增强学习和控制
在监督学习中,算法试图模仿训练机的labels y,训练集中的每一个输入x都有一个确定的对应的y,但是对于很多需要连续作决定的问题和控制问题,给算法提供一个明确的标签是很难的。例如我们有一个四足机器人,并且试图让他行走,开始的时候我们并不知道采取怎样的操作使他行走,也不知道怎么给算法提供一个标签来模仿。
在增强学习中,我们会给算法提供一个奖励函数来反应做的好还是不好。例如对于上述的4足机器人,当他向前行走是给出正面的奖励,当他向后退或者摔倒时给出负面的奖励。然后学习算法就会学习选择怎样的操作来获取更多的奖励。
增强学习在自治直升机、机器人、手机网络路由、销售策略选择、工业控制、网页索引等多领域取得了成功。对增强学习的研究从MDP(Markov desicion processes)开始。
1.MDP
MDP是一个元组(S,A,Psa,
MDP过程如下:初始状态
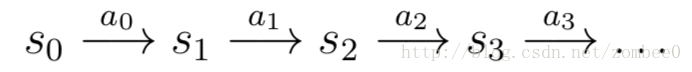
得到的奖励如下:
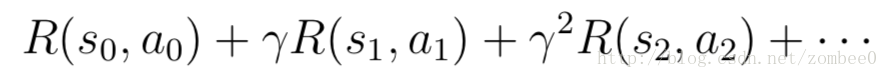
对于奖励函数只和状态有关的情况:
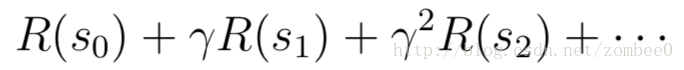
增强学习的目标是最大化奖励:
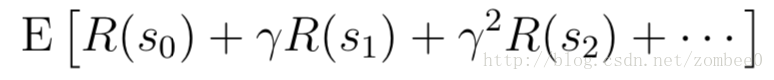
时间t时的奖励要乘上折现因子
策略函数
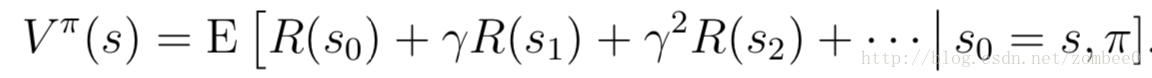
对于给定的策略
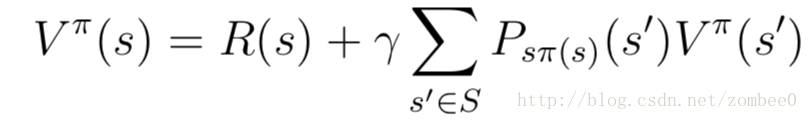
价值函数
Bellman等式可用于MDP价值函数的求解。对于状态有限的MDP过程,对于每一个状态s,都可以写出一个Bellman等式,由此给出了价值函数的线性方程组,可以解出价值函数。
最佳价值函数定义如下:
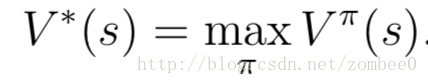
最佳价值函数的Bellman等式如下:
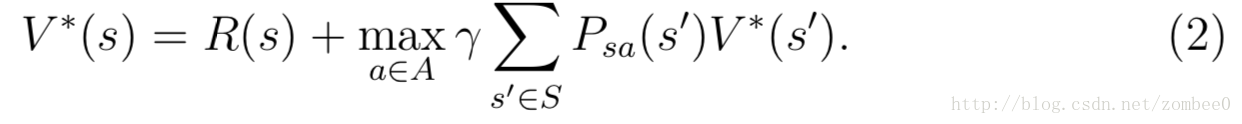
最佳策略定义如下:
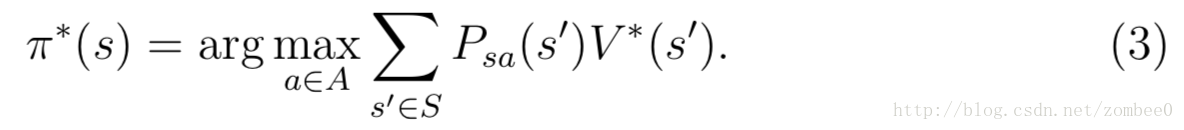
最佳策略$\pi$*对于任意的其实状态都是相同的,因此无论起始状态如何都是相同的最佳策略。
2.价值迭代和策略迭代
对于有限状态的MDP,我们讨论两种解法,价值迭代和策略迭代。
价值迭代方法如下:
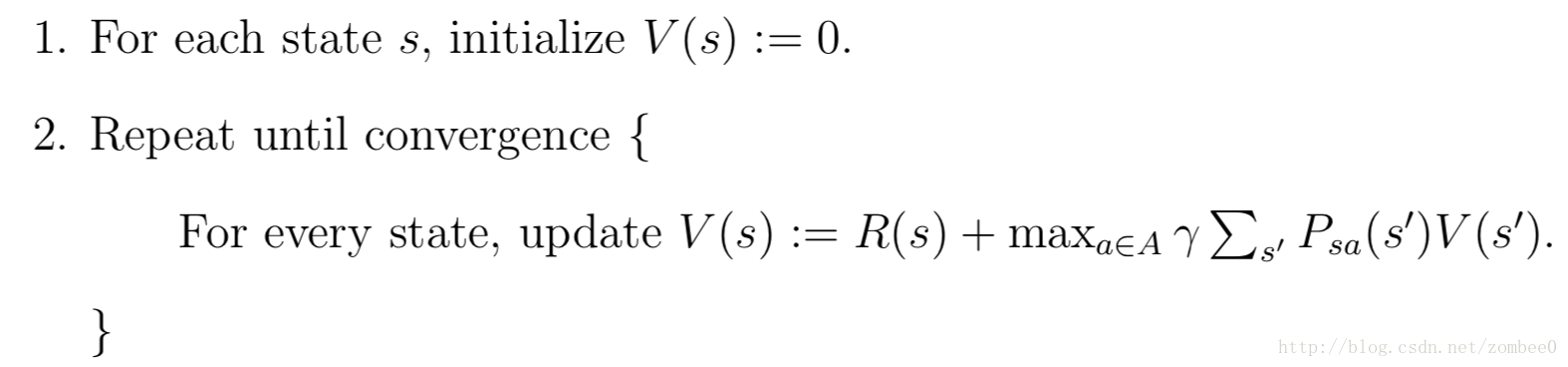
循环内的更新有两种方法:1.同步更新,先每个状态新的V(s)值,之后同时更新旧值;2.异步更新,每次便利所有状态,然后更新一个状态的V(s)值。
策略迭代方法如下:

步骤(a)中价值函数的求解,如前文所属求解由每个状态的Bellman等式组成的线性方程组。
对于小型的MDP过程,策略迭代速度更快,但是对于大型MDP会引入较大的线性方程组求解,因而价值迭代更优。
3.MDP学习模型
前面讨论了状态转移概率和奖励函数已知情况下的MDP和求解,实际情况中,很多时候要从数据计算状态转移概率和奖励函数。
例如有一系列实验数据如下:
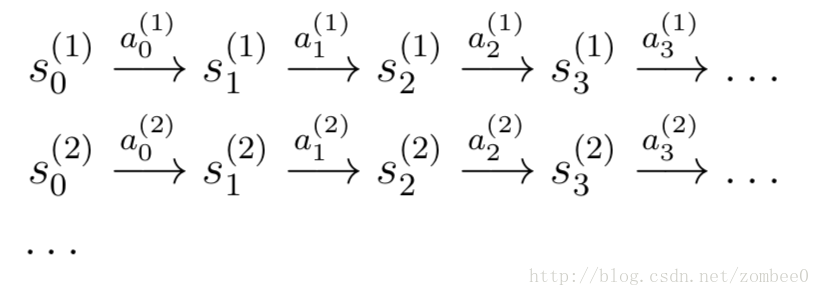
其中si(j)为第j次实验第i时刻的状态,ai(j)为采取的行动。转移概率如下:
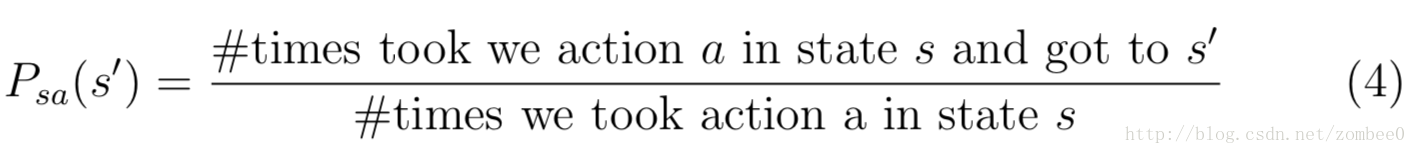
对于从未到过的状态s,可以简单的假定为Psa(s’)为
相似的,如果R未知,状态s的奖励函数R(s)由平均数求得。
之后可以使用价值迭代或策略迭代方法求解MDP过程,整个过程如下:

4.连续状态的MDP
上述讨论限于状态有限的MDP,接下来讨论无限状态的MDP。例如车辆的行驶状态,直升机的状态等等。
4.1 离散化
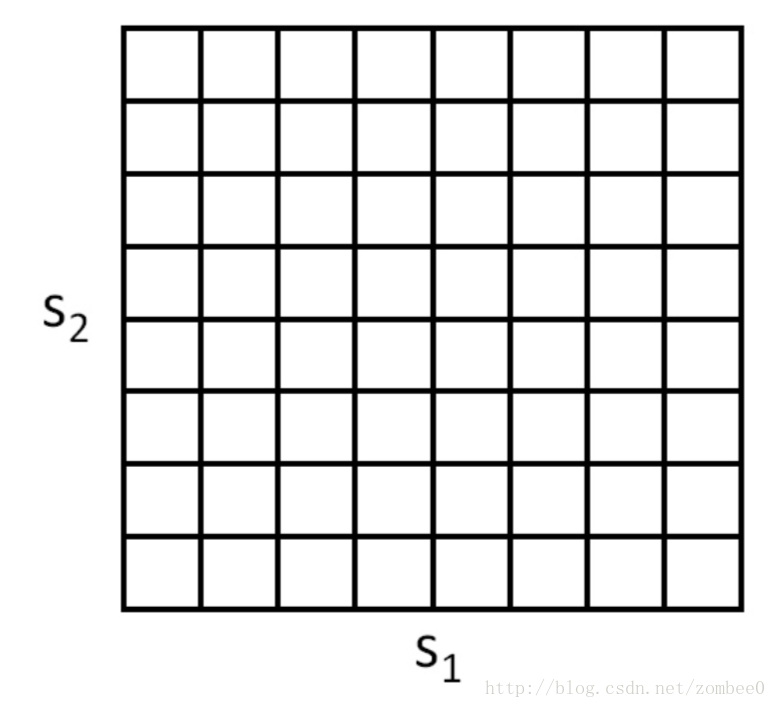
最简单的方式是通过离散化使用前文所提到的方法进行计算。例如对于2d状态可以通过网格离散化:
4.2 价值函数近似
4.2.1 使用模型或仿真器
我们假定有一个MDP的模型或仿真器,进而开发价值函数近似算法。简单地说,仿真器是一个黑盒,可以输入任意状态st和at,根据状态转移概率Pstat输出st+1.
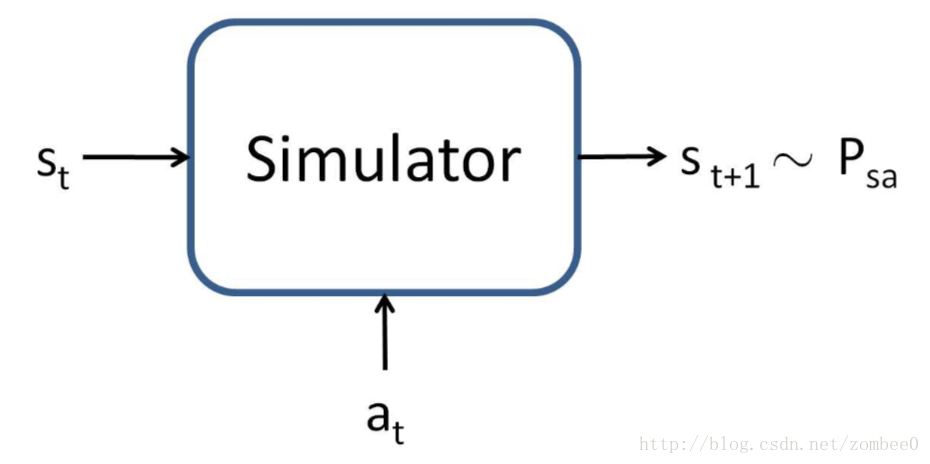
有多种方法获取上述模型。一种是物理仿真。另一种方法是从已获取的MDP数据中学习模型。
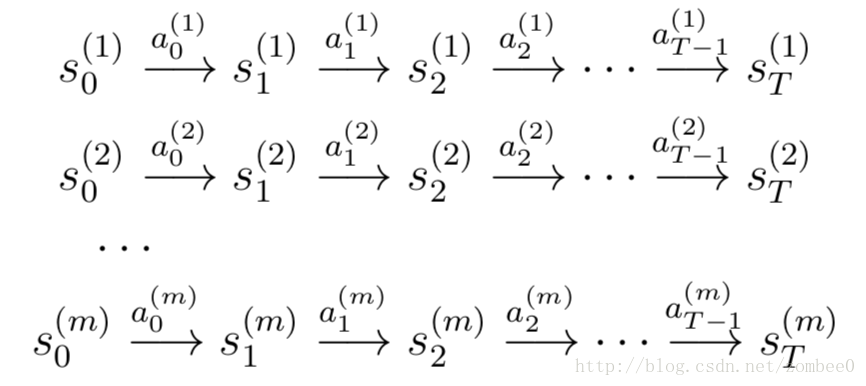
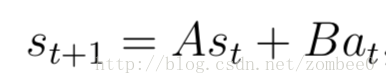
应用学习算法预测st+1为st和at的函数。
4.2.2 Fitted value iteration
这一部分还未完全搞清楚,后续整理。

欢迎关注微信公众号“翰墨知道”,获取及时更新
