本文介绍超图大数据产品spark组件,iServer产品中的分布式分析服务,如何在部署好的spark集群,hadoop集群中采用spark on yarn模式提交任务进行空间大数据相关的分析。
一、环境
1. Ubuntu server 16,三个节点的hadoop集群和spark集群,一个客户端机器。
2. hadoop 2.7,spark 2.1,集群已部署好,未开启kerberos认证
3. iobjects for java 910,iobjects for spark 910,iServer 910,未部署
二、部署超图产品
-
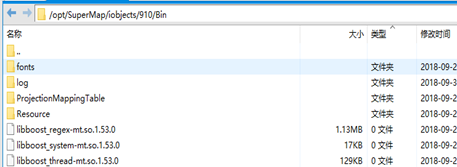
hadoop集群的每个节点机器上部署java组件,解压java组件产品,将bin目录下文件放入指定目录“/opt/SuperMap/iobjects/910/Bin”,确保Bin目录有读写权限。
-
hadoop集群的每个节点机器上配置试用许可,根据集群名称(hostname)在官网申请试用许可,将许可文件放入每个机器的目录“/opt/SuperMap/License”。
-
客户端机器上部署spark组件和iServer产品,将spark组件解压,iServer产品目录解压,在iServer产品里安装依赖库,安装许可驱动(这一步参考iServer的文档)。
-
配置iServer下自带的spark配置文件spark-default.conf ,添加yarn集群地址,am内存参数等,如下图。

-
将hadoop集群的配置core-site.xml,hdfs-site.xml,yarn-site.xml文件拷贝到客户端机器的目录/opt/SuperMap/hadoop-cdh,这个目录可自行选择。
-
进入iServer的bin目录,启动iServer,执行” startup.sh”,进入iServer管理页面,按下面截图步骤配置分布式分析服务,配置前需启动hadoop集群




-
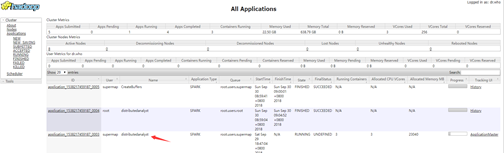
配置完后,在yarn集群的ui界面查看应用是否有分布式分析服务的任务,如下图
-
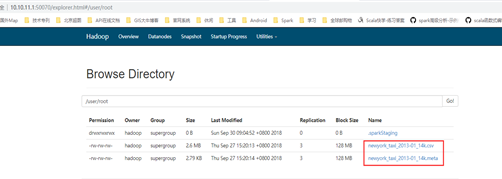
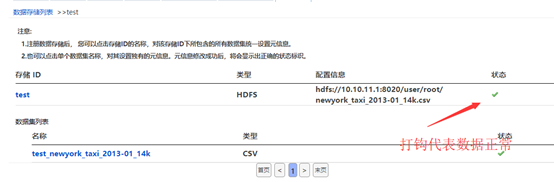
用iServer将自带的示例csv数据,注册到hdfs系统里,按截图步骤操作



三、用iServer提交点密度分析,进入“分布式分析服务”—“创建分析”,(确保hadoop集群机器上没有超图的spark的lib包,如果有,请保持与iServer自带的版本保持一致。)正常结果如下截图


四、用spark组件提交大数据分析任务
-
Cluster模式提交,Cluster模式建议采用分布式存储数据,这里使用的udb是本地存储,生成的结果不一定在driver端目录下,可能在参与计算的某个worker节点目录下。
./spark-submit --master yarn --deploy-mode cluster --driver-memory 6g --executor-memory 6g --executor-cores 4 --class com.supermap.bdt.main.CreateBuffersMain /opt/SuperMap/test-yarn-cluster/com.supermap.bdt.core-9.1.0-16402.jar --input '{"type":"udb","info":[{"server":"/opt/SuperMap/test-yarn-cluster/testdata.udb","datasetNames":["Railway"]}]}' --distance 100 --output '{"type":"udb","server":"/opt/SuperMap/test-yarn-cluster/testBufferOut10.udb","datasetName":"RailwayBuffer"}'- client模式提交,生成的结果是driver端。
./spark-submit --master yarn --deploy-mode client--driver-memory 6g --executor-memory 6g --executor-cores 4 --class com.supermap.bdt.main.CreateBuffersMain /opt/SuperMap/test-yarn-cluster/com.supermap.bdt.core-9.1.0-16402.jar --input '{"type":"udb","info":[{"server":"/opt/SuperMap/test-yarn-cluster/testdata.udb","datasetNames":["Railway"]}]}' --distance 100 --output '{"type":"udb","server":"/opt/SuperMap/test-yarn-cluster/testBufferOut10.udb","datasetName":"RailwayBuffer"}'
五、使用shell交互式提交任务,在spark/bin目录按如下步骤执行命令即可
-
启动spark-shell
./spark-shell --master yarn --deploy-mode client --jars /home/yb/opt/supermap-spark-9.0.0/lib/com.supermap.bdt.core-9.1.0.jar./spark-shell --master yarn --deploy-mode client --jars /home/yb/opt/supermap-spark-9.0.0/lib/com.supermap.bdt.core-9.1.0.jar -
导入类,import com.supermap.bdt.io.simpleCSV.SimpleCSVReader
-
执行读取csv数据(数据路径改为自己的),val fRDD = SimpleCSVReader.read(sc, “hdfs://myspark-master:9000/input/newyorktaxi/newyork_taxi_2013-01_14k.csv”)
-
查看结果,数据集的记录总数,fRDD.count()