Lucene中的基本概念:
-
索引(Index):文档的集合组成索引。和一般的数据库不一样,Lucene不支持定义主键,但Solr支持。
-
为了方便索引大量的文档,Lucene中的一个索引分成若干个子索引,叫做段(segment)。段中包含了一些可搜索的文档。
-
文档(Document):代表索引库中的一条记录。一个文档可以包含多个列(Field)。和一般的数据库不一样,一个文档的一个列可以有多个值。例如一篇文档既可以属于互联网类,又可以属于科技类。
-
列(Field):命名的词的集合。
-
词(Term) :由两个值定义——词语和这个词语所出现的列。
-
倒排索引是基于词(Term)的搜索。
要学习搜索引擎,就需要了解倒排索引(倒排索引的定义请自行谷歌百度),首先我们来讲一下倒排索引的原理:

文档1: When in Rome, do as the Romans do. 文档2: When do you come back from Rome?
停用词: in, as, the, from

Lucene的整体结构:
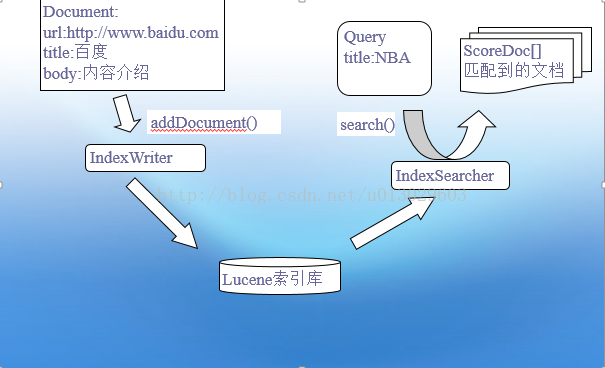
索引相关类:

-
一个Document代表索引库中的一条记录。一个Document可以包含多个列。例如一篇文章可以包含“标题”、“正文”、“修改时间”等field,创建这些列对象以后,可以通过Document的add方法增加这些列到Document实例。
-
-
一段有意义的文字通过Analyzer分割成一个个的词语后写入到索引库。
创建索引:
|
1
2
3
4
5
6
7
8
9
10
|
//创建新的索引库
IndexWriter index =
new
IndexWriter(indexDirectory,
//索引库存放的路径
new
StandardAnalyzer(Version.LUCENE_CURRENT),
true
,
//新建索引库
IndexWriter.MaxFieldLength.UNLIMITED);
//不限制列的长度
File dir =
new
File(sourceDir);
indexDir(dir);
//索引sourceDir路径下的文件
index.optimize();
//索引优化
index.close();
//关闭索引库
|
向索引增加文档:
一个索引和一个数据库表类似,但是数据库中是先定义表结构后使用。但Lucene在放数据的时候定义字段结构。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
Document doc =
new
Document();
//创建网址列
Field f =
new
Field(“url”, news.URL ,
//news.URL 存放url地址的值
Field.Store.YES, Field.Index. NOT_ANALYZED,
//不分词
Field.TermVector.NO);
doc.add(f);
//创建标题列
f =
new
Field(“title”, news.title ,
//news.title 存放标题的值
Field.Store.YES, Field.Index.ANALYZED,
//分词
Field.TermVector.WITH_POSITIONS_OFFSETS);
//存Token位置信息
doc.add(f);
//创建内容列
f =
new
Field(“body”, news.body ,
//news.body 存放内容列的值
Field.Store.YES, Field.Index. ANALYZED,
//分词
Field.TermVector.WITH_POSITIONS_OFFSETS);
//存Token位置信息
doc.add(f);
index.addDocument(doc);
//把一个文档加入索引
|
搜索:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
IndexSearcher isearcher =
new
IndexSearcher(directory,
//索引路径
true
);
//只读
//搜索标题列
QueryParser parser =
new
QueryParser(Version.LUCENE_CURRENT,
"title"
, analyzer);
Query query = parser.parse(“NBA”);
//搜索NBA这个词
//返回前1000条搜索结果
ScoreDoc[] hits = isearcher.search(query,
1000
).scoreDocs;
//遍历结果
for
(
int
i =
0
; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
System.out.println(hitDoc.get(
"title"
));
}
isearcher.close();
directory.close();
|
查询语法:
加权 solr^4 lucene
修饰符 + - NOT
+solr lucene
布尔操作符 OR AND
(solr OR lucene) AND user
按域查询
title:NBA
QueryParser:
-
QueryParser将输入查询字串解析为Lucene Query对象。
-
QueryParser是使用JavaCC(Java Compiler Compiler )工具生成的词法解析器。
-
QueryParser.jj中定义了查询语法。
-
-
需要让QueryParser更好的支持中文,例如全角空格等?
分析器(Analyzer):
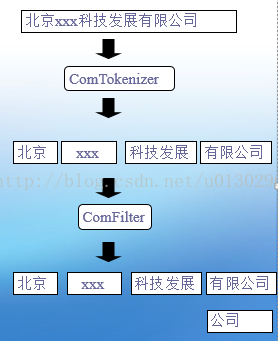
|
1
2
3
4
5
6
7
|
分析公司名的流程
Analyzer analyzer =
new
CompanyAnalyzer();
TokenStream ts = analyzer.tokenStream(“title",
new
StringReader(
"北京xxx科技发展有限公司"
));
while
(ts.incrementToken()) {
System.out.println(
"token: "
+ts));
}
|
最基本的词条查询-TermQuery:
一般用于查询不切分的字段或者基本词
|
1
2
3
4
5
6
|
IndexSearcher isearcher =
new
IndexSearcher(directory,
true
);
//查询url地址列
Termterm =
new
Term(
"url"
,
"http://www.lietu.com"
);
TermQuery query =
new
TermQuery(term);
//返回前1000条结果
ScoreDoc[] hits = isearcher.search(query,
1000
).scoreDocs;
|
布尔逻辑查询-BooleanQuery:
举例:同时查询标题列和内容列
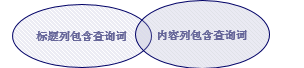
|
1
2
3
4
5
6
7
8
9
10
11
|
QueryParser parser =
new
QueryParser(Version.LUCENE_CURRENT,
"body"
, analyzer);
QuerybodyQuery = parser.parse(
"NBA"
);
//查询内容列
parser
=
new
QueryParser(Version.LUCENE_CURRENT,
"title"
, analyzer);
QuerytitleQuery = parser.parse(
"NBA"
);
//查询标题列
BooleanQuery bodyOrTitleQuery =
new
BooleanQuery();
//用OR条件合并两个查询
bodyOrTitleQuery.add(bodyQuery, BooleanClause.Occur.SHOULD);
bodyOrTitleQuery.add(titleQuery, BooleanClause.Occur.SHOULD);
//返回前1000条结果
ScoreDoc[] hits = isearcher.search(bodyOrTitleQuery,
1000
).scoreDocs;
|
布尔查询的实现原理:

RangeQuery-区间查找:
例如日期列time按区间查询的语法:
time:[2007-08-13T00:00:00Z TO 2008-08-13T00:00:00Z]
后台实现代码:
|
1
2
|
ConstantScoreRangeQuery dateQuery =
new
ConstantScoreRangeQuery(
"time"
, t1, t2,
true
,
true
);
|
这是Lucene的用法和原理,构建自己的搜索引擎可以使用Lucene这个强大的工具包,将大大缩减开发周期,实现一个高性能的个人搜索引擎。
