权重初始化方法位于torch.nn.init中。
增益计算
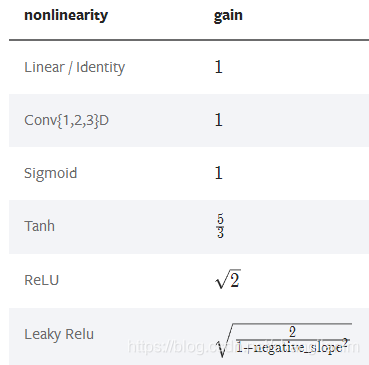
对于给定的非线性函数,返回推荐的增益值。
torch.nn.init.calculate_gain(nonlinearity, param=None)
参数:
nonlinearity - 非线性函数
param - 非线性函数的可选参数
使用:
gain = nn.init.calculate_gain('leaky_relu')
1 常数初始化
用val的值填充输入的张量或变量
torch.nn.init.constant_(tensor, val)
参数:
tensor – n维的torch.Tensor或autograd.Variable
val – 用来填充张量的值
使用:
w = torch.empty(3, 5)
nn.init.constant_(w, 0.3)
2 均匀分布初始化
从均匀分布U(a, b)中生成值,填充输入的张量或变量
torch.nn.init.uniform_(tensor, a=0, b=1)
参数:
tensor - n维的torch.Tensor
a - 均匀分布的下界
b - 均匀分布的上界
3 正态分布初始化
从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
torch.nn.init.normal_(tensor, mean=0, std=1)
参数:
tensor – n维的torch.Tensor
mean – 正态分布的均值
std – 正态分布的标准差
4 Xavier 均匀分布
用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自U(-a, a),其中a= gain * sqrt( 2/(fan_in + fan_out))* sqrt(3). 该方法也被称为Glorot initialisation
torch.nn.init.xavier_uniform_(tensor, gain=1)
参数:
tensor – n维的torch.Tensor
gain - 可选的缩放因子
5 Xavier 正态分布
用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自均值为0,标准差为gain * sqrt(2/(fan_in + fan_out))的正态分布。也被称为Glorot initialisation.
torch.nn.init.xavier_normal_(tensor, gain=1)
参数:
tensor – n维的torch.Tensor
gain - 可选的缩放因子
6 kaiming 均匀分布
用一个均匀分布生成值,填充输入的张量或变量。结果张量中的值采样自U(-bound, bound),其中
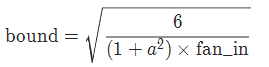
torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
参数:
tensor – n维的torch.Tensor
a -这层之后使用的rectifier的负斜率系数(ReLU的默认值为0)
mode - fan_in 保留前向传播时权值方差的大小,fan_out 保留反向传播时的大小。默认:fan_in
nonlinearity –非线性函数,推荐使用relu和leaky_relu,默认leaky_relu
7 kaiming 正态分布
用一个正态分布生成值,填充输入的张量或变量。结果张量中的值采样自
的正态分布。
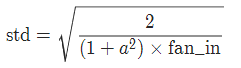
torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
参数:
tensor – n维的torch.Tensor
a -这层之后使用的rectifier的负斜率系数(ReLU的默认值为0)
mode - fan_in 保留前向传播时权值方差的大小,fan_out 保留反向传播时的大小。默认:fan_in
nonlinearity –非线性函数,推荐使用relu和leaky_relu,默认leaky_relu
8 单位矩阵初始化
用单位矩阵来填充2维输入张量或变量。在线性层尽可能多的保存输入特性。
torch.nn.init.eye_(tensor)
参数:
tensor – 2维的torch.Tensor
9 正交初始化
用(半)正交矩阵填充输入的张量或变量。
torch.nn.init.orthogonal_(tensor, gain=1)
参数:
tensor – n维的torch.Tensor或 autograd.Variable,其中n>=2
gain -可选
10 稀疏初始化
将2维的输入张量或变量当做稀疏矩阵填充,其中非零元素根据一个均值为0,标准差为std的正态分布生成。
torch.nn.init.sparse_(tensor, sparsity, std=0.01)
参数:
tensor – n维的torch.Tensor或autograd.Variable
sparsity - 每列中需要被设置成零的元素比例
std - 用于生成非零值的正态分布的标准差
11 狄拉克δ函数初始化
使用狄拉克δ函数填充输入的torch.Tensor。
torch.nn.init.dirac_(tensor)
参数:
tensor – {3, 4, 5}维的torch.Tensor