原文地址: https://arxiv.org/abs/1612.02136 引用之请注明出处。
摘要
尽管生成对抗网络在各种生成任务中实现了先进的结果,但它们高度不稳定的并且容易出错。作者认为GAN的这些不良行为是由于在高维空间中训练的判别函数的形状非常特殊,这很容易使训练不顺利,或将概率推向错误的方向。作者提出了几种使GAN的目标正规化的方法,可以大大稳定GAN模型的训练。本文还证明,本文的正规化器可以在训练的早期阶段帮助在生成分布中公平分配概率,从而为缺失模式的问题提供统一的解决方案。
1 引言
生成对抗网络(GAN) (Goodfellow等, 2014)已经展示了它们在各种任务上的潜力,例如图像生成,图像超分辨率,3D对象生成和视频预测(Radford等,2015;Ledig等,2016;Sønderby等,2016;Nguyen等,2016;吴等,2016;Mathieu等,2015)。GAN的目标是训练参数化函数(生成器),以将噪声样本(例如均匀或高斯噪声)映射到接近样本数据的分布。GAN训练过程的基本方案是训练一个判别器,该判别器为实际数据样本分配较高的概率,并将较低的概率分配给生成的数据样本,同时尝试使用判别器提供的梯度信息将生成样本移向接近真实数据的流形。在常见的设定中,生成器和判别器由深度神经网络表示。
尽管GAN已经在一些领域取得了成功,但由于训练不稳定和对超参数的敏感性,GAN通常被认为非常难以训练。另一方面,训练GAN时观察到的常见故障模式是将大量可能出现的模式压缩到几种模式。即尽管生成器产生了有意义的样本,但这些样本通常仅来自几种常见的模式(即数据分布下的高概率的小范围区域)。这种现象的背后是模式的缺失问题,这被广泛认为是训练GAN的一个主要问题:数据分布的许多模式根本没有在生成的样本中表现出来,生成样本的熵值要低得多,而且生成样本中的变化少于原始数据分布。
这个问题一直是近期论文的主题,很多文章提出了一些技巧和新架构以稳定GAN的训练,并提升其样本的多样性。 然而作者认为这些问题背后的原因是在GAN训练期间对判别器缺乏控制。作者希望使用判别器作为度量,促使生成器生成的样本流向实际数据的流形。然而,即使训练了判别器来区分这两个流形,控制这两个流形之间的判别函数的形状也是很难的事。 实际上,判别的形状在数据中起作用的空间可能是非线性的,有不良的“高原”和错误的最大值,这可能会损害GAN的训练(图1)。

图1 在CelebA数据集上训练的DCGAN模型中具有非常高的判别值(
)的样本。
为了解决这个问题,作者提出了一个新的GAN训练目标正则化器。它的基本思想简单但功能强大:除了判别器提供的梯度信息之外,希望生成器利用具有更可预测行为的其他相似性度量,例如L2范数。区分这些相似性指标将提供更稳定的梯度来训练生成器。将这一想法与旨在惩罚缺失模式的方法相结合,可以为GAN目标构建一系列额外的正规化器。然后,作者设计一组度量以根据模式的多样性和分布的公平性来评估生成的样本。这些指标在判断复杂生成模型时表现得更加稳健,包括那些经过良好训练和崩溃的模型。
正则化器通常会在模型差异和偏差之间进行权衡。实验结果表明,正确应用正则化器可以显著减少模型方差、稳定训练,并一次性修复丢失模式的问题,对生成的样本产生正面或至少没有负面的影响。作者还讨论了正则化GAN算法的变体,与DCGAN的baseline相比,它可以改善样本质量。
2 相关工作
GAN方法最初是由Goodfellow等提出的(2014),其中生成器和判别器都是由深度神经网络定义的。
Goodfellow等的工作中(2014),GAN能够在各种数据集上生成有趣的局部结构,但全局非相干图像。Mirza & Osindero (2014)通过引入额外的向量来扩大GAN的表示能力,以允许生成器以其他有益信息为条件产生样本。GAN的几个条件变种已应用于广泛的任务,包括来自法线贴图的图像预测(Wang & Gupta,2016), 从文本合成图像(Reed等,2016)和边缘地图(Isola等,2016),实时图像处理(Zhu等,2016),时间图像生成(Zhou和Berg,2016;Saito& Matsumoto,2016;Vondrick等,2016),纹理合成,样式转换和视频风格转化(Li和Wand,2016)。
研究人员还致力于扩展GAN的极限,以生成更高分辨率的照片般逼真的图像。Denton等(2015)最初在GAN上应用拉普拉斯金字塔框架以生成高分辨率的图像。在他们的LAPGAN的每个级别,生成器和判别器都是卷积网络。作为LAPGAN的替代品, Radford等(2015)成功地设计了一类深度卷积生成对抗网络,使得无监督图像表示学习有了显著改进。旨在改进GAN的另一项工作是通过特征学习得到来自潜在空间和图像空间的特征。这项工作的动机是:来自不同空间的特征对于生成感知和自然图像是互补的。从这个角度来看,一些研究人员使用学习特征之间的距离作为生成模型训练目标的损失。Larsen等(2015)将变分自动编码器目标与GAN组合,并利用来自GAN中的判别器的学习特征来获得更好的图像相似性度量。结果表明,从判别器中学习距离对样本视觉保真度有很大帮助。最近的文献也展示了令人印象深刻的图像超分辨率结果,以生成4倍放大的照片般逼真的自然图像(Ledig等,2016;Sønderby等,2016;Nguyen等,2016)。

尽管取得了这些成功,但GAN非常难以训练。虽然 Radford等(2015)提供了一类对稳定GAN训练至关重要的经验特征选择,更利于GAN的训练。Salimans等(2016)提出特征匹配技术来稳定GAN的训练。要求生成器匹配判别器的中间特征的统计数据。类似的想法被赵等(2016)采用。
除了特征距离, Dosovitskiy&Brox (2016) 发现图像空间中的对应损失进一步提高了GAN的训练稳定性。此外,一些研究人员在统一学习过程中利用两个空间中的信息 (Dumoulin等, 2016; Donahue等,2016)。在Dumoulin等(2016)的工作中,一个训练器不仅训练一个生成器,而且训练一个编码器;同时训练判别器以区分图像上的两个分布,潜在空间是通过在训练数据上使用编码器,或对潜在先验应用生成器(解码器)产生的。这与常规GAN的训练形成对比:在常规GAN训练中,判别器仅尝试分离图像空间中的分布。此外,Metz等(2016)通过展开判别器的优化来稳定GAN的训练,这可以被认为是与本文正交的工作。
在与GAN模型共同训练自动编码器或VAE方面,本文的工作与VAEGAN有关(Larsenal等,2015)。然而,VAEGAN中的变分自动编码器(VAE)用于生成样本,而本文基于自动编码器的损失用作惩罚丢失模式的正则化器,从而提高GAN的训练稳定性和样本质量。本文在 附录D 中展示了各个方面的细节差异。
3 用于GAN的模式正则化器
GAN训练过程可以被视为一种对抗的双人游戏,其中判别器 试图区分真实和生成的例子,而生成器 试图通过将生成的样本推向更高的判别值的方向来欺骗判别器。训练判别器 可被视为训练样本空间的评估度量。然后,生成器 利用由判别器提供的局部梯度 来更新,即朝向原始数据流形的方向移动。
作者仔细研究了训练GAN时不稳定的根本原因。判别器在生成样本的和原始样本集上进行训练。正如Goodfellow等(2014)、Denton等(2015)、Radford等(2015)所指出的那样,当数据流形和生成流形是不相交的(在几乎所有实际情况中都是如此),它相当于训练的特征函数在数据流形上非常接近1,在生成流形上为0。在训练过程中,为了将良好的梯度信息传递给生成器,判别器产生稳定、平滑的梯度是很重要的。然而,由于判别器目标不直接取决于判别器在空间的其他部分中的行为,如果判别器函数的形状不是预期的,则训练就很容易失败。举个例子,Denton等(2015)注意到了GAN常见的故障模式,即梯度消失问题。在这种情况下判别器 完美地分类了真实样本和生成实例,使得在生成样本周围, 几乎为零。在这种情况下,生成器将不会有任何利于让自己变好的梯度。
训练GAN时的另一个重要问题是模式缺失。理论上,如果生成的数据和实际数据来自相同的低维流形,则判别器可以帮助生成器分配其概率质量,因为缺失模式在生成器下不会具有接近0的概率,因此这些中的样本区域可以适当地集中在 接近1的区域。然而,实际上由于两个流形是不相交的, 在所有实际数据样本上往往都接近1,因此数据量较大的模式通常具有更高的判别器的梯度吸引力的机会。对于典型的GAN模型,由于所有模式都具有相似的 值,因此没有理由说明生成器不能坍缩到几个主要模式。换句话说,由于判别器的输出分别在伪造和真实的数据上几乎为0和1,因此生成器不会因缺失模式而受到惩罚。
3.1 几何度量的正则化器
与GAN生成器的目标相比,从优化的角度来看,监督学习的优化目标更加稳定。区别很明显:GAN生成器的优化目标是学习的判别器;在监督模型中,优化目标是具有良好几何特性的距离函数。后者通常提供比前者更容易的训练梯度,特别是在训练的早期阶段。
受此观察的启发,作者建议将监督训练的信号作为判别器目标之上的正则化器。假设生成器 首先从空间 中的固定先验分布中采样,然后通过训练变换 ,将其变换到样本空间 来生成样本。作者还与 联合联合训练编码器 。假设 是数据空间中的某种相似性度量,作者添加 作为正则化器,其中 是数据生成分布。编码器本身是通过最小化相同的重建误差来训练的。
在实践中,距离测量 有很多选择。例如,像素的 距离,或判别器的学习特征的距离(Dumoulin等,2016)或者由其他网络,例如VGG分类器提供的距离(Ledig等,2016)。
这个正则化器的几何直觉是非常直接的。作者试图使用梯度下降将生成的流形移动到真实数据流形。除了判别器提供的梯度之外,作者还尝试了通过其他几何距离匹配两个流形,例如 度量。添加编码器的想法等同于首先训练两个流形之间的点到点映射 ,然后尝试最小化这两个流形上的点之间的预期距离。
3.2 模型正则化器
除了度量的正则化器之外,作者还提出了一种模式正则化器,以进一步惩罚丢失的模式。在传统的GAN中,生成器的优化目标是经验总和
。丢失模式问题是由两个事实的结合引起的:
(1)生成器很少访问缺失模式附近的区域,因此可以去提供少量的样本去提升训练器在这些区域附近的表现;
(2)缺失模式和非缺失模式往往对应于
的较高的数值,生成器不是完美的,因此判别器可以在局部做出很好的判定,并获得高的
值(甚至在不缺失的地方也是如此)。
例如,考虑图2中的情况。对于大多数 ,生成器的梯度 将生成器推向主模式 。只有当 非常接近模式 时,生成器才能获得梯度以将其自身推向较小规模的 。然而这种 在先验可能是低概率或零概率 。
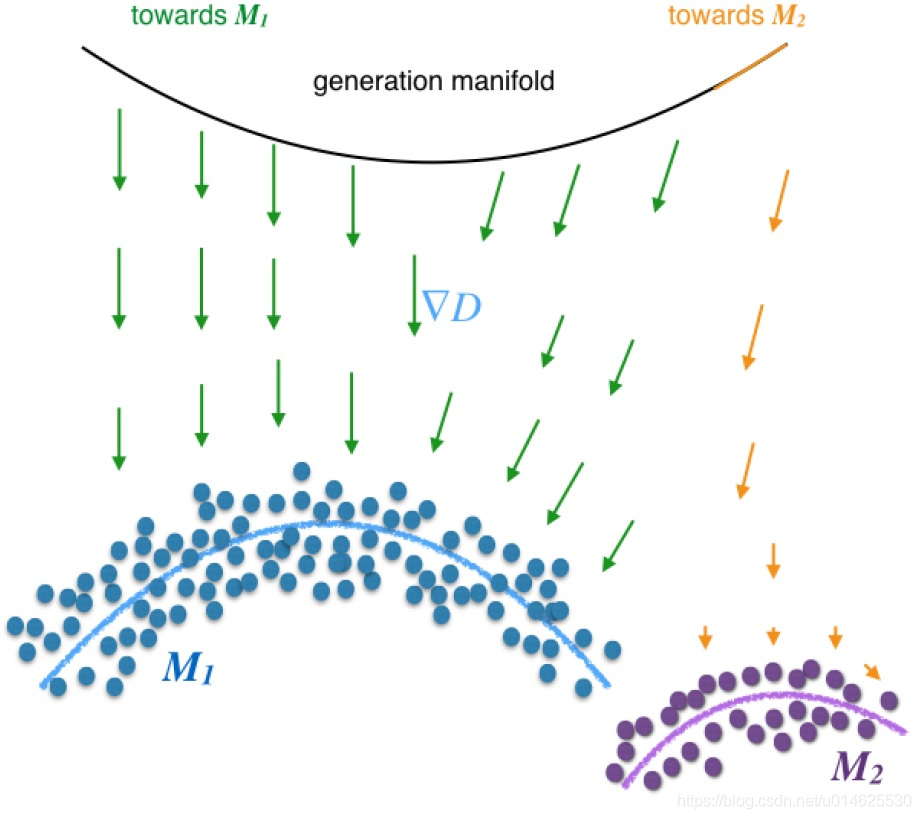
图2 缺失问题的图示。
鉴于此观察,考虑具有度量正则化器的GAN模型。假设 是数据生成分布的次要模式。对于 ,如果 是一个好的自动编码器, 将非常接近模式 。由于训练数据中有足够的模式 的训练样例,作者将模式正则化器 添加到生成器的优化目标中,以鼓励 移向附近的数据生成分布模式。通过这种方式可以实现跨不同模式的公平概率质量分布。
简而言之,生成器和编码器的正则化优化目标变为:
3.3 正则化GAN的流形扩散训练
在一些大型数据集CelebA中,上述正则化器确实改善了生成样本的多样性,但是如果不仔细调整超参数,样本的质量可能不会那么好。作者提出了一种用于训练度量正则化GAN的新算法,该算法非常稳定并且更容易调整以产生良好的样本。
所提出的算法将GAN的训练过程分为两个步骤:流形步骤和扩散步骤。在流形步骤中,尝试在编码器和几何度量损失的帮助下匹配生成流形和实际数据流形。在扩散步骤中,尝试根据实际数据分布公平地分配生成流形上各种概率的情况。
流形扩散训练GAN(简称MDGAN)的一个例子如下:训练一个判别器 ,它从数据中分离样本 和 。对于 ,作者优化 对于正则化GAN的损失 以匹配两个流形。在扩散步骤中,在分布 和 之间训练判别器D2,并且训练 以最大化 。由于这两个分布此时几乎在相同的低维流形上,因此判别器 要提供更平滑和更稳定的梯度。详细的训练程序见 附录A 。生成的样本的质量在图6。
3.4 模式缺失的评估指标
为了估计实验中的缺失模式和样本的质量,作者使用了几种不同的度量来代替人类注释器进行不同的实验。
Inception Score(Salimans等,2016)被认为是样本相对于标记数据集质量的良好评估:
其中
表示一个样本,
是训练的标签分类器的softmax输出,
是生成的样本的标签分布。这个分数背后的直觉是强大的分类器通常对良好的样本有很高的置信度。但是,初始得分有时候不是一个好的指标。假设一个生成模型崩溃成一个非常糟糕的图像。虽然模型非常糟糕,但它可以具有完美的初始分数,因为
可以具有高熵并且
可以具有低熵。 相反,对于标记数据集,作者提出对视觉质量和样品种类的另一种评估,MODE评分:
其中 是训练数据中标签的分布。根据人类评估经验,MODE评分在一个指标中成功地测量了生成模型的两个重要方面:多样性和视觉质量。
但在没有标签的数据集(LSUN)中或标签不足以表征每种数据模式(CelebA)的情况下,上述指标不能很好地工作。相反,作者在真实数据和模型生成的数据之间训练第三方判别器。它类似于GAN判别器,但不用于训练生成器。这里可以将判别器的输出视为数量的估计量(参见Goodfellow等人,2014证明):
其中 是生成器的概率密度, 是数据分布的密度。 为了防止 学习 和 的完美分离,作者在训练 时向模型输入注入零均值的高斯噪声。训练之后,作者在真实数据集的测试集 上测试 。
如果是任何测试样品 ,判别值 接近1,可以推断模型中缺少对应于 的模式。通过这种方式,虽然无法准确测量丢失模式的数量,但对所有丢失模式的整体概率有一个很好的估计。
4 实验
4.1 MNIST
作者在MNIST上进行了两类实验。对于MNIST数据集,可以假设数据生成分布可以近似为十个主要的模式,这里将术语“模式”定义为数据流形的连通分量。
4.1.1 MNIST GAN模型的Grid Search
为了在提高稳定性和样本质量方面系统地探索正则化器对GAN模型的影响,我们在MNIST数据集上使用Grid Search来得到较好的GAN的超参数。Grid Search基于一对随机选择的损失权重: 。 作者对GAN和Regularized GAN使用相同的超参数设置,以及使用 表1 中的搜索范围。这里的网格搜索与Zhao等(2016)所提出的的类似。有关这些超参数的详细说明,请参阅那篇文献。

表1 网格搜索的超参数。
为了评估,作者首先在MNIST数字上训练4层CNN分类器,然后应用它来计算生成样本的MODE分数。各个模型的MODE得分分布如 图3 所示。显然,我们提出的正则化器显著提高了模式分数,从而证明了其在稳定GAN和提高样品质量方面的优势。
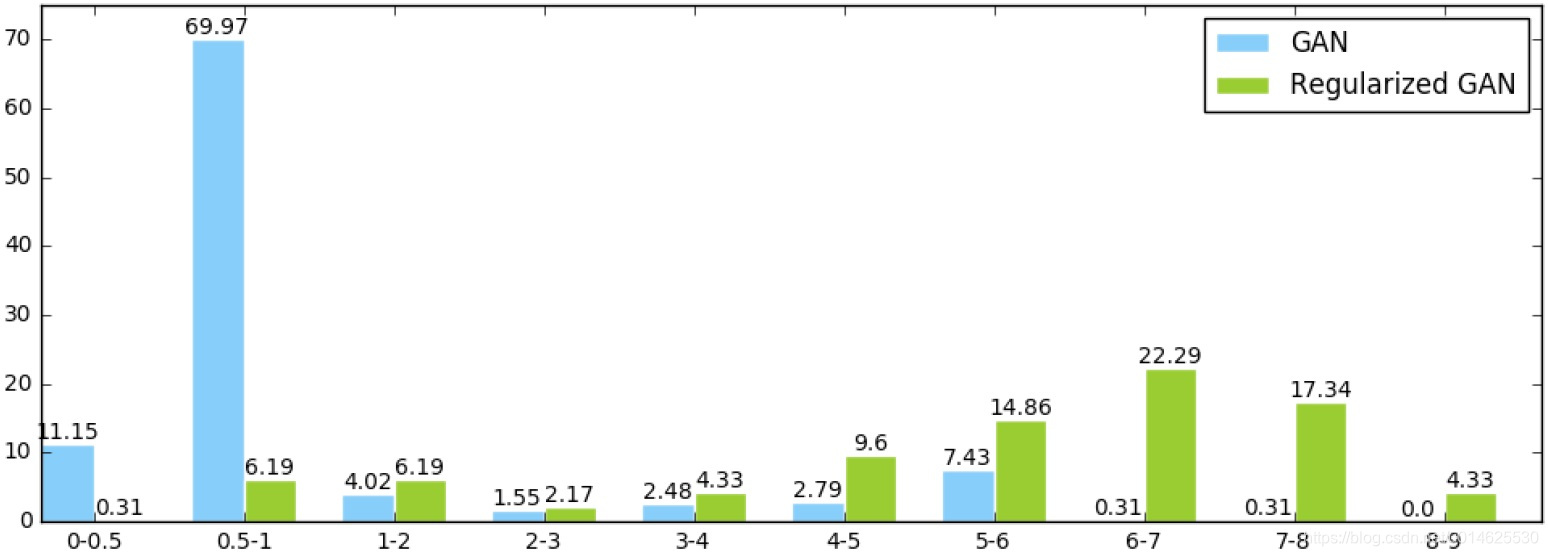
图3 GAN和正则化GAN的MODE分数的分布。

图4 :(左1-5)用于MNIST不同超参数的生成。(右6-7)通过Grid Search得到的GAN和正则化GAN的最佳样本。
为了说明具有不同参数的正则化器的效果,作者随机选择一个架构并用不同的λ1=λ2训练它。结果如图4所示。
4.1.2 有一千个模式的MNIST组合数据
为了定量研究正则化器对缺失模式的影响,作者将三个MNIST数字连接,形成64x64图像中的[0,999]中的数字,然后将DCGAN作为1000个模式数据集上的baseline模型进行训练。图像上的数字采用不同概率进行采样,以测试模型在生成中保留小模式的能力。作者使用预训练的MNIST分类器,而不是人来评估模型。
组合实验的表现通过两个指标来衡量。 #Miss表示分类器报告的丢失模式数,它是模型从不生成的数字集的大小。KL代表分类器生成数字分布与训练数据中数字分布之间的KL散度(与Inception Score中的一样)。结果如表2所示。在正则化器的帮助下,组合MNIST数据集的丢失模式和KL散度都急剧下降,这再次证明了正则化器用于防止丢失模式的有效性。

表2 具有1000种模式的组合MNIST的结果。所提出的正则化(Reg-DCGAN)方法可以显着减少遗漏模式的数量以及生成样本的合理性的KL散度。
4.2 CELEBA数据集
为了测试本文方法对更难问题的有效性,作者为DCGAN算法实现了一个编码器,并使用不同的超参数在CELEBA数据集上以DCGAN为baseline训练本文的模型。在附录B中提供了正则化DCGAN的详细架构。
4.2.1 CELEBA的损失模式的估计
作者还使用经过注入噪声训练的第三方判别器作为丢失模式估计的度量。为实现这一点,作者在判别器网络的输入层添加噪声。对于要估计的每个GAN模型,独立地训练这个噪声判别器作为模式估计器,在生成的数据和训练数据上具有相同的体系结构和超参数。然后,作者将模式估计器应用于测试数据。具有高模式估计的输出的图像可以被视为缺失模式。
比较结果如表所示 3. 我们提出的Regularized-GAN和MDGAN都优于所有设置的基线DCGAN模型。 特别是,MDGAN抑制其他模型,显示其在模式保留方面的优势。 我们还发现,虽然共享相同的架构,但具有200维噪声的DCGAN比使用100维噪声作为输入的DCGAN表现更差。 相反,我们的正规化GAN表现得更加一致。
为了更好地理解模型的性能,作者想要弄清楚这些模型何时何地丢失模式。对缺失模式的测试图像进行可视化是有益的。 在图5中,所有模型都丢失了左侧三张图像。在训练数据中很少看到第二个图像中有帽子的情况,和第三个图像中的背景类型,因此这些情况可以被看作小模式。这三个图像应被视为GAN学习中最难的测试数据。实验中最好的模型,MDGAN仍然捕获某些小模式。右侧的七个图像只有DCGAN错过了。这些图像中有一些特殊属性:侧面,苍白,黑色和贝雷帽,但MDGAN在所有这些图像上都表现良好。
 图5 处于丢失模式的测试集图像。左图:MDGAN和DCGAN都丢失了的图像。右:只有DCGAN缺失的图像。
图5 处于丢失模式的测试集图像。左图:MDGAN和DCGAN都丢失了的图像。右:只有DCGAN缺失的图像。
4.2.2 生成样本的定性评估
在定量评估之后,我们通过正则化的GAN手动检查生成的样品,以查看所提出的正则化器是否对样品质量具有副作用。 我们将我们的模型与ALI进行比较 (Dumoulin等, 2016), 瓦伊根(拉森等人, 2015), 和DCGAN (Radford等, 2015) 在样本视觉质量和模式多样性方面。 从这些模型生成的样本如图6所示。

图6 从不同生成模型生成的样本。对于每个比较模型,作者直接在相应的论文和代码库中报告十个比较好的样本。请注意MDGAN样本如何全局更连贯并且局部具有清晰的纹理。
MDGAN和Regularized-GAN都能生成清晰自然的脸部图像。虽然ALI的样本似乎是合理的,但与MDGAN相比,它们会有明显的变形。来自VAEGAN和DCGAN的样本似乎在全局范围内不那么连贯并且局部不那么合理。
至于生成的样本的质量,来自MDGAN的样本能够更少的失真。对于所有其他四种模型,大多数生成的样本都会遭受某种失真。然而,对于由MDGAN生成的样本与其他四个模型相比失真水平较低。作为改变生成流形的正则化器,作者将其归因于自动编码器的帮助。通过这种方式,生成器能够学习细粒度的细节,例如面部边缘。因此,MDGAN能够减少扭曲。

图7 Regularized-GAN和MDGAN生成的侧面样本。
在缺失模式问题方面,作者让五个人对生成的样本进行人工评估。他们达成了共识:即MDGAN在模式多样性方面获胜。其中两个人指出,MDGAN产生的侧面样本量大于其他模型。作者在图7中选择了几个侧面样品。显然,MDGAN的样本保持可接受的视觉保真度,同时共享不同的模式。结合上述定量结果,令人信服的是,我们的正规化器可以在不降低样品质量的情况下为训练稳定性和模式变化带来益处。
5 结论
尽管GAN在各种无监督学习任务中获得了最先进的结果,但训练它们被认为是高度不稳定的,非常困难且对超参数敏感,同时,数据分布中的丢失模式甚至是大的崩溃某些模式下的概率质量。成功的GAN训练通常需要大量的人力和计算工作来微调超参数,以便稳定训练并避免崩溃。 研究人员通常依靠自己的经验,技巧和超参数来训练GAN,而不是基于系统的方法来训练GAN。
作者提供了系统的方法来测量和避免丢失模式问题,并使用所提出的基于自动编码器的正则化器稳定训练。关键的想法是,一些几何度量可以提供比训练的判别器更稳定的梯度,并且当与编码器组合时,它们可以用作训练的正则化器。这些正则化器还可以惩罚丢失的模式,并鼓励在生成流形上公平分配概率质量。
致谢
作者感谢Naiyan Wang,Jianbo Ye,Yuchen Ding,Saboya Yang的GPU支持。还要感谢Huiling Zhen的有益讨论,Junbo Zhao 提供了关于EBGAN模型的网格搜索实验的详细信息,以及Anders Boesen Lindbo Larsen,他们帮助了VAEGAN实验的。感谢匿名审稿人提出的宝贵意见和建议。本工作受到了NSERC,Calcul Quebec,Compute Canada,Canada Research Chairs,CIFAR,国家自然科学基金(61672445和61272291),香港研究资助局(理工大学152094 / 14E),香港理工大学(G-YBP6)的部分支持。
参考文献
Emily L Denton, Soumith Chintala, Rob Fergus, et al. Deep generative image models using a laplacian pyramid of adversarial networks. In Advances in neural information processing systems, pp. 1486–1494, 2015.
Jeff Donahue, Philipp Kr¨ahenb¨uhl, and Trevor Darrell. Adversarial feature learning. arXiv preprint arXiv:1605.09782, 2016.
Alexey Dosovitskiy and Thomas Brox. Generating images with perceptual similarity metrics based on deep networks. arXiv preprint arXiv:1602.02644, 2016.
Vincent Dumoulin, Ishmael Belghazi, Ben Poole, Alex Lamb, Martin Arjovsky, Olivier Mastropietro, and Aaron Courville. Adversarially learned inference. arXiv preprint arXiv:1606.00704, 2016.
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, pp. 2672–2680, 2014.
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A Efros. Image-to-image translation with conditional adversarial networks. arxiv, 2016.
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, and Ole Winther. Autoencoding beyond pixels using a learned similarity metric. arXiv preprint arXiv:1512.09300, 2015.
Christian Ledig, Lucas Theis, Ferenc Husz´ar, Jose Caballero, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo-realistic single image super-resolution using a generative adversarial network. arXiv preprint arXiv:1609.04802, 2016.
Chuan Li and Michael Wand. Precomputed real-time texture synthesis with markovian generative adversarial networks. arXiv preprint arXiv:1604.04382, 2016.
Michael Mathieu, Camille Couprie, and Yann LeCun. Deep multi-scale video prediction beyond mean square error. arXiv preprint arXiv:1511.05440, 2015.
Luke Metz, Ben Poole, David Pfau, and Jascha Sohl-Dickstein. Unrolled generative adversarial networks. arXiv preprint arXiv:1611.02163, 2016.
Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784, 2014.
Anh Nguyen, Jason Yosinski, Yoshua Bengio, Alexey Dosovitskiy, and Jeff Clune. Plug & play generative networks: Conditional iterative generation of images in latent space. arXiv preprint arXiv:1612.00005, 2016.
Alec Radford, Luke Metz, and Soumith Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015.
Scott Reed, Zeynep Akata, Xinchen Yan, Lajanugen Logeswaran, Bernt Schiele, and Honglak Lee. Generative adversarial text to image synthesis. arXiv preprint arXiv:1605.05396, 2016.
Masaki Saito and Eiichi Matsumoto. Temporal generative adversarial nets. arXiv preprint arXiv:1611.06624, 2016.
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. arXiv preprint arXiv:1606.03498, 2016.
Casper Kaae Sønderby, Jose Caballero, Lucas Theis, Wenzhe Shi, and Ferenc Husz´ar. Amortised map inference for image super-resolution. arXiv preprint arXiv:1610.04490, 2016.
Carl Vondrick, Hamed Pirsiavash, and Antonio Torralba. Generating videos with scene dynamics. In Advances In Neural Information Processing Systems, pp. 613–621, 2016.
XiaolongWang and Abhinav Gupta. Generative image modeling using style and structure adversarial networks. In ECCV, 2016.
JiajunWu, Chengkai Zhang, Tianfan Xue, William T Freeman, and Joshua B Tenenbaum. Learning a probabilistic latent space of object shapes via 3d generative-adversarial modeling. In Neural Information Processing Systems (NIPS), 2016.
Junbo Zhao, Michael Mathieu, and Yann LeCun. Energy-based generative adversarial network. arXiv preprint arXiv: 1609.03126, 2016.
Yipin Zhou and Tamara L Berg. Learning temporal transformations from time-lapse videos. In European Conference on Computer Vision, pp. 262–277. Springer, 2016.
Jun-Yan Zhu, Philipp Kr¨ahenb¨uhl, Eli Shechtman, and Alexei A. Efros. Generative visual manipulation on the natural image manifold. In Proceedings of European Conference on Computer Vision (ECCV), 2016.