大数据的4个特点:数据量大、数据类型繁多、处理速度快、价值密度低。
大数据对思维方式的影响:大数据时代最大的转变就是思维方式的3种转变:全面而非抽样,效率而非精确,相关而非结果。
大数据技术两大核心技术:分布式存储,分布式处理。
大数据计算模式:批处理计算、流计算、图计算、查询分析计算。
云计算处理了两大核心问题:海量数据的分布式存储和分布式处理的问题。
云计算的典型特征:虚拟化和多租户。
云计算的概念:通过网络以服务的方式,为用户提供非常廉价的IT资源,这叫做云计算。


大数据与云计算、物联网的关系:云计算为大数据提供了技术基础,大数据为云计算提供了用武之地。物联网是大数据的重要来源,大数据是物联网数据分析提供支撑。云计算为物联网提供了海量数据存储能力,物联网为云计算提供了广阔的应用空间。

Hadoop的特性:高可靠性、高效性、高可扩展性、高容错性、成本低、运行在Linux系统上、支持多种编程语言。
从Hadoop1.0到hadoop2.0的变化:

一个安装上的小细节:

试述hadoop生态系统以及每个部分的具体功能。
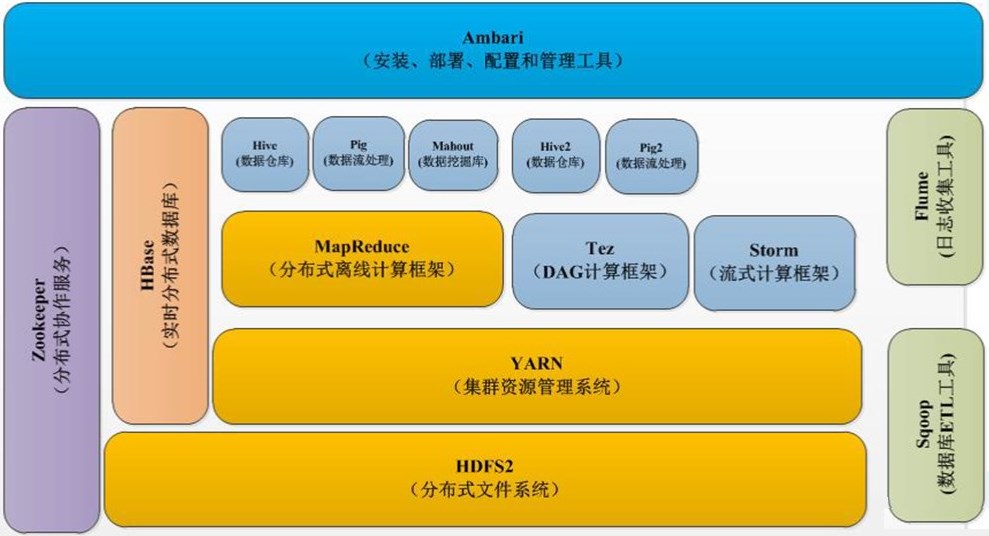
Hadoop生态系统:HDFS、YARN、MapReduce、Hive、Pig、Mahout、HBase、Zookeeper、Sqoop、Flume、Ambari
HDFS:作为一个分布式文件系统,具有整体可用性和高可靠性,负责底层数据存储。
YARN:作为一个集群资源管理系统,负责
MapReduce:是一种分布式离线计算框架,用于大规模数据集的并行运算,负责完成海量数据的处理。
Hive:用于对Hadoop文件中的数据集进行数据整理、特殊查询和分析存储。
Pig:是一种数据量语言和运行环境,用来查询大型半结构化数据集。
Mahout:数据挖掘库件,提供了许多经典算法的实现。
HBase:是一个提供高可靠性、高性能、可伸缩、实时读写、分布式的列式数据库,具有强大的非结构化数据存储能力。
Zookeeper:是高效和可靠的协同工作系统,提供分布式锁、统一命名、状态同步、集群管理、分布式应用配置项的管理等基本服务。
Sqoop:可以通过JDBC和关系数据库交互,主要用于Hadoop和关系数据库直接交换数据。
Flume:负责收集数据,是一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统。
Ambari:是一种基于Web的工具,支持Apache Hadoop集群的安装、部署、配置和管理。
Hadoop两大核心:HDFS和MapReduce,二者解决大数据两大核心问题,二者都是由谷歌公司提出的。
Hadoop安装方式3中 单机,伪分布式,完全分布式
伪分布式安装重要的配置文件:core-site.xml (hadoop core的配置项)
hdfs-site.xml(hadoop的守护进程) mapred-site.xml(mapreduce的守护进程)
Hadoop的安装与使用 :











分布式文件系统:目前已经得到广泛应用的分布式文件系统主要是GFS和HDFS。
HDFS的文件模型:HDFS采用了“一次写入,多次读取”的简单文件模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取。
HDFS块的概念,是HDFS中最核心的概念之一,在传统的文件系统中,为了提高磁盘读写效率,一般以数据块为单位。而不是以字节为单位。HDFS也同样采用了块的概念,hadoop1.0当中默认的一个块的大小是64MB,hadoop2.0当中默认的一个块的大小是128MB。与传统文件系统中块的联系是:都是为了分摊磁盘读写开销,也就是在大量数据间分摊磁盘寻址的开销。区别,比传统的文件系统中块的大小大得多。
HDFS两大组件:名称节点和数据节点
名称节点是整个HDFS集群的管家,提供数据目录服务。记录了每个文件中各个块所在的数据节点的位置信息,但是并不持久化存储这些信息,而是在系统每次启动时扫描所有数据节点重构得到这些信息。
数据节点是分布式文件系统HDFS的工作节点,负责具体的数据的存储和读取。会提供给客户端或者名称节点的调度来进行数据的存储和检索,并且想向名称节点定期的发送自己所存储的块的列表。每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
第二名称节点的2大功能:EditLog与FsImage的合并操作;作为名称节点的“检查点”。
HDFS的存储原理包括:数据的冗余存储、数据的存取策略、数据错误与恢复。
数据冗余存储的三个优点:加快数据传输速度,容易检查数据错误,保证数据的可靠性。
数据存取策略包括:数据存放、数据读取和数据复制等方面。3.4节。
数据的存储策略:Hdfs存储策略: 默认冗余复制因子是3 即每一个文件块同时保存到3个地方 2份放到同一个机架的不同机器上,另一个放不同机架上
HDFS的数据读写过程。
读数据过程:
1客户端通过FileSystem.open()打开文件。
2在DFSInputStream的构造函数中输入流会通过ClientProtocal.getBlockLocations()远程调用名称节点,获得文件开始部分数据块的保存位置。
3获得输入流FSDataInputStream后,客户端调用read()函数开始读取数据。
4数据从该数据节点读到客户端。
5输入流通过getBlockLocation()方法查找下一个数据块。
6找到该数据块的最佳数据节点,读取数据。
7当客户端读取数据完毕时,调用FSDataInputStream的close()函数关闭输入流
写数据过程:
1 客服端通过FileSystem.create()创建文件。
2.distributedfilesystem通过RPC远程调用名称节点。
3获得输入流FSDataOutputStream后,客户端调用输出流的write方法向hdfs中对应的文件写入数据。
4客户端向输出流FS中写入的数据会被分成一个个分包,放入df对象队列内部。
5 数据节点位于不同节点上,数据需要通过网络发送
6.客户端调用close方法关闭输入流


利用Web界面查看hadoop信息:http://localhost:50070
BigTable名词解释:是一个分布式文件系统,利用谷歌公司提出的MapReduce分布式并行计算模型来处理海量数据,并用谷歌分布式文件系统GFS作为底层数据存储,采用Chubby提供协同服务管理,具有广泛应用性、可扩展性、高性能和高可用性等特点。
Hbase的功能组件:最核心的功能组件有三个,库函数、Master服务器、Region服务器。
HBase检索支持的三种方式
(1) 通过单个Rowkey访问,即按照某个Rowkey键值进行get操作,这样获取唯一一条记录;
(2) 通过Rowkey的range进行scan,即通过设置startRowKey和endRowKey,在这个范围内进行扫描。这样可以按指定的条件获取一批记录;
(3) 全表扫描,即直接扫描整张表中所有行记录。






客户端是如何访问数据的(客户端访问数据库流程): 先访问zookeeper,获取-root-表位置信息,在访问-root-表获得.META.表信息,访问.META.表,找所需region具体位于那个region服务器,最后从服务器读取数据。
Hbase依靠hdfs存储底层数据,依赖zookeeper提供消息通信机制。
非关系数据库:NoSQL4大类型:键值数据库,列族数据库,文档数据库,图数据库
NoSQL的三大基石:CAP、BASE和最终一致性
CAP:一个分布式系统不可能同时满足一致性,可用性,分区容忍性,最多同时满足其中两个
ACID:a:原子性 事务必须是原子工作单元 C:一致性 事务完成时数据保持一致 I隔离性 由并发事务所做的修改与其他隔离 D持久性 完成后对系统影响是永久的
BASE具体含义:基本可用,软状态,最终一致性
NoSQL的四大类型:









云数据库系统架构之UMP系统概述、系统架构、系统功能
UMP概念:UMP系统是低成本和高性能的MySQL云数据库方案,关键模块采用Erlang语言实现
UMP系统架构:Controller服务器,Proxy服务器,Agent服务器,Web控制台,日志分析服务器,信息统计服务器,愚公系统。
UMP系统的功能:容灾,读写分离,分库分表,资源管理,资源调度,资源隔离,和数据安全功能。
UMP系统组件及其作用:1、Mnesia:是一个分布式数据库管理系统;2、RabbitMQ:是一个用Erlang开发的工业级的消息队列产品;3、Zookeeper是高效的可靠的协同工作系统,提供分布式锁之类的基本服务;4、LVS:即Linux虚拟服务器,是一个虚拟的服务器集群系统。
UMP系统实现资源隔离的两种方法:1用Cgroup限制MySQL进程资源2在Proxy服务器端限制QPS
UMP的三种规格用户:1数据量和流量比较小的用户2中等规模用户3需要分库分表的用户
UMP主从备份:UMP为每个用户创建两个MySQL实例,一个是主库,一个是从库,而且这两个MySQL实例之间会互相把对方设置为备份机,任意一个MySQL实例发生更新都会复制到对方。
MapReduce模型简介





MapReduce的两大核心组件:JobTracker、TaskTracker
MapReduce有两个重要的地方:一个策略:分而治之的策略,一个理念:计算向数据靠拢,将应用程序分发到数据所在的机器上,也就是数据不需要迁移,计算就可以在数据节点上进行,执行相关的运算,完成运算得到结果。采用了master/slave的架构。两个核心的函数:Map、Reduce。
溢写(分区,排序,合并)在溢写到磁盘之前,缓存中的数据首先被分区,缓存中数据是<key,value>形式键值对,对于每个键值对,后台根据key进行内排序,排序是mapreduce默认操作,合并是将相同key的<key,value>的value加起来;归并:相同key的键值对归并成一个新的键值对


存放到分布式文件系统HDFS中,首先执行的时候,要先从分布式文件系统HDFS中加载文件,然后对一个大数据集进行分片操作,split,然后每一个小分片单独启动一个map任务,让它去负责处理这个小分片,这些map任务的输入是key和value,输出也是key和value,发送到不同的reduce上进行后续的处理。Map的输出是要分区的,分区的多少要取决于reduce机器的数量。就是把map的输出结果进行排序归并合并操作。这个过程叫做shuffle。整个shuffle过程结束以后,才会把相应的结果分发给reduce,让reduce去完成整个数据的处理,最后处理结束输出保存到分布式文件系统中。
MapReduce的各个执行阶段:从分布式文件系统读入数据、执行map任务输出中间结果、通过shuffle阶段把中间结果分区排序整理后分发给Reduce任务、执行Reduce任务得到的最终结果并写入分布式文件系统。
Shuffle的过程详解:是指对map输出结果进行分区、排序、合并等处理并交给reduce的过程。输入数据和执行map任务,写入缓存,溢写,文件归并;领取数据,归并数据,把结果输入给reduce任务。
所谓合并,是指将那些具有相同key的<key,value>的value加起来。
所谓归并,是指对于那些具有相同key的键值对会被归并成一个新的键值对。
HDFS的新特性
HDFS HA:
HDFS 联邦:HDFS1.0采用单名称节点的设计,存在单点故障、可扩展性低、性能和隔离性差。在HDFS2.0当中,引入了HDFS联邦这一机制,即设计了多个相互独立的名称节点,使得HDFS的命名服务能够水平扩展,这些名称节点分别进行各自命名空间和块管理,相互之间是联邦关系,不需要彼此协调。
YARN的发展目标:YARN目标实现“一个集群多个框架”,即在一个集群上部署一个统一的资源调度管理框架YARN,在YARN上可以部署其他各种计算框架,由YARN为这些计算框架提供统一的资源调度服务,并且能够根据各种计算框架的负载需求,调整各自占用的资源,实现集群资源的利用源弹性收缩。
Kafka:Kafka一种高吞吐量的分布式发布订阅消息系统,在大数据平台中,Kafka扮演了数据交换枢纽的角色。