1打开有道词典-有道翻译-右键审查元素-Network-Headers-找到General下面的URL,写入代码

import urllib.request
import urllib.parse
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data={}
data['i']='我气'
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['salt']='1538989442643'
data['sign']='40954ebe6d906735813c2cd7c2274733'
data['doctype']='json'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['action']='FY_BY_CLICKBUTTION'
data['typoResult']='false'
#利用urlencode把它编码成url的形式
data=urllib.parse.urlencode(data).encode('utf-8')
response=urllib.request.urlopen(url,data)
html=response.read().decode('utf-8')
print(html)
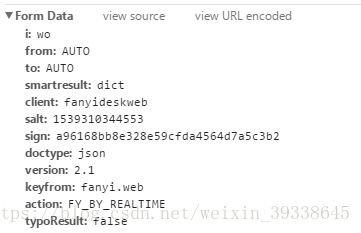
然后再往下拉,找到Form Data写入代码里面的data数组
运行如果出现如下情况:

只需要去掉url地址里面的_o即可
正确结果如下:

为了用户看起来更加友好,还需进行改进:
通过下图分析:

import urllib.request
import urllib.parse
import json
contend=input('请输入 需要翻译的内容:')
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
data={}
data['i']=contend
data['from']='AUTO'
data['to']='AUTO'
data['smartresult']='dict'
data['client']='fanyideskweb'
data['salt']='1538989442643'
data['sign']='40954ebe6d906735813c2cd7c2274733'
data['doctype']='json'
data['version']='2.1'
data['keyfrom']='fanyi.web'
data['action']='FY_BY_CLICKBUTTION'
data['typoResult']='false'
#利用urlencode把它编码成url的形式
data=urllib.parse.urlencode(data).encode('utf-8')
response=urllib.request.urlopen(url,data)
html=response.read().decode('utf-8')
target=json.loads(html)
print('翻译结果:%s'%(target['translateResult'][0][0]['tgt']))
运行结果是:

到此,有道爬虫就结束了!