indexedDB
indexedDB 一般用于存储大规模“结构化”数据,很明显,越结构化的数据,计算器处理起来会越容易,这也是其优势。这个是session storage和local storage不如的,不过目前的兼容性一般。
/**
* 用于存储大规模结构话数据用的。
* 一个数据库存放多个object store,相当于表的概念
*/
function openDB(name, callback) {
// Create DB
var request = window.indexedDB.open(name)
request.onerror = function (e) {
console.log('Open indexedDB error')
}
request.onsuccess = function (e) {
myDB.db = e.target.result
console.log(myDB.db)
callback && callback()
}
// 1. 监听数据库中的数据的版本变化
// 2. 如果数据库没有存在,用于初始化数据版本
request.onupgradeneeded = function () {
// 数据库的存储格式为 key-object 形式,一个key值对应一个object对象。
var store = request.result.createObjectStore('books', {
keyPath: 'isbn'
})
// 简历索引
var titleIndex = store.createIndex('by_title', 'title', {
unique: true
})
var authorIndex = store.createIndex('by_author', 'author')
store.put({
isbn: 1,
title: 'Sherok homers',
author: 'Asir'
})
store.put({
isbn: 2,
title: 'Fire',
author: 'Crown',
})
}
}
var myDB = {
name: 'testDB',
version: '1',
db: null
}
openDB(myDB.name, function () {
// myDB.db.close();
// window.indexedDB.deleteDatabase(myDB.name)
})
function dataActions(db, storeName) {
// object store
var transaction = db.transaction('books', 'readwrite')
var store = transaction.objectStore('books')
// Add
store.add({
isbn: 3,
title: 'Flower',
author: 'xiaoQiang'
})
// Delete
store.delete(3)
// Update
store.put({
isbn: 2,
title: 'Fire',
author: 'Crown'
}).onsuccess = function (e) {
console.log(e.target.result)
}
// Search
store.get(2).onsuccess = function (e) {
console.log(e.target.result)
}
}
setTimeout(function () {
dataActions(myDB.db)
}, 3000)
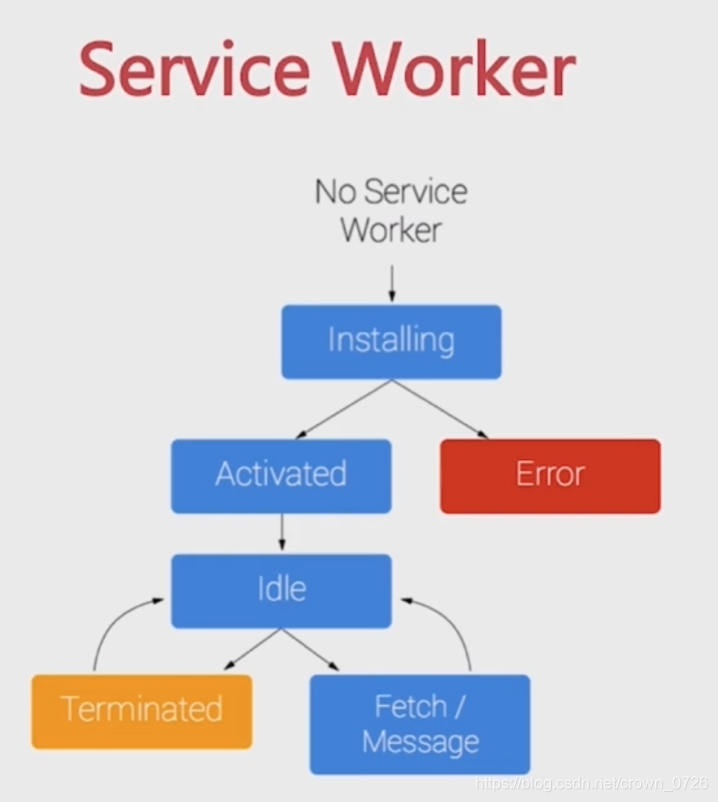
service workers
使得前端开始有了多线程,拥有使用拦截和处理网络请求的能力,去实现一个离线应用。使用service worker在后台运行同时能和页面通讯的能力,去实现大规模后台数据的处理。
- chrome://serviceworker-internals
- chrome://inspect/#service-workers
- 对页面做离线化,可以对数据进行拦截
- 和主页面进行通信
需要注意的是,service worker要在https的环境下才能生效,本定调试一定设置为localhost去调试。