高可用的设计原理:
- 要做到数据不丢,就必需要持久化
- 要做到服务高可用,就必需要有备用(复本),无论是应用结点还是数据结点
- 要做到复制,就会有数据一致性的问题。
- 我们不可能做到100%的高可用,也就是说,我们能做到几个9个的SLA。
一致性
1)Weak 弱一致性:当你写入一个新值后,读操作在数据副本上可能读出来,也可能读不出来。比如:某些cache系统,网络游戏其它玩家的数据和你没什么关系,VOIP这样的系统,或是百度搜索引擎(呵呵)。
2)Eventually 最终一致性:当你写入一个新值后,有可能读不出来,但在某个时间窗口之后保证最终能读出来。比如:DNS,电子邮件、Amazon S3,Google搜索引擎这样的系统。
3)Strong 强一致性:新的数据一旦写入,在任意副本任意时刻都能读到新值。比如:文件系统,RDBMS,Azure Table都是强一致性的。
方案:
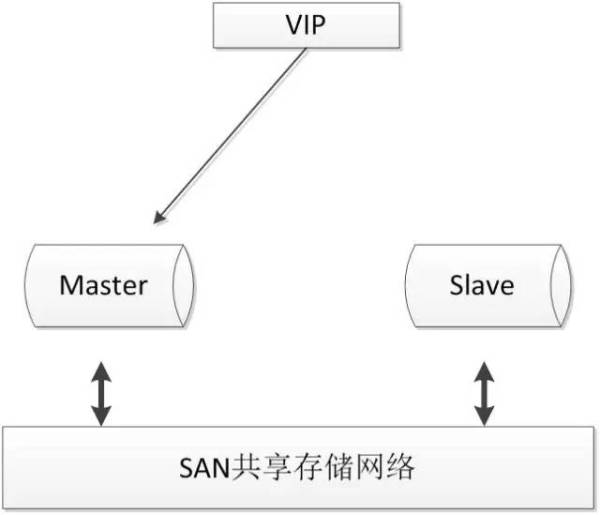
1. MySQL Replication(半同步->异步同步)
- master-slave
- master-slave-slave
-
优点:
- 架构比较简单,使用原生半同步复制作为数据同步的依据;
- 双节点,没有主机宕机后的选主问题,直接切换即可;
- 双节点,需求资源少,部署简单;
缺点:
- 完全依赖于半同步复制,如果半同步复制退化为异步复制,数据一致性无法得到保证;
- 需要额外考虑haproxy、keepalived的高可用机制。
2. Mysql Cluster
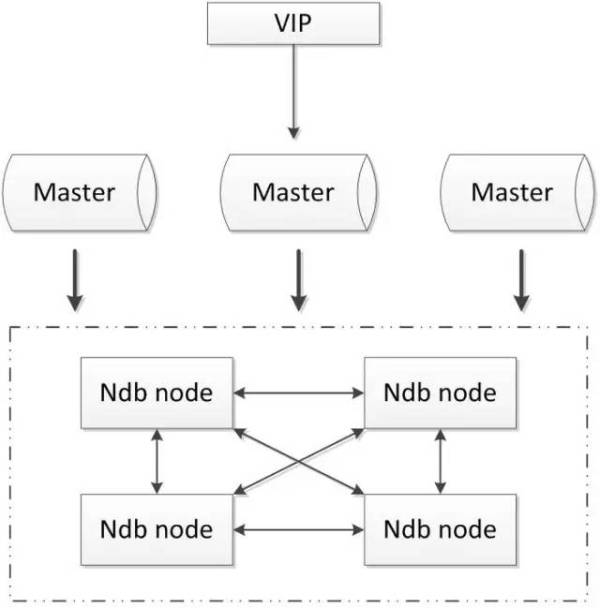
优点:
- 全部使用官方组件,不依赖于第三方软件;
- 可以实现数据的强一致性;
缺点:
- 国内使用的较少;
- 配置较复杂,需要使用NDB储存引擎,与MySQL常规引擎存在一定差异;
- 至少三节点;
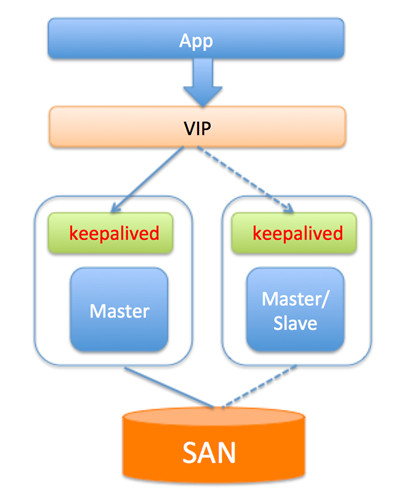
共享存储SAN
优点:
- 两节点即可,部署简单,切换逻辑简单;
- 很好的保证数据的强一致性;
- 不会因为MySQL的逻辑错误发生数据不一致的情况;
缺点:
- 需要考虑共享存储的高可用;
- 价格昂贵;
DRBD
是一个以linux内核模块方式实现的块级别同步复制技术。它通过网卡将主服务器的每个块复制到另外一个服务器块设备上,并在主设备提交块之前记录下来。
