本篇用代码演示David Silver《强化学习RL》第三讲 动态规划寻找最优策略中的示例——方格世界,即用动态规划算法通过迭代计算来评估4*4方格世界中的一个随机策略。具体问题是这样:
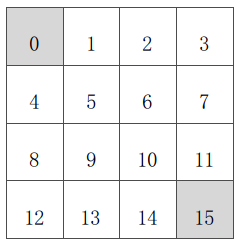
已知(如上图):
- 状态空间 S:
为非终止状态;
,
终止状态,图中灰色方格所示两个位置;
- 行为空间 A:{n, e, s, w} 对于任何非终止状态可以有向北、东、南、西移动四个行为;
- 转移概率 P:任何试图离开方格世界的动作其位置将不会发生改变,其余条件下将100%地转移到动作指向的位置;
- 即时奖励 R:任何在非终止状态间的转移得到的即时奖励均为-1,进入终止状态即时奖励为0;
- 衰减系数 γ:1;
- 当前策略π:个体采用随机行动策略,在任何一个非终止状态下有均等的几率往任意可能的方向移动,即π(n|•) = π(e|•) = π(s|•) = π(w|•) = 1/4。
问题:评估在这个方格世界里给定的策略。
该问题等同于:求解该方格世界在给定策略下的(状态)价值函数,也就是求解在给定策略下,该方格世界里每一个状态的价值。
我们使用Python编写代码解决该问题。
- 声明状态
S = [i for i in range(16)]- 声明行为空间
A = ['n','e', 's', 'w']- 结合方格世界的布局特点,简易声明行为对状态的改变
ds_actions = {"n": -4, "e": 1, "s": 4, "w": -1}- 环境动力学
模拟小型方格世界的环境动力学特征:
Args:
s 当前状态int 0 - 15
a 行为 str in ['n','e','s','w'] 分别表示北、东、南、西
Returns: tuple (s_prime, reward, is_end)
s_prime 后续状态
reward 奖励值
is_end 是否进入终止状态def dynamics(s, a): # 环境动力学
s_prime = s
if (s % 4 == 0 and a== 'w') or (s < 4 and a == 'n') or ((s + 1) % 4 == 0 and a == 'e') or (s > 11 and a == 's') or s in [0, 15]:
pass
else:
ds = ds_actions[a]
s_prime = s + ds
reward = 0 if s in [0, 15] else -1
is_end = True if s in [0, 15] else False
return s_prime , reward, is_enddef P(s, a, sl):# 状态转移概率函数
s_prime, _, _ = dynamics(s, a)
return sl == s_primedef R(s, a):# 奖励函数
_, r, _ = dynamics(s, a)
return rgamma = 1.00
MDP = S, A, R, P, gamma 最后建立的MDP 同上一章一样是一个拥有五个元素的元组,只不过 R 和 P 都变成了函数而不是字典了。同样变成函数的还有策略。下面的代码分别建立了均一随机策略和贪婪策略,并给出了调用这两个策略的统一的接口。由于生成一个策略所需要的参数并不统一,例如像均一随机策略多数只需要知道行为空间就可以了,而贪婪策略则需要知道状态的价值。为了方便程序使用相同的代码调用不同的策略,我们对参数进行了统一。
def uniform_random_pi(MDP = None, V = None, s = None, a = None): # 均一随机策略
_, A, _, _, _ = MDP
n = len(A)
return 0 if n == 0 else 1.0/ndef greedy_pi(MDP, V, s, a):# t贪婪策略
S, A, P, R, gamma = MDP
max_v, a_max_v = -float('inf'), []
for a_opt in A:# 统计后续状态的最大价值以及到达到达该状态的行为( 可能不止一个)
s_prime, reward, _ = dynamics(s, a_opt)
v_s_prime = get_value(V, s_prime)
if v_s_prime > max_v:
max_v = v_s_prime
a_max_v = [a_opt]
elif(v_s_prime == max_v):
a_max_v.append(a_opt)
n = len(a_max_v)
if n == 0: return 0.0
return 1.0/ n if a in a_max_v else 0.0def get_pi(Pi, s, a, MDP = None, V = None):
return Pi(MDP, V, s, a)在编写贪婪策略时,我们考虑了多个状态具有相同最大值的情况,此时贪婪策略将从这多个具有相同最大值的行为中随机选择一个。为了能使用前一章编写的一些方法,我们重写一下需要用到的诸如获取状态转移概率、奖励以及显示状态价值等的辅助方法:
# 辅助函数
def get_prob(P, s, a, sl):
return P(s, a,sl)
def get_reward(R, s, a):
return R(s, a)
def set_value(V, s, v):
V[s] = v
def get_value(V, s):
return V[s]
def display_V(V):
for i in range(16):
print('{0:>6.2f}'.format(V[i]),end = '')
if (i + 1) % 4 == 0:
print('')
print()有了这些基础,接下来就可以很轻松地完成迭代法策略评估、策略迭代和价值迭代了。在前一章的实践环节,我们已经实现了完成这三个功能的方法了,这里只要做少量针对性的修改就可以了,由于策略Pi 现在不是查表式获取而是使用函数来定义的,因此我们需要做相应的修改,修改后的完整代码如下:
def compute_q(MDP, V, s, a):
#根据给定的MDP, 价值函数V, 计算状态行为对s,a的价值qsa
S, A, R, P, gamma =MDP
q_sa = 0
for s_prime in S:
q_sa += get_prob(P, s, a, s_prime) * get_value(V, s_prime)
q_sa = get_reward(R, s, a) + gamma * q_sa
return q_sadef compute_v(MDP, V, Pi, s):
# 给定MDP下依据某一策略Pi和当前状态价值函数V计算某状态s的价值
S, A, R, P, gamma = MDP
v_s = 0
for a in A:
v_s += get_pi(Pi, s, a, MDP, V) * compute_q(MDP, V, s, a)
return v_sdef update_V(MDP, V, Pi):
# 给定一个MDP和一个策略, 更新该策略下的价值函数V
S, _, _, _, _ = MDP
V_prime = V.copy()
for s in S:
set_value(V_prime, s, compute_v(MDP, V_prime, Pi, s))
return V_primedef policy_evaluate(MDP, V, Pi, n):
# 使用n次迭代计算来评估一个MDP在给定策略Pi下的状态价值, 初始时价值为V
for i in range(n):
V = update_V(MDP, V, Pi)
return Vdef policy_iterate(MDP, V, Pi, n, m):
for i in range(m):
V = policy_evaluate(MDP, V, Pi, n)
Pi = greedy_pi # 第一次迭代产生新的价值函数后随机使用贪婪策略
return V# 价值迭代得到最优状态价值过程
def compute_v_from_max_q(MDP, V, s):
# 根据一个状态的下所有可能的行为价值中最大一个来确定当前状态价值
S, A, R, P, gamma = MDP
v_s = -float('inf')
for a in A:
qsa = compute_q(MDP, V, s, a)
if qsa >= v_s:
v_s = qsa
return v_sdef update_V_without_pi(MDP, V):
# 在不依赖策略的情况下直接通过后续状态的价值来更新状态价值
S, _, _, _, _ = MDP
V_prime = V.copy()
for s in S:
set_value(V_prime, s, compute_v_from_max_q(MDP, V_prime, s))
return V_primedef value_iterate(MDP, V, n):
# 价值迭代
for i in range(n):
V = update_V_without_pi(MDP, V)
return V策略评估
接下来就可以来调用这些方法进行策略评估、策略迭代和价值迭代了。我们先来分别评估一下均一随机策略和贪婪策略下16 个状态的最终价值:
V = [0 for _ in range(16)]# 状态价值
V_pi = policy_evaluate(MDP, V, uniform_random_pi, 100)
display_V(V_pi)
V = [0 for _ in range(16)]# 状态价值
V_pi = policy_evaluate(MDP, V, greedy_pi, 100)
display_V(V_pi)
V = [0 for _ in range(16)]# 状态价值
V_pi = policy_evaluate(MDP, V, uniform_random_pi, 100)
display_V(V_pi)
V = [0 for _ in range(16)]# 状态价值
V_pi = policy_evaluate(MDP, V, greedy_pi, 100)
display_V(V_pi)
# 输出结果
0.00-223.96-319.95-351.94
-223.96-287.95-319.95-319.95
-319.95-319.95-287.96-223.97
-351.94-319.95-223.97 0.00
0.00-16.00-32.00-48.00
-16.00-32.00-48.00-32.00
-32.00-48.00-32.00-16.00
-48.00-32.00-16.00 0.00可以看出,均一随机策略下得到的结果与图3.5 显示的结果相同。在使用贪婪策略时,各状态的最终价值与均一随机策略下的最终价值不同。这体现了状态的价值是基于特定策略的。
策略迭代
编写如下代码进行贪婪策略迭代,观察每迭代1 次改善一次策略,共进行100 次策略改善
后的状态价值:
V = [0 for _ in range(16)]# 重置状态价值
V_pi = policy_iterate(MDP, V, greedy_pi, 1, 100)
display_V(V_pi)
0.00-16.00-32.00-48.00
-16.00-32.00-48.00-32.00
-32.00-48.00-32.00-16.00
-48.00-32.00-16.00 0.00价值迭代
下面的代码展示了单纯使用价值迭代的状态价值,我们把迭代次数选择为4 次,可以发现仅4 次迭代后,状态价值已经和最优状态价值一致了。
V_star = value_iterate(MDP, V, 4)
display_V(V_star)
#输出结果
0.00-16.00-32.00-48.00
-16.00-32.00-48.00-32.00
-32.00-48.00-32.00-16.00
-48.00-32.00-16.00 0.00
我们还可以编写如下的代码来观察最优状态下对应的最优策略:
def greedy_policy(MDP, V, s):
S, A, P, R, gamma = MDP
max_v, a_max_v = -float('inf'),[]
for a_opt in A:
# 统计后续状态的最大价值以及到达到达该状态的行为( 可能不止一个)
s_prime, reward, _ = dynamics(s, a_opt)
v_s_prime = get_value(V, s_prime)
if v_s_prime > max_v:
max_v = v_s_prime
a_max_v = a_opt
elif(v_s_prime == max_v):
a_max_v += a_opt
return str(a_max_v)
def display_policy(policy, MDP, V):
S, A, P, R, gamma = MDP
for i in range(16):
print('{0:^6}'.format(policy(MDP, V, S[i])), end = ' ')
if (i + 1) % 4 == 0:
print('')
print()
display_policy(greedy_policy, MDP, V_star)
# 输出结果
nesw w w sw
n nw nesw s
n nesw es s
ne e e nesw
上面分别用n,e,s,w 表示北、东、南、西四个行为。这与图3.5 显示的结果是一致的。读者可以通过修改不同的参数或在迭代过程中输出价值和策略观察价值函数和策略函数的迭代过程。