版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a19990412/article/details/85307056
简述
MPI用于在windows下的高性能计算
目前主要用于在超级计算机上的并行计算
所以有兴趣的做超级计算方面的,或者对这个感兴趣的,学习下这个也蛮好的
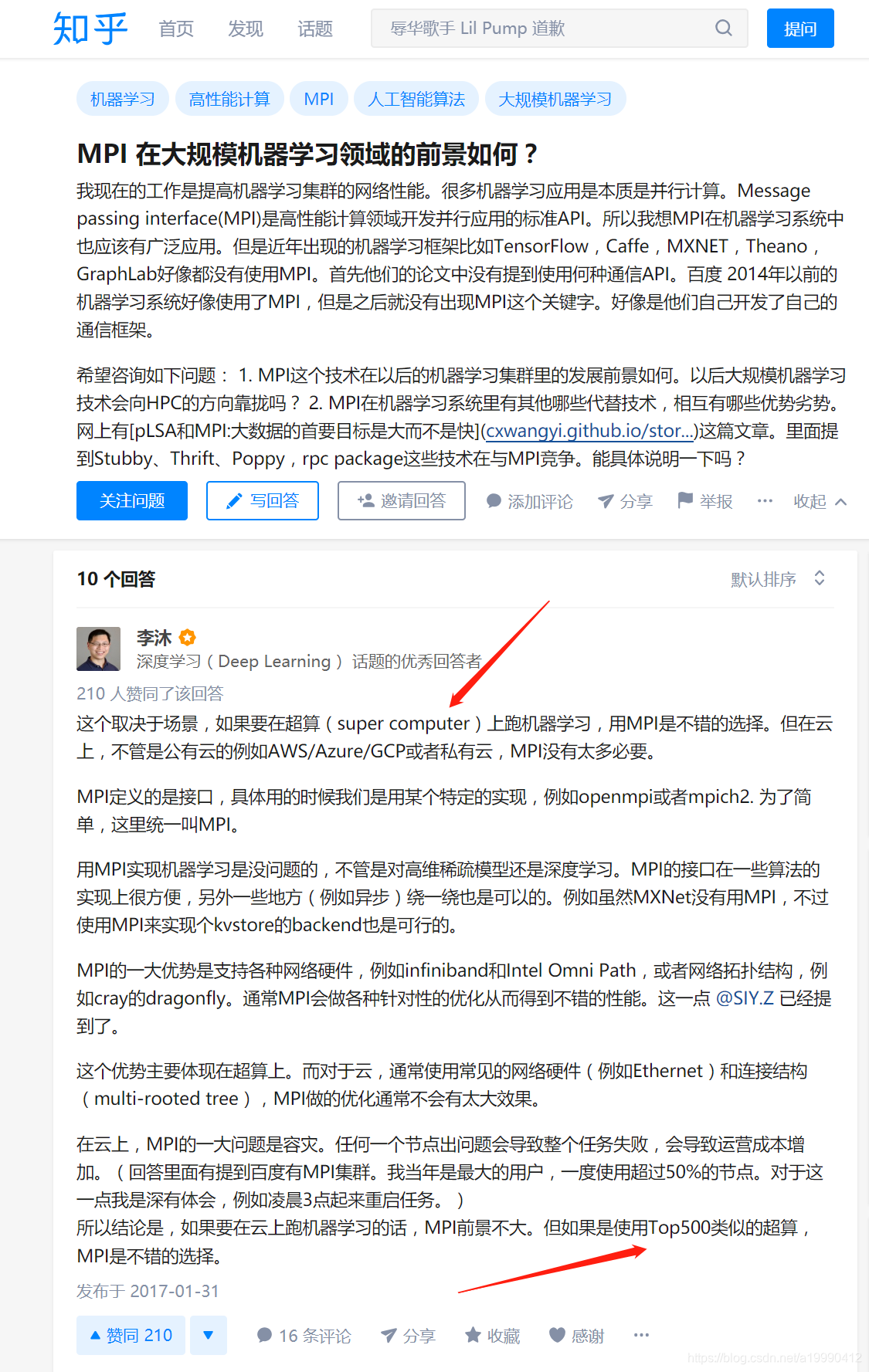
可见下图知乎内容,李沐大神的回答
安装
进入到微软的链接
https://docs.microsoft.com/en-us/message-passing-interface/microsoft-mpi
-
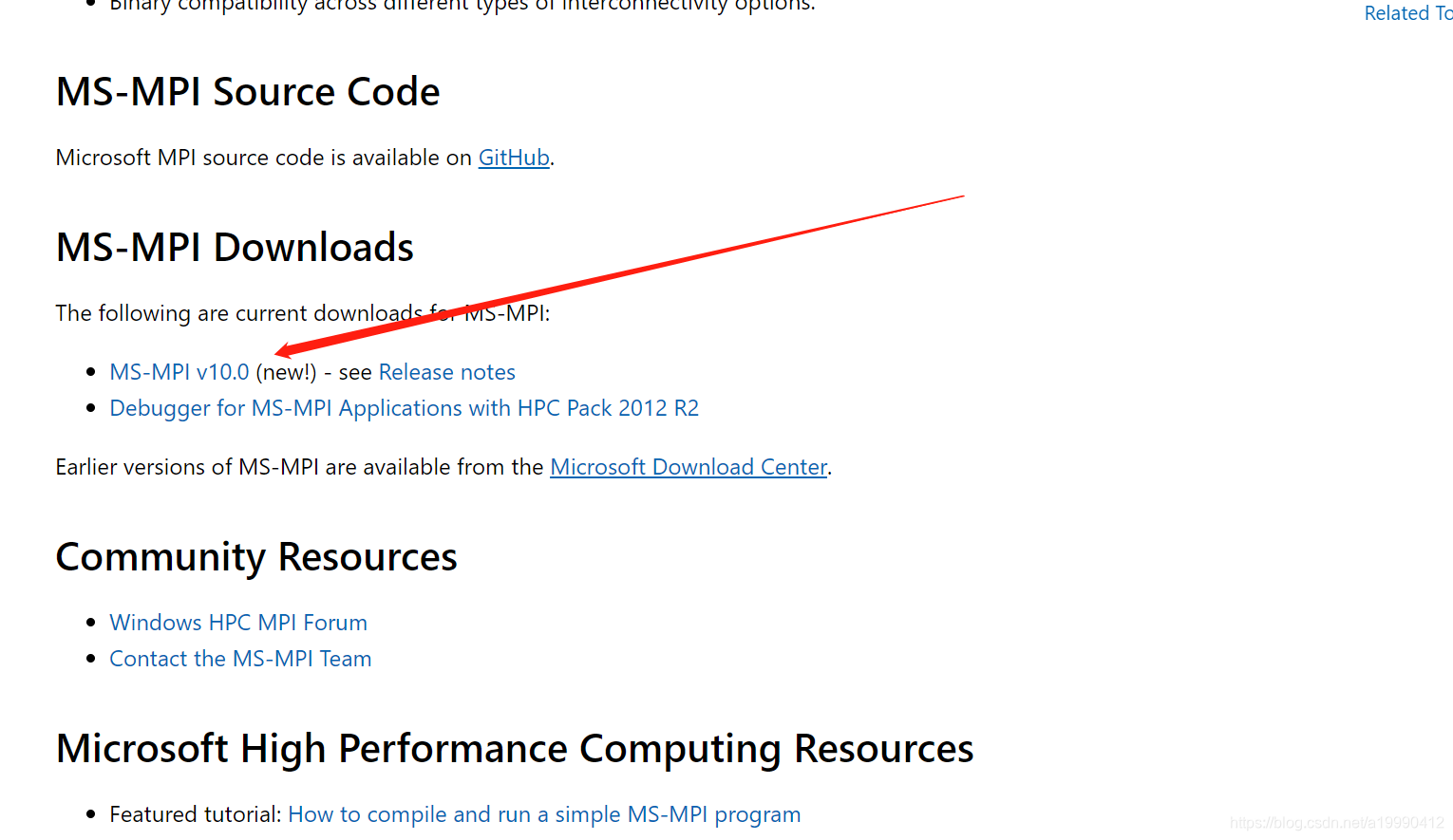
点击下图中位置
-
在点击下图标记位置
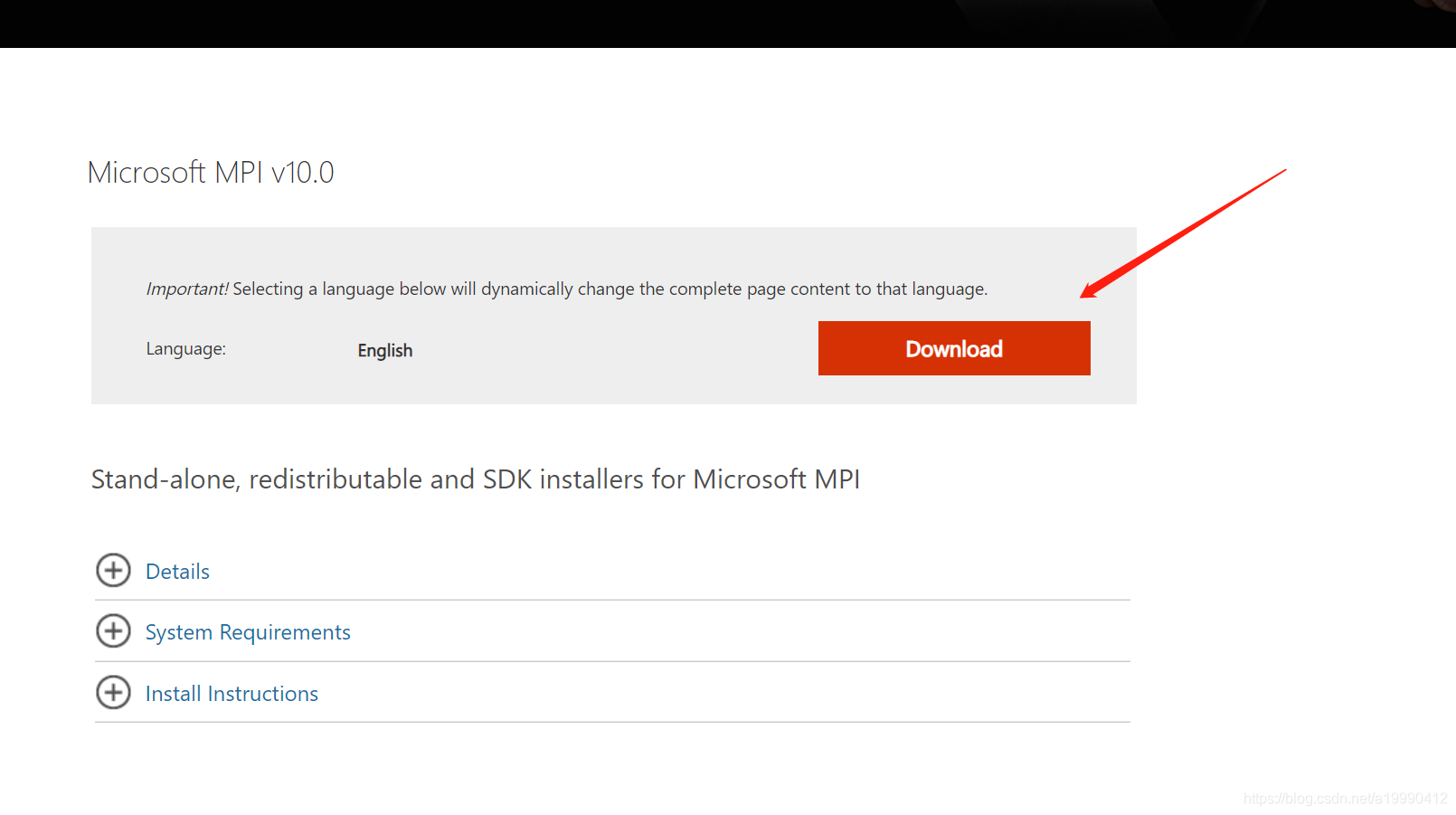
这时就会下载两个文件。点击这个两个文件,然后一路默认就好了(软件非常小,不用担心空间问题)
vs配置
按照下面图的要求配置就好了
- 先设置为debug模式,再设置为X64
- 再给个提示,下面的配置中,每写一页的内容,就点应用一次。保证覆盖掉原来的~
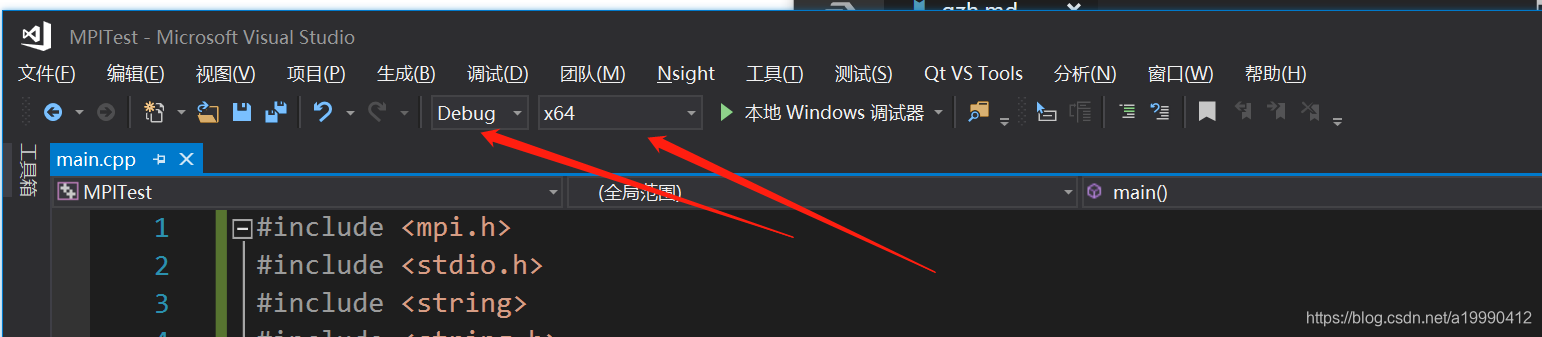
- 这个写对应的地址,如果你是默认的话,应该是跟我一样的,你也可以去检查下是否有对应的文件夹
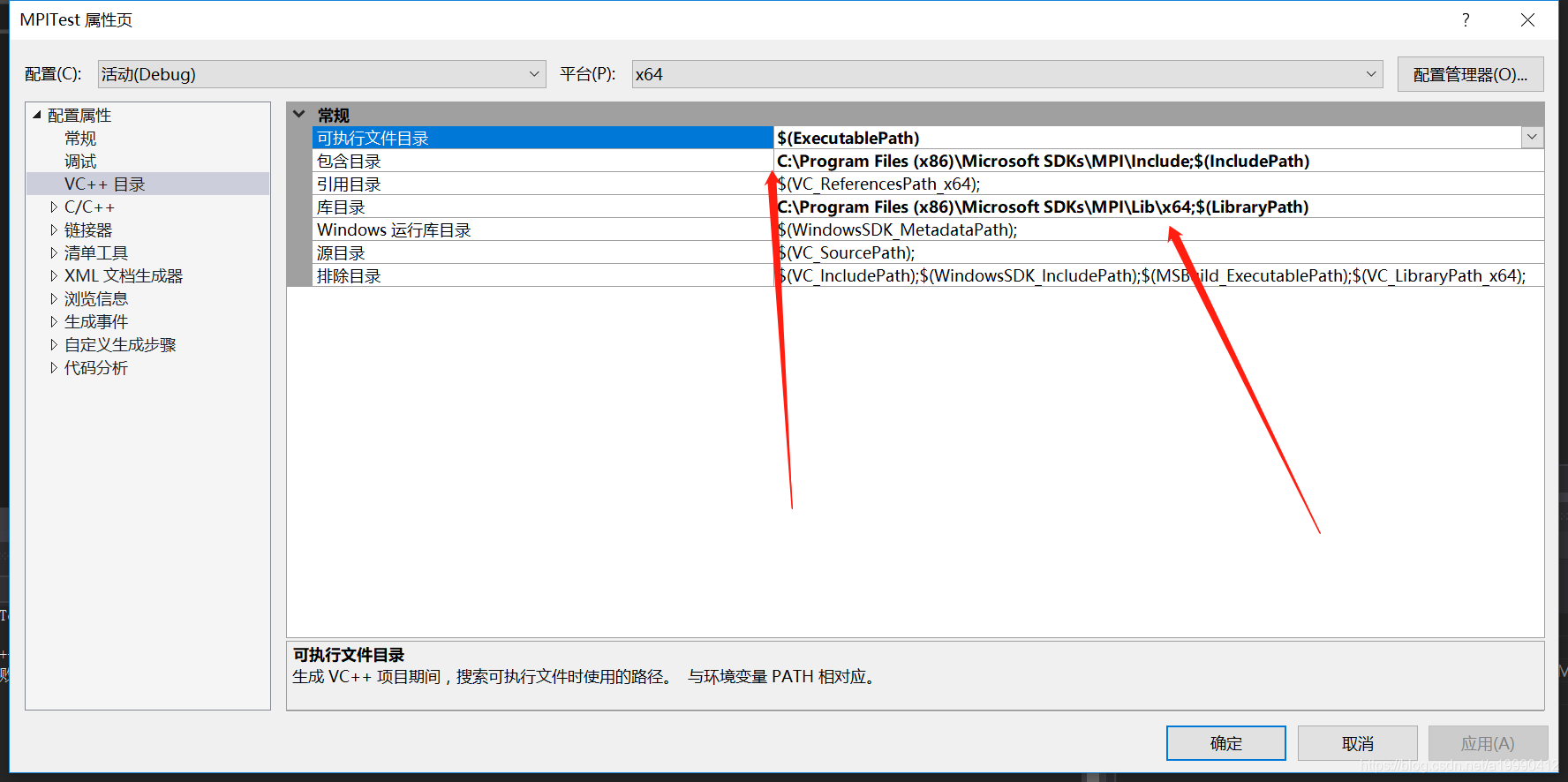
- 再改链接器
这个无论你是否跟我一样的安装目录,都写一样的

测试
测试的话,当然是使用类似于hello world的方式
MPI的逻辑
先简单讲讲MPI的逻辑,MPI的话,会用一个mpiexec程序,去调用我们已经编译好的mpi程序(.app或.exe或.out之类的) 然后,设置节点数目,让同一个程序在不同的节点上跑起来。之后,给每个节点分配一个rank。
所以,在代码上我们就需要交待这个交互的逻辑,在一份代码中实现不同的节点的不同任务。
但是,注意到我们之前说的,是一份程序,让不同节点来操作,唯一可以区分彼此的就是rank不同。因此,在代码中我们需要对rank进行判断,根据不同的rank给出不同的操作的代码空间(一般是用if-else来实现的)
根据我们之前说的,除了导入包之外,这里我们一般必用的有四个函数。
- 根据名字也能猜出对应的作用
- 第一个做初始化的
- 第二个获取所有的节点数
- 第三个获取当前的rank数目
- 第四个做收尾工作的
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Finalize();
实例代码
#include <mpi.h>
#include <stdio.h>
#include <string>
#include <string.h>
#pragma warning(disable : 4996)
const int MAX_STRING = 100;
int main() {
char greeting[MAX_STRING];
int comm_sz;
int my_rank;
MPI_Init(NULL, NULL);
MPI_Comm_size(MPI_COMM_WORLD, &comm_sz);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
if (my_rank != 0) {
sprintf(greeting, "Greetings from process %d of %d\n", my_rank, comm_sz);
MPI_Send(greeting, strlen(greeting) + 1, MPI_CHAR, 0, 0, MPI_COMM_WORLD);
}
else {
printf("Greetings from process %d of %d\n", my_rank, comm_sz);
for (int i = 1; i < comm_sz; ++i) {
MPI_Recv(greeting, MAX_STRING, MPI_CHAR, i, 0, MPI_COMM_WORLD, MPI_STATUSES_IGNORE);
printf(greeting);
}
}
MPI_Finalize();
}
在VS上编译好,之后,找到.exe所在的文件夹
- 用shift+鼠标右键 会看到有命令行打开(或者powershell)
- 输入下面的内容,就会输出下面的节点数。注意,最好是数字不要超过电脑的数目,因为超过了也没用,最多就是电脑的核数来进行计算,剩余的都要来排队。
PS D:\Code\C++\repo\MPITest\x64\Debug>mpiexec -n 4 ./MPITest.exe
Greetings from process 0 of 4
Greetings from process 1 of 4
Greetings from process 2 of 4
Greetings from process 3 of 4
