上一节详细介绍了什么是LDA,详细讲解了他的原理,大家应该好好理解,如果不理解,这一节就别看了,你是看不懂的,这里我在简单的叙述LDA的算法思想:
首先我们只拥有很多篇文本和一个词典,那么我们就可以在此基础上建立基于基于文本和词向量联合概率(也可以理解为基于文本和词向量的矩阵,大家暂且这样理解),我们只知道这么多了,虽然知道了联合概率密度了,但是还是无法计算,因为我们的隐分类或者主题不知道啊,在LSA中使用SVD进行寻找隐分类的,在PLSA中使用概率进行找隐分类的,而在LDA中是如何做的呢?他是这样做的,首先我为每个文本赋值一个服从Dirichlet分布的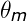
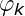
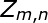
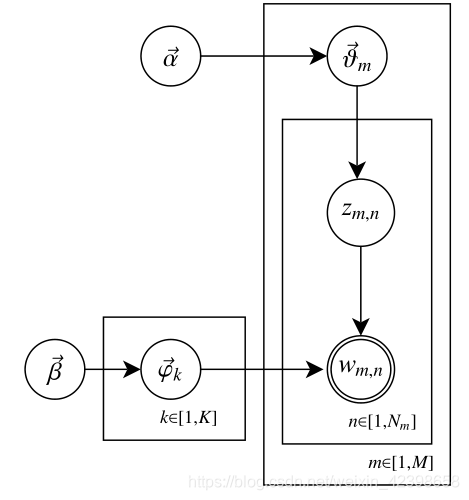
首先我通过文本和词向量建立联合概率密度,但是这个联合概率密度需要知道隐分类,要不然后面无法进一步计算,首先我们现在需要确定这个文本有多少个隐分类(隐分类和词的多少有关),而隐分类的和词相关,上图的 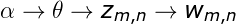
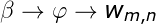
LDA训练算法
通过上一篇的文章我们知道了什么是LDA模型,那么这个模型有两个目标,如下:
- 估计模型的参数
和
;
- 对于新来的一篇文档
,我们能够计算这篇文档的主题(隐分类、topic)分布

根据前面的算法即LSA,PLSA我们知道只要知道隐分类(主题、topic)那么文本其他计算就简单了,因此这里我们第二个目标就不详细的讲解,本节详细介绍LDA的训练算法,当然,我只是把训练算法的思路讲一下,具体细节大家看原始论文吧,这一节我想想就头大的,我尽力写,你们也尽力看,等这一节过了,后面的就很简单了。下面开始:
总体思路:
首先给出联合分布公式(但由于topic是隐变量,所以实际上并能进行计算)
- 从联合分布推导出条件概率公式(用于Gibbs抽样)
- 通过Gibbs抽样过程推算出每个词所属topic
- Topic算出来后,分布中已经没有隐变量,通过推导公式倒推出分布参数
这里我们参考的论文是《Parameter estimation for text analysis》,大家可以找一下这篇文章参考看一下:
![]()
这里先从这个概率说起,为什么是这个形式呢?这里大家先搞明白上面的符号代表的什么意思,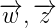
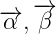
这就是根据条件概率来回变换而已: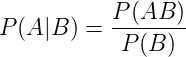
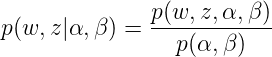
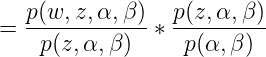
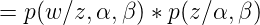
这里需要理由概率图模型,不懂的看这篇文章,因为w是是直接受到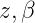
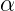
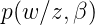
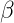
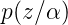
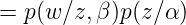
就是原始的定义了,大家明白了吧,继续往下:
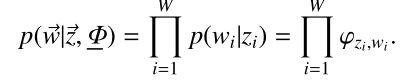
上式的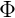
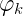
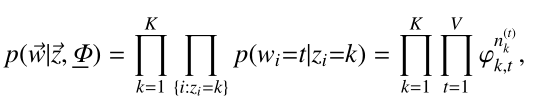
上式是根据Dirichlet分布展开的,继续往下
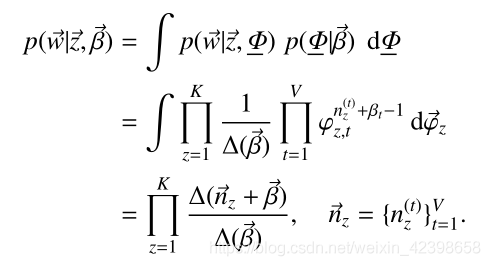
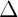
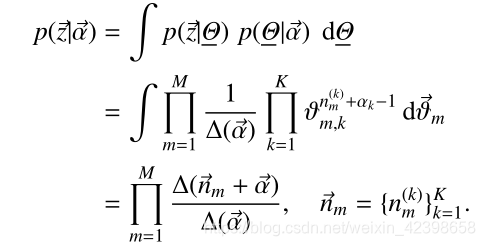
由此我们刚开始的联合概率密度可以写为如下:
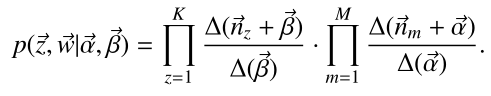
由此我们继续引出条件概率:
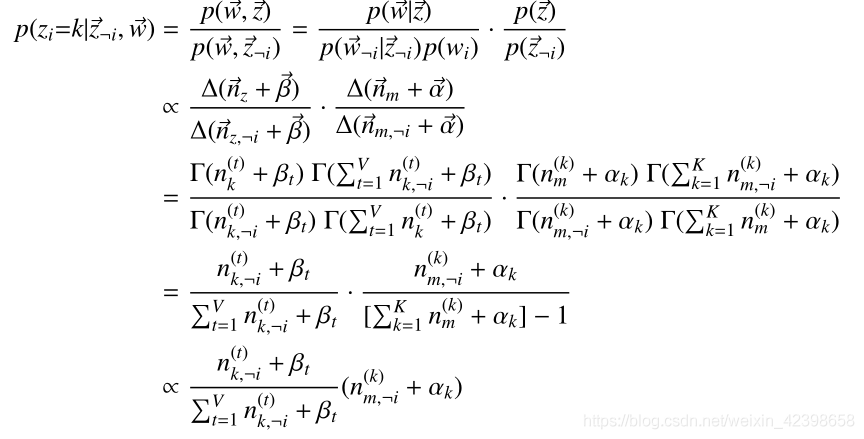
上式大概是什么意思呢?就是说,这里其实就是我们上一篇提到的Gibbs采样形式了,这里我们令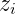
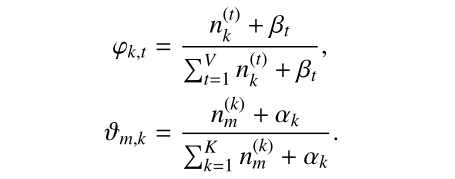
大家参考原始论文和下面的博客会有更大的收获的,尤其伪代码:

大家参考这篇文章吧,我目前理解也不算很深,以后实战也许会理解的更深,到时候再补一下,抱歉大家,本人能力就这些,只能从大体上理解他是如何工作和训练的,请多包涵。