今天在CM安装的CDH的大数据管理平台上集成kafak,遇到的一些坑,记录下来:
我安装的CM是5.14.0.在这个版本当中他没有被纳入到CDH的安装平台,所以他需要安装激活等操作,和我们手动集成spark2的操作是一样的。
(1)第一步下载parcels
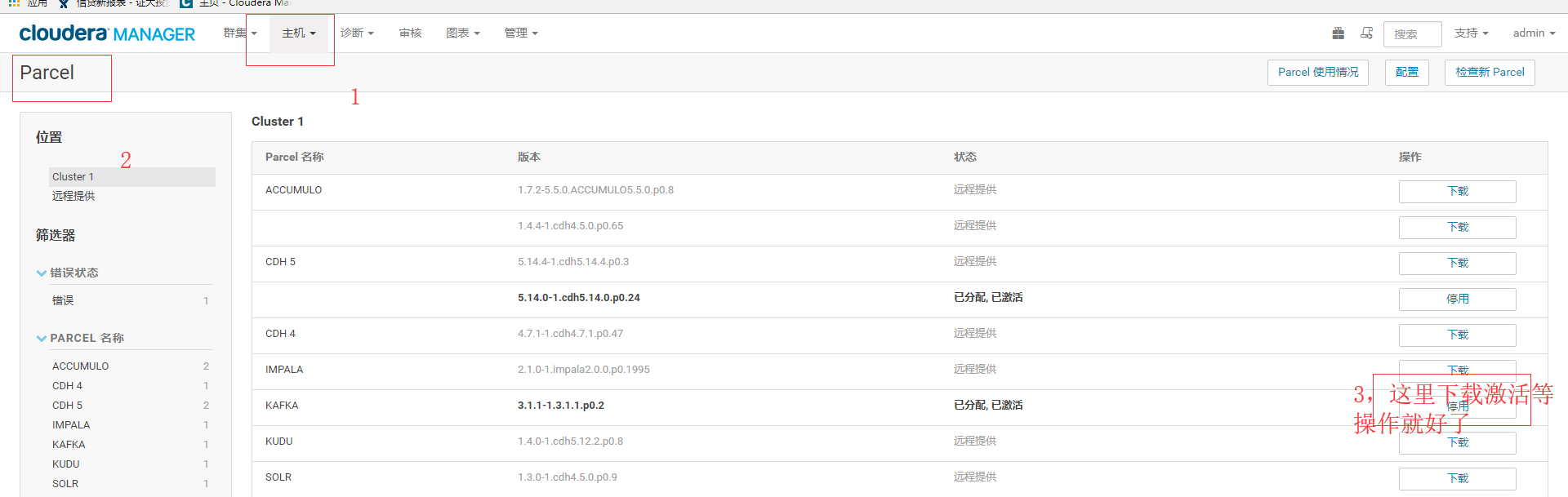
(2) 然后在我们的集群当中就出现了kafka相关的安装包

然后去目录/opt/cloudera/parcels/KAFKA/etc/kafka/conf.dist 下面修改server.properties的相关的参数配置。主要修改如下参数:
broker.id=1 这个参数唯一标示broker,每一台都需要不同。
zookeeper.connect=10.100.200.11:2181,10.100.200.12:2181,10.100.200.13:2181 这个地方是我们用的zookeeper的配置,我们不使用kafka自带的zookeeper,要使用我们集群当中配置的zookeeper.
其他的可以参照官网自行配置;
(3)然后到cm的管理界面对kafka的服务进行添加。
在这里需要注意的是,除了我们配置的broker之外,有一个kafak MirrorMaker,说白了就是跨集群进行数据消费的东西,感觉用不到就没装。
除此之外我们他会包heap,也就是Java的jvm的问题。很常见的问题修改一下就好了
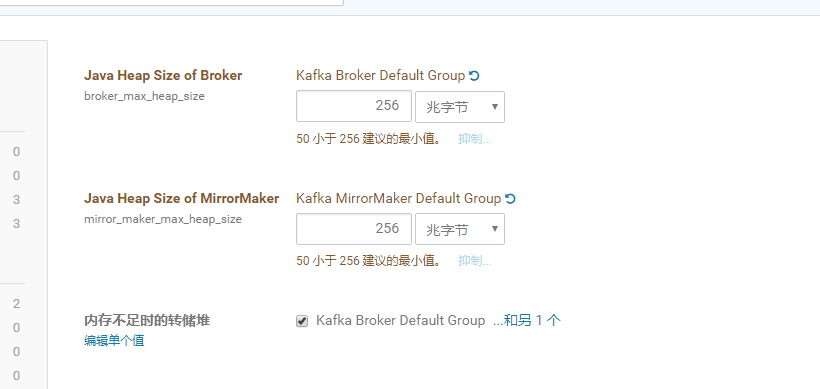
然后再次启动就可以了,整个服务都启动了。

启动不就发现有点小异常,然后卸载掉了,发现再装的时候就各种报错。这可咋整。原来我们在装kafka的时候的相关目录没有删除掉,导致我们安装不成功(kafka的数据目录和kafka相关的topic没有删除)

删除上面这个目录。除此之外我们还要删除相关的topic ,直接使用命令行删除是删除不了的,因为kafka是通过zk管理的所有我们去zk里面就删除相关的信息:


删除了这些东西,我们就是可以继续的添加服务了,这次就不会再报错。
参考文章如下:
http://www.aboutyun.com/thread-22035-1-1.html
https://blog.csdn.net/weixin_43840194/article/details/85252015