一、dubbo的总体架构如下:
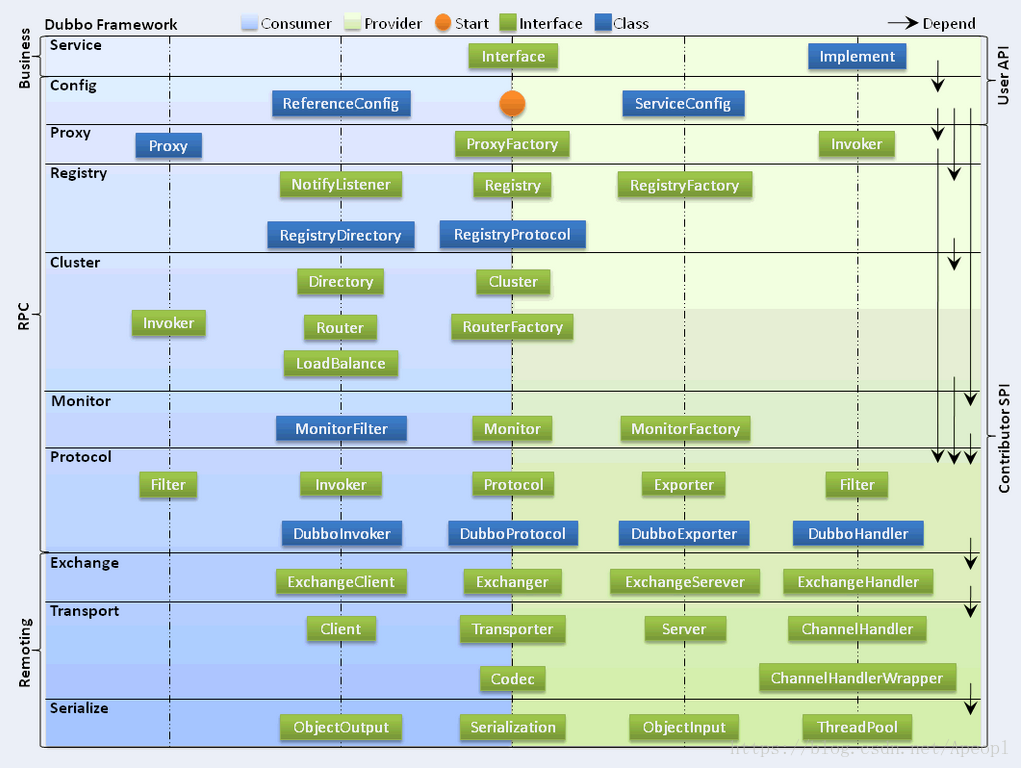
二、dubbo各层次设计说明:
1、服务接口层(Service):该层是与实际业务逻辑相关的,根据服务提供方和服务消费方的业务设计对应的接口和实现。
2、配置层(Config):对外配置接口,以ServiceConfig和ReferenceConfig为中心,可以直接new配置类,也可以通过spring解析配置生成配置类。
3、服务代理层(Proxy):服务接口透明代理,生成服务的客户端Stub和服务器端Skeleton,以ServiceProxy为中心,扩展接口为ProxyFactory。
4、服务注册层(Registry):封装服务地址的注册与发现,以服务URL为中心,扩展接口为RegistryFactory、Registry和RegistryService。可能没有服务注册中心,此时服务提供方直接暴露服务。
5、集群层(Cluster):封装多个提供者的路由及负载均衡,并桥接注册中心,以Invoker为中心,扩展接口为Cluster、Directory、Router和LoadBalance。将多个服务提供方组合为一个服务提供方,实现对服务消费方来透明,只需要与一个服务提供方进行交互。
6、监控层(Monitor):RPC调用次数和调用时间监控,以Statistics为中心,扩展接口为MonitorFactory、Monitor和MonitorService。
7、远程调用层(Protocol):封将RPC调用,以Invocation和Result为中心,扩展接口为Protocol、Invoker和Exporter。Protocol是服务域,它是Invoker暴露和引用的主功能入口,它负责Invoker的生命周期管理。Invoker是实体域,它是Dubbo的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起invoke调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
8、信息交换层(Exchange):封装请求响应模式,同步转异步,以Request和Response为中心,扩展接口为Exchanger、ExchangeChannel、ExchangeClient和ExchangeServer。
9、网络传输层(Transport):抽象mina和netty为统一接口,以Message为中心,扩展接口为Channel、Transporter、Client、Server和Codec。
10、数据序列化层(Serialize):可复用的一些工具,扩展接口为Serialization、 ObjectInput、ObjectOutput和ThreadPool。

三、dubbo的工作流程:
1、client发起一个线程调用远程接口,生成一个唯一的ID(比如一段随机字符串,UUID等),Dubbo是使用AtomicLong从0开始累计数字的
2、将打包的方法调用信息(如调用的接口名称,方法名称,参数值列表等),和处理结果的回调对象callback,全部封装在一起,组成一个对象object
3、向专门存放调用信息的全局ConcurrentHashMap里面put(ID, object)
4、将ID和打包的方法调用信息封装成一对象connRequest,使用IoSession.write(connRequest)异步发送出去
5、当前线程再使用callback的get()方法试图获取远程返回的结果,在get()内部,则使用synchronized获取回调对象callback的锁, 再先检测是否已经获取到结果,如果没有,然后调用callback的wait()方法,释放callback上的锁,让当前线程处于等待状态。
6、服务端接收到请求并处理后,将结果(此结果中包含了前面的ID,即回传)发送给客户端,客户端socket连接上专门监听消息的线程收到消息,分析结果,取到ID,再从前面的ConcurrentHashMap里面get(ID),从而找到callback,将方法调用结果设置到callback对象里。
7、监听线程接着使用synchronized获取回调对象callback的锁(因为前面调用过wait(),那个线程已释放callback的锁了),再notifyAll(),唤醒前面处于等待状态的线程继续执行(callback的get()方法继续执行就能拿到调用结果了),至此,整个过程结束。