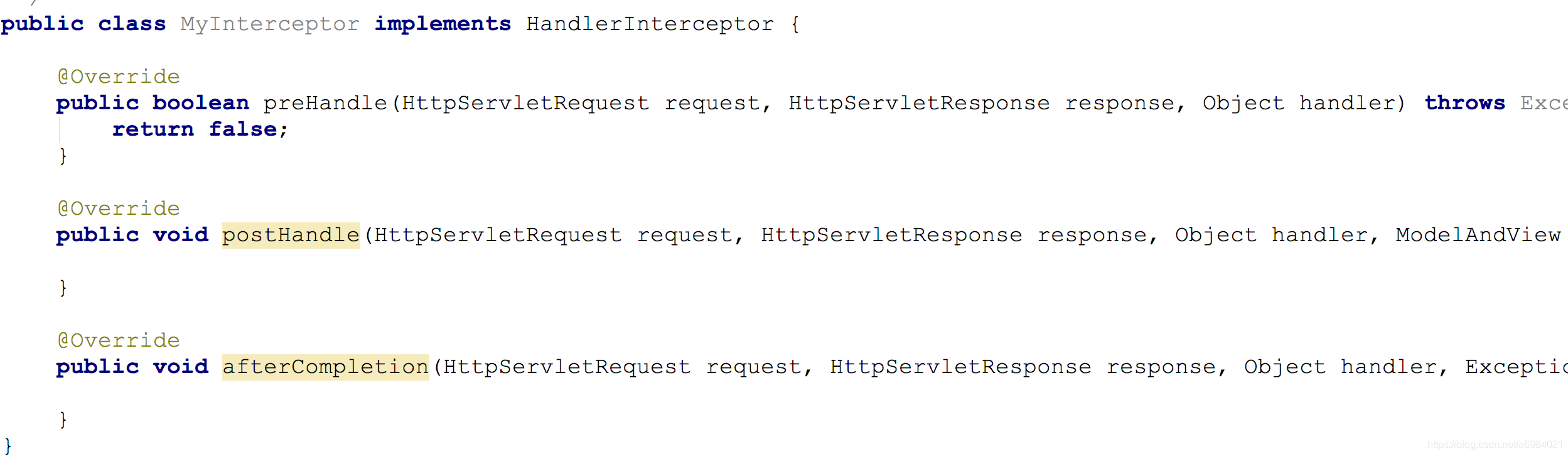
这就好比是拦截器

文章来自:https://www.itjmd.com/news/show-5316.html
Java开发中的Elasticsearch分词器的定义与用法一
猜你喜欢
转载自blog.csdn.net/a6984021/article/details/85598853
今日推荐
周排行