
ajax:异步请求, 一定会有URL,请求方法,可能会有数据。 一般用json
https://movie.douban.com/j/chart/top_list?type=11&interval_id=100%3A90&action=&start=20&limit=20

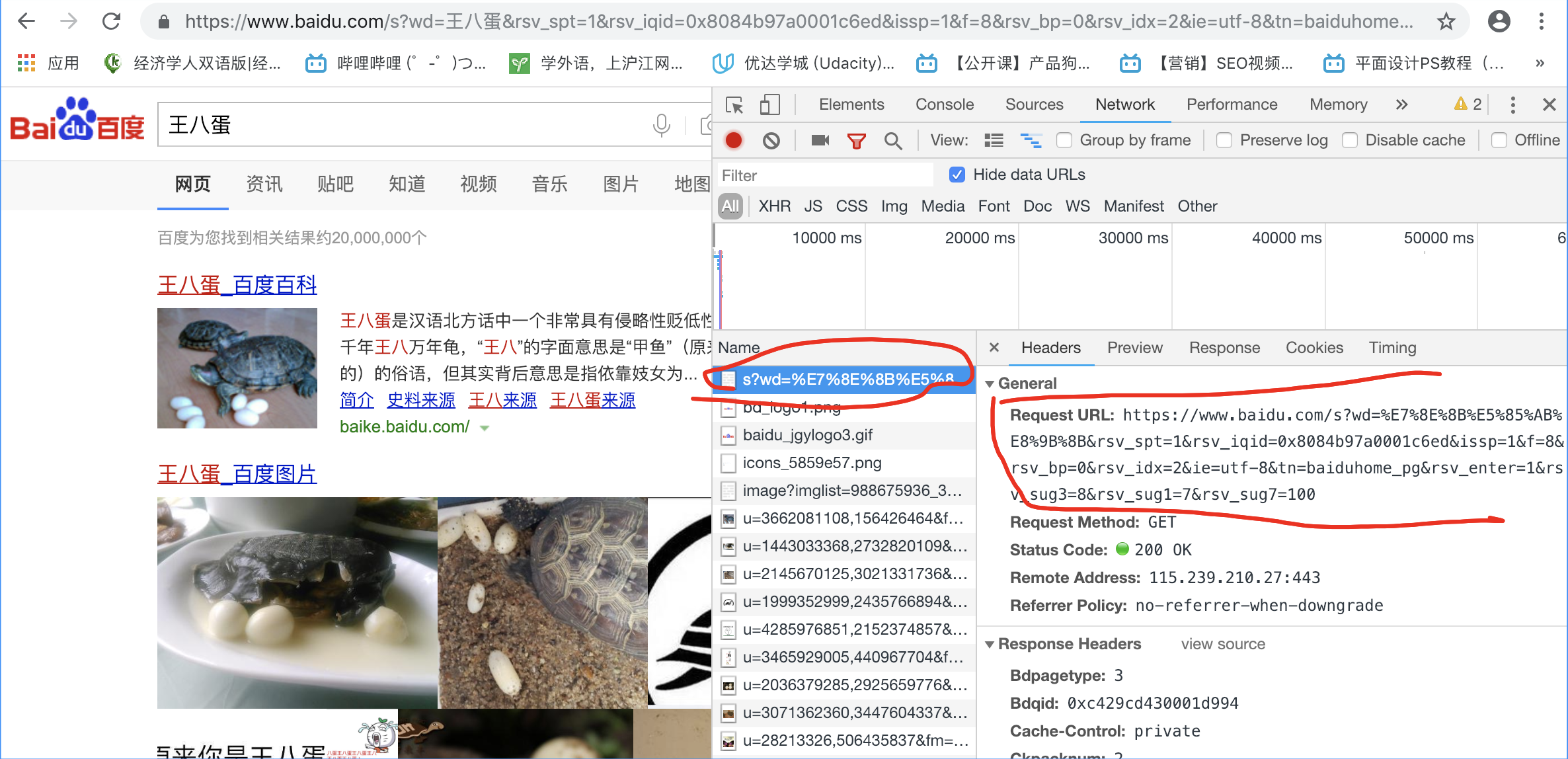
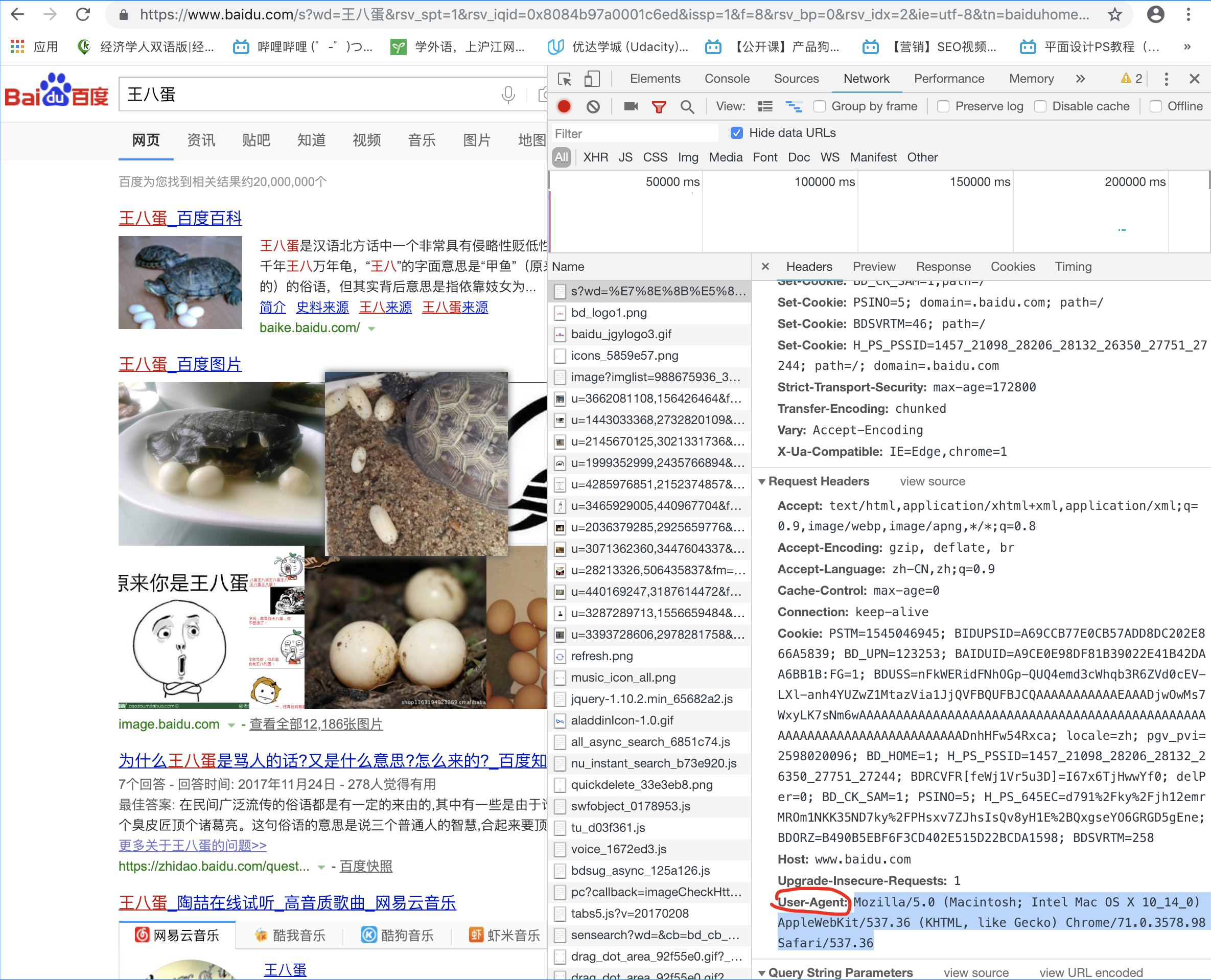
Requests: 继承了urllib所有特征,底层使用的是urllib3
get请求:requests.get(url)
requests.request('get',url)
可以带有params 和 headers参数


post
-rsp = requests.post(url, data=data)
data headers 要求dict类型
proxy:
proxies = {
'http':'address of proxy'
'https':'address of proxy'
}
rsp = requests.request('get', 'http:xxxxxxxx', proxies = proxies)
有可能会报错,如果使用人数过多,考虑安全问题,可能会被强行关闭
用户验证:
-代理验证
#可能需要使用HTTP basic Auth‘
#格式为 用户名:密码@代理地址:端口地址
proxy = {'http': 'xxxxx:[email protected]:xxxx'}
rsp = requests.get('http://baidu.com', proxies = proxy)
web客户端验证:需要添加auth = (用户名,密码)
auth = ('用户名', '密码')
rsp = requests.get('http://www.baidu.com', auth = auth)
cookie
requests可以自动处理cookie信息
rsp = requests.get('http://xxxxxxxxxxxx')
#如果对方服务器传送过来cookie信息,则可以通过反馈的cookie属性得到
#返回一个cookiejar的实例
cookiejar = rsp.cookies
#可以将cookiejar转换成字典
cookiedict = requests.utils.dict_from_cookiejar(cookiejar)
session:
#创建session对象
ss = requests.session()
headers = {'User-Agent': 'xxxxxxxxxxxxxxx'}
data = {'name': 'xxxxxxxxxxxx'}
#此时,发出的请求由session管理
ss.post('http://www.baidu.com', data = data, headers = headers)
rsp = ss.get('xxxxxxxxxxxxx')
https请求验证ssl证书
- 参数verify负责表示是否需要验证ss证书,默认是True
- 如果不需要验证ssl 证书, 则设置成false表示关闭
rsp = requests.get('https://www.baidu.com', verify = false)