撸了一整天Aardvark,总结记录一下,可能有些地方理解的也不是很到位。
Aardvark: http://static.usenix.org/events/nsdi09/tech/full_papers/clement/clement.pdf
摘要:
提出了构建BFT系统的新方法。目前的BFT系统运行的很快,但是都不能很好的应对拜占庭错误。只要一个坏的client就能让包括PBFT、Q/U/、HQ、Zyzzyva等系统不可用。所以论文提出了1、现有协议的缺点;2、在拜占庭错误发生时系统可用的原则。3、提出构建BFT系统的新方法:Aardvark。其性能在无拜占庭错误和有拜占庭错误差异不大。
介绍:
Aardvark的性能在有没有拜占庭错误基本一致。而其他的就不行啦,在primary坏掉或者副本恢复的时候都可能造成如此严重的情况。本文提出的算法,更改了以往的思路,不注重极限的性能,在保证可以接收的吞吐量的情况下更广泛的去处理错误发生的情况。Aardvark在某些方面跟其他的BFT算法类似,都是client请求primary,但是其他的方面却很大不同。
Aardvark采用签名认证而之前的系统尽力避免它、采用常规的view-change而之前的技术则是做为最后的选择,p2p技术而之前的系统多采用IP广播。看起来Aardvark这些选择都会降低了吞吐,但是实际看来降低的有限却在容错上有很好的表现。

系统模型:
节点N=3f+1 f为最大拜占庭错误节点数。 客户端可以任意多为恶意节点。恶意节点可以串谋但无法解决密码学加密问题。异步网络条件下有个同步时间间隔,消息会在有限的延迟时间里提交。
定义1:(Synchronous interval):同步时间间隔里,任意消息会在一个有限的时间T内得到执行(有重发策略)。
定义2:(Gracious execution):所有的节点以及客户端都是好的。
定义3:(Uncivil execution):最多f个节点是拜占庭节点、可以有任意多个恶意client。
目前的BFT系统具有着误导性、危险性、徒劳性。真正的BFT系统不能这么玩儿,它应该满足以下原则:1、可要接受的性能;2、易于部署;3、能够应对拜占庭错误切让系统原理错误。有限度地降低最高吞吐量来保证在发生拜占庭错的时候系统仍然能以可接受的吞吐量运行会比只追求高吞吐量而一旦发生拜占庭错误系统就几乎不可用之间当然是前者更为合适。
Aardvark实现:
Aardvark分为个阶段:1、请求分发(request distribution);2、一致性协议(agreement);3、视图更换(view change)
Aardvark实现上述三个原则主要通:1、签名的客户端请求;2、资源隔离;3、定期视图更换。
签名的客户端请求:
通过数字签名手段来对客户端请求签名,不采用安全性更弱的MAC方式。数字签名比较昂贵,因此,Aardvark只在客户端请求的时候做这个。副本之间以及副本通客户端之间的通信都采用MAC方式(副本的通信不会引起安全问题,因副本是一个群体,一个副本是坏的不影响整个群体正常运行,所以不用这么昂贵的验证方式)。防止客户端denial-of-service攻击的方法:1、采用MAC以及数字签名的混合验证法(hybrid MAC-signature construct),限制客户端提交错误验证的次数。2、在客户端提交下一个请求之前必须先完成前一个请求。3、限制客户端提交正确签名的数量(限流?)
资源隔离:
Aardvark将网络和计算资源隔离开。


如图,每个replica跟别的replica通信都是采用独立的网卡和网线。这样做可以防止坏的节点破坏整个网络(如果不独立,会怎么去破坏?) Aardvark在client与每个replica通信时采用单独的队列,这样做可以防止客户端的请求淹没了replica之前的通信(啥意思。。?)统一对于每个replica也使用一个对列允许Aardvark对消息进行调度来保证replica能够获取这个歌集群的信息。Aardvark放弃来广播方式会造成吞吐量损失,而且也丧失了扩展性,因为系统的网络连接数是O(f^2)级别的。资源的隔离可以充分利用硬件的并发性来处理来自client和replica的请求。
定期视图更换:
为了防止primary作恶,Aardvark采用定期视图更换的方法。replica监控当前primary的性能并逐渐增加其满足最小吞吐量的限制,一旦当前的primary不能达到最小吞吐量限制,触发试图更换。
传统的协议采用view-change都是作为最后的手段来防止系统的吞吐不至于跌到0(查一下PBFT具体何时采用view-change)。虽然view-change会造成一段时间的请求不可用,但是其带来的安全习惯好处价值更高。
协议描述:
1、请求分发
客户端发下面格式请求给primary,如果客户端没有及时收到此请求的相应,则重发请求给所有的replica(PBFT等都是这样,因为primary可能是坏的,replica可以通过这个来判断primary是否是坏的并发起view change流程)。
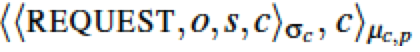
(o为请求,s为请求编号,c为客户端,还有数字签名以及MAC验证)
replica接到client请求后做如下验证:
1、黑名单验证。如果不在黑名单里,执行2,不然的话丢弃。
2、验证MAC。如果过了3,不过丢弃。
3、序列号验证。验证最近缓存的对c的请求返回,如果请求的序号s是下一个号,则4.否则
3a:验证重传。replica利用指数退避算法(https://blog.csdn.net/chdhust/article/details/48524511)
来限制客户端重试。如果没有回应客户端则吧最近的结果返回给客户端。否则丢弃。(保证必须前一个请求处理以后才会往后走,限制了速率)
4、冗余检查。检查最近缓存的客户端c的请求,如果之前从c哪里没有获取到序号为s的请求(缓存是为了防止重复的请求导致重复的前签名)则执行5.否则
4a:每个视图检查一次:如果在之前的视图中验证过请求但是在当前视图里没有执行,则执行这个请求,否则丢弃。(在视图变更时保证请求能够得到执行,但是同一个视图里不可重复执行)
5、验证签名。签名有效则继续执行请求,否则加入黑名单,丢弃。(黑名单有效期10分钟)

primary和backup执行请求的方式不一样:
primary会执行PRE-PREPARE阶段内容。
backup会验证primary发来的MAC认证(PRE-PREPARE),转发请求给primary一次(客户端直接送过来的,前面有讲),如果是之前收到过req则直接丢掉

资源调度:
Aardvark通过不同的队列以及replica之间的通信来限制恶意客户端能够耗尽节点资源的数量。保证流量攻击的并不会影响已经提交的请求执行。实现的时候,采用双核机器,一个核来验证客户端请求,另一个核执行replica协议(哈?验证和执行没有先后关系吗?不能并发吧?这里分成俩线程是说验证线程就算有问题了那么执行线程也会继续执行已经提交的请求儿不受影响吧?)。
最大最小分析:
有五个操作会导致replica资源的消耗:消息接收(receive message), MAC验证(verify MAC), 重传缓存信息(retransmit cached reply), 签名验证(verify signature), 执行请求(and process request)
在这五个阶段已经降低了非法请求的速率。
一致性协议:
Aardvark通过标准的三项协议来达成排序一致(见PBFT:https://blog.csdn.net/oXiaoBuDing/article/details/85289561)
资源调度:
Aardvark采用多个物理队列来处理不同的replica消息,这样做一方面可以让replica保证消息处理的公平性,另一方面可以消除其他replica的对网络的滥用(1对1的网卡和请求队列)
当某个replica收到多个来自不同的replica的请求时采用轮询方式处理,保证了当一个消息在接收时到被执行期间最多有n-2个消息呗处理,同时能够避免消息的单点错误还能加快PREPARE和COMMIT阶段消息的收集(why?)
对网络进行分离也可以禁用终端某个坏节点的网卡。当一个replica的消息传输速率是其他replica的20倍以上的时候,切断此replica的网络连接(同一个view下),此replica会在10分钟后重新连接或者另一个replica呗切断网络也会重新连接。
最大最小分析:
backup节点会发送PREPARE 和COMMIT消息,但是只有他们拿到足够多的前置消息(前文所述流程)才会行动,因此,单个坏的replica是无法造成其他好的replica作出错误行为。
由于单个的消息无法对系统造成较大影响,所以坏的replica最好的选择就是flooding攻击,通过flooding来增加额外的MAC验证和系统中断。而轮询策略(round robin scheduling)又保证了坏的replica无法去影响其他replica的信息接收和执行。造成系统中断的flood请求会通过关闭相应的网卡来断绝此replica的消息传递保证系统安全。
State Catchup messages:
之前没有谈论到State Catchup messages。State Catchup messages主要是用来让速度慢的replica赶上来。策略主要是replica会吧自己的状态发送给其他副本,其他副本会恢复它它可能缺少的状态信息。由于此信息不需要集群工作,所以坏节点可以利用这一点系统造成影响。但是只要系统在运行,对于状态的消息处理就会采用资源调度方式。因此Catchup message的执行不会造成系统速度降低。
视图更改:
更改方式与PBFT一样,不过这里触发机制不同,是通过replica的性能监控来触发周期性的视图更改(需要primary满足最低吞吐量要求,但是replica会不断提升这个吞吐量直到primary不满足)。同时每个replica都有一个hearbeat timer来监听PRE-PREPARE message,如果时间到了还没收到则发起试图更改。如果因为timer造成的视图更改,则replica会降timer的时间加倍,当收到PRE-PREPARE后再吧timer恢复成初始值