版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/zsl10/article/details/52885597
scrapy-deltafetch简介
scrapy-deltafetch通过Berkeley DB来记录爬虫每次爬取收集的request和item,当重复执行爬虫时只爬取新的item,实现增量去重,提高爬虫爬取性能。
Berkeley DB简介
Berkeley DB是一个嵌入式数据库,为应用程序提供可伸缩的、高性能的、有事务保护功能的数据管理服务。
主要特点:
- 嵌入式:直接链接到应用程序中,与应用程序运行于同样的地址空间中,因此,无论是在网络上不同计算机之间还是在同一台计算机的不同进程之间,数据库操作并不要求进程间通讯。 Berkeley DB为多种编程语言提供了API接口,其中包括C、C++、Java、Perl、Tcl、Python和PHP,所有的数据库操作都在程序库内部发生。多个进程,或者同一进程的多个线程可同时使用数据库,有如各自单独使用,底层的服务如加锁、事务日志、共享缓冲区管理、内存管理等等都由程序库透明地执行。
- 轻便灵活:可以运行于几乎所有的UNIX和Linux系统及其变种系统、Windows操作系统以及多种嵌入式实时操作系统之下,已经被好多高端的因特网服务器、台式机、掌上电脑、机顶盒、网络交换机以及其他一些应用领域所采用。一旦Berkeley DB被链接到应用程序中,终端用户一般根本感觉不到有一个数据库系统存在。
- 可伸缩:Database library本身是很精简的(少于300KB的文本空间),但它能够管理规模高达256TB的数据库。它支持高并发度,成千上万个用户可同时操纵同一个数据库
安装Berkeley DB
# cd /usr/local/src
# wget http://download.oracle.com/berkeley-db/db-4.7.25.NC.tar.gz
# tar zxvf db-4.7.25.NC.tar.gz
# cd build_unix
# ../dist/configure
# make&&make install安装bsddb3
(python2.7-env01)# pip install bsddb3安装scrapy-deltafetch
(python2.7-env01)# pip install scrapy-deltafetch安装scrapy-magicfields
(python2.7-env01)# pip install scrapy-magicfields配置
在配置文件setting.py增加如下代码:
SPIDER_MIDDLEWARES = {
'scrapy_deltafetch.DeltaFetch': 50,
'scrapy_magicfields.MagicFieldsMiddleware': 51,
}
DELTAFETCH_ENABLED = True
MAGICFIELDS_ENABLED = True
MAGIC_FIELDS = {
"timestamp": "$time",
"spider": "$spider:name",
"url": "scraped from $response:url",
"domain": "$response:url,r'https?://([\w\.]+)/']",
}效果展示
首先设置数据表crawedArticle字段title_id为主键,用来验证多次爬取某个页面是否抓取了重复数据。
以项目中东方财富网的爬虫为例:
不使用去重插件scrapy-deltafetch测试
第一次执行爬虫:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl --pdb east此时数据库成功写入了爬取到的数据。
第二次执行爬虫:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl --pdb eastmysql将会出现重复写入错误:

说明爬虫重复抓取了数据!
使用去重插件scrapy-deltafetch测试
首先,清空数据表crawedArticle,第一次执行爬虫:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl east爬虫运行结束后数据库写入15条数据,观察爬虫爬取完成后的信息采集结果如下:
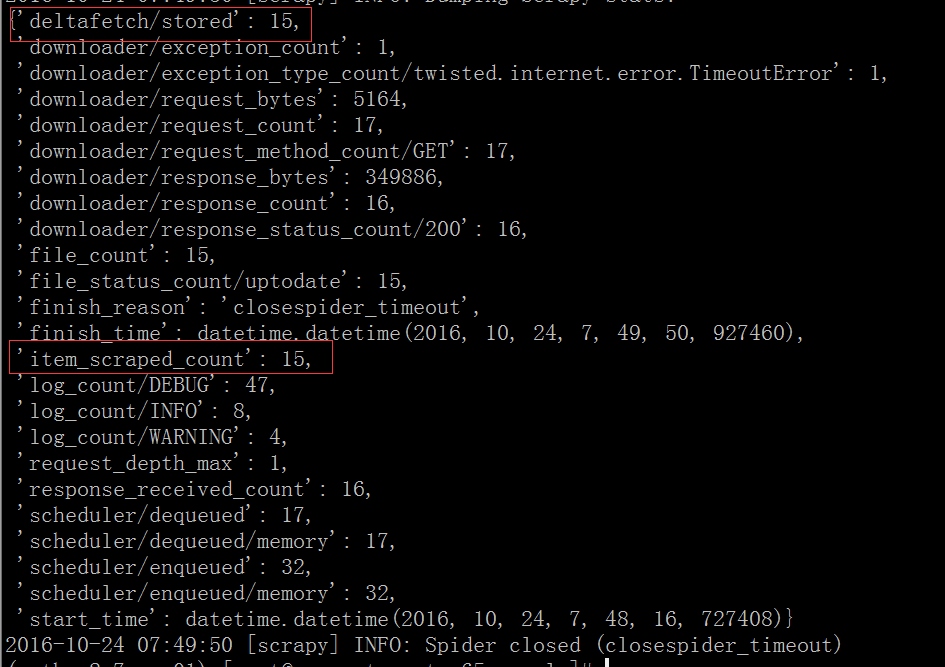
scrapy-deltafetch记录了爬取的15个item
同时在项目所在跟目录会生成缓存文件:

第二次执行爬虫:
(python2.7-env01) [root@vagrant-centos65 sample]# scrapy crawl eastmysql并未出现重复写入错误且信息采集结果如下:
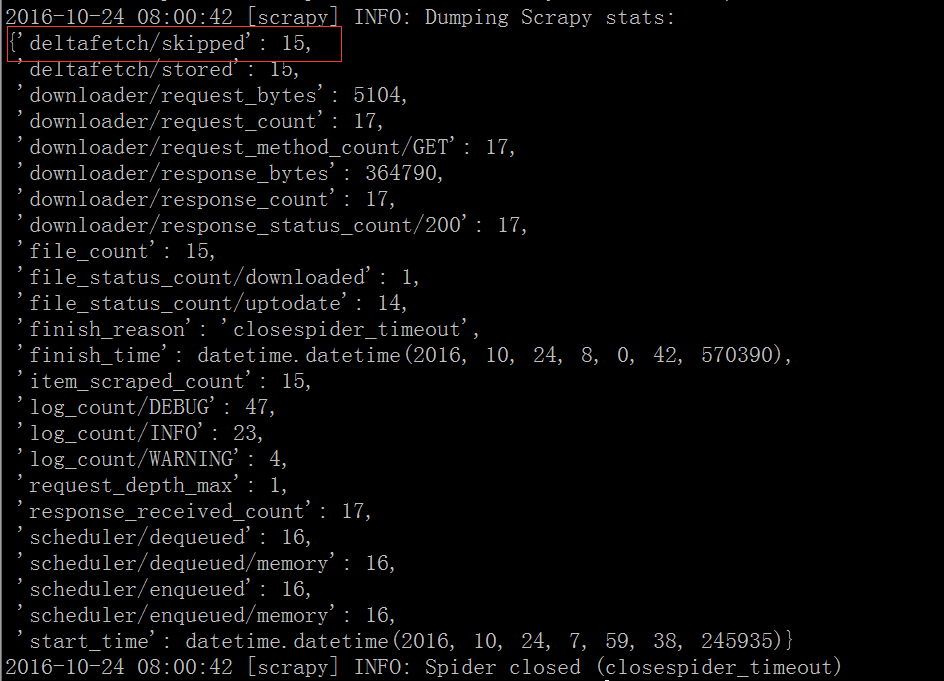
scrapy-deltafetch忽略了之前已经爬取的15个item。
说明使用scrapy-deltafetch并未抓取重复的数据!
重置DeltaFetch
如果想重置某个页面的爬取数据缓存,执行命令:
scrapy crawl spider_name -a deltafetch_reset=1