决策树系列(四)——C4.5
如上一篇文章所述,ID3方法主要有几个缺点:一是采用信息增益进行数据分裂,准确性不如信息增益率;二是不能对连续数据进行处理,只能通过连续数据离散化进行处理;三是没有采用剪枝的策略,决策树的结构可能会过于复杂,可能会出现过拟合的情况。
C4.5在ID3的基础上对上述三个方面进行了相应的改进:
a) C4.5对节点进行分裂时采用信息增益率作为分裂的依据;
b) 能够对连续数据进行处理;
c) C4.5采用剪枝的策略,对完全生长的决策树进行剪枝处理,一定程度上降低过拟合的影响。
1.采用信息增益率作为分裂的依据
信息增益率的计算公式为:
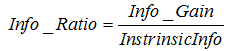
其中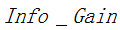 表示信息增益,
表示信息增益,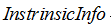 表示分裂子节点数据量的信息增益,计算公式为:
表示分裂子节点数据量的信息增益,计算公式为:
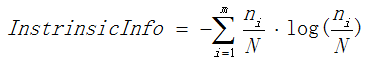
其中m表示节点的数量,Ni表示第i个节点的数据量,N表示父亲节点的数据量,说白了,其实是分裂节点的熵。
信息增益率越大,说明分裂的效果越好。
以一个实际的例子说明C4.5如何通过信息增益率选择分裂的属性:
表1 原始数据表
| 当天天气 |
温度 |
湿度 |
日期 |
逛街 |
| 晴 |
25 |
50 |
工作日 |
否 |
| 晴 |
21 |
48 |
工作日 |
是 |
| 晴 |
18 |
70 |
周末 |
是 |
| 晴 |
28 |
41 |
周末 |
是 |
| 阴 |
8 |
65 |
工作日 |
是 |
| 阴 |
18 |
43 |
工作日 |
否 |
| 阴 |
24 |
56 |
周末 |
是 |
| 阴 |
18 |
76 |
周末 |
否 |
| 雨 |
31 |
61 |
周末 |
否 |
| 雨 |
6 |
43 |
周末 |
是 |
| 雨 |
15 |
55 |
工作日 |
否 |
| 雨 |
4 |
58 |
工作日 |
否 |
以当天天气为例:
一共有三个属性值,晴、阴、雨,一共分裂成三个子节点。
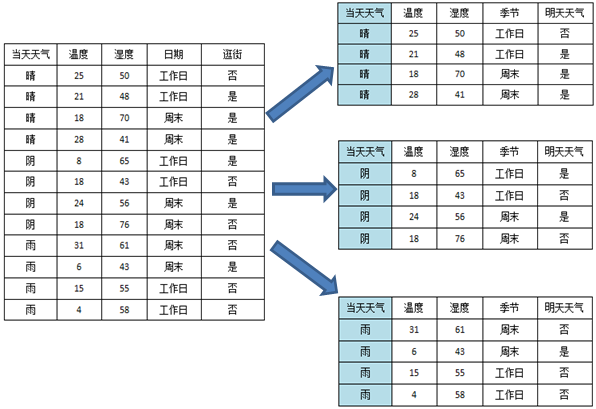
根据上述公式,可以计算信息增益率如下:
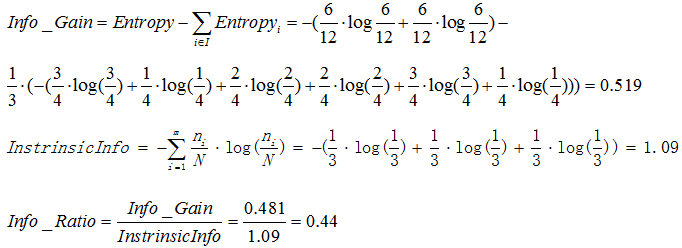
所以使用天气属性进行分裂可以得到信息增益率0.44。
2.对连续型属性进行处理
C4.5处理离散型属性的方式与ID3一致,新增对连续型属性的处理。处理方式是先根据连续型属性进行排序,然后采用一刀切的方式将数据砍成两半。
那么如何选择切割点呢?很简单,直接计算每一个切割点切割后的信息增益,然后选择使分裂效果最优的切割点。以温度为例:

从上图可以看出,理论上来讲,N条数据就有N-1个切割点,为了选取最优的切割垫,要计算按每一次切割的信息增益,计算量是比较大的,那么有没有简化的方法呢?有,注意到,其实有些切割点是很明显可以排除的。比如说上图右侧的第2条和第3条记录,两者的类标签(逛街)都是“是”,如果从这里切割的话,就将两个本来相同的类分开了,肯定不会比将他们归为一类的切分方法好,因此,可以通过去除前后两个类标签相同的切割点以简化计算的复杂度,如下图所示:
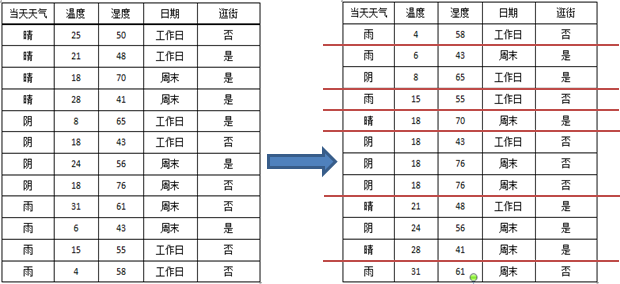
从图中可以看出,最终切割点的数目从原来的11个减少到现在的6个,降低了计算的复杂度。
确定了分割点之后,接下来就是选择最优的分割点了,注意,对连续型属性是采用信息增益进行内部择优的,因为如果使用信息增益率进行分裂会出现倾向于选择分割前后两个节点数据量相差最大的分割点,为了避免这种情况,选择信息增益选择分割点。选择了最优的分割点之后,再计算信息增益率跟其他的属性进行比较,确定最优的分裂属性。
3. 剪枝
决策树只已经提到,剪枝是在完全生长的决策树的基础上,对生长后分类效果不佳的子树进行修剪,减小决策树的复杂度,降低过拟合的影响。
C4.5采用悲观剪枝方法(PEP)。悲观剪枝认为如果决策树的精度在剪枝前后没有影响的话,则进行剪枝。怎样才算是没有影响?如果剪枝后的误差小于剪枝前经度的上限,则说明剪枝后的效果与更佳,此时需要子树进行剪枝操作。
进行剪枝必须满足的条件:

其中:
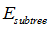 表示子树的误差;
表示子树的误差;
 表示叶子节点的误差;
表示叶子节点的误差;
令子树误差的经度满足二项分布,根据二项分布的性质, ,
,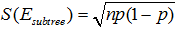 ,其中
,其中 ,N为子树的数据量;同样,叶子节点的误差
,N为子树的数据量;同样,叶子节点的误差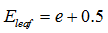 。
。
上述公式中,0.5表示修正因子。由于对父节点进行分裂总会得到比父节点分类结果更好的效果,因此,因此从理论上来说,父节点的误差总是不小于孩子节点的误差,因此需要进行修正,给每一个节点都加上0.5的修正因此,在计算误差的时候,子节点由于加上了修正的因子,就无法保证总误差总是低于父节点。
算例:


由于 ,所以应该进行剪枝。
,所以应该进行剪枝。
程序设计及源代码(C#版)
程序的设计过程
(1)数据格式
对原始的数据进行数字化处理,并以二维数据的形式存储,每一行表示一条记录,前n-1列表示属性,最后一列表示分类的标签。
如表1的数据可以转化为表2:
表2 初始化后的数据
| 当天天气 |
温度 |
湿度 |
季节 |
明天天气 |
| 1 |
25 |
50 |
1 |
1 |
| 2 |
21 |
48 |
1 |
2 |
| 2 |
18 |
70 |
1 |
3 |
| 1 |
28 |
41 |
2 |
1 |
| 3 |
8 |
65 |
3 |
2 |
| 1 |
18 |
43 |
2 |
1 |
| 2 |
24 |
56 |
4 |
1 |
| 3 |
18 |
76 |
4 |
2 |
| 3 |
31 |
61 |
2 |
1 |
| 2 |
6 |
43 |
3 |
3 |
| 1 |
15 |
55 |
4 |
2 |
| 3 |
4 |
58 |
3 |
3 |
其中,对于“当天天气”属性,数字{1,2,3}分别表示{晴,阴,雨};对于“季节”属性{1,2,3,4}分别表示{春天、夏天、冬天、秋天};对于类标签“明天天气”,数字{1,2,3}分别表示{晴、阴、雨}。
代码如下所示:
static double[][] allData; //存储进行训练的数据
static List<String>[] featureValues; //离散属性对应的离散值
featureValues是链表数组,数组的长度为属性的个数,数组的每个元素为该属性的离散值链表。
(2)两个类:节点类和分裂信息
a)节点类Node
该类表示一个节点,属性包括节点选择的分裂属性、节点的输出类、孩子节点、深度等。注意,与ID3中相比,新增了两个属性:leafWrong和leafNode_Count分别表示叶子节点的总分类误差和叶子节点的个数,主要是为了方便剪枝。
 View Code(源码参见原微博下同)
View Code(源码参见原微博下同)
b)分裂信息类,该类存储节点进行分裂的信息,包括各个子节点的行坐标、子节点各个类的数目、该节点分裂的属性、属性的类型等。
View Code
主方法findBestSplit(Node node,List<int> nums,int[] isUsed),该方法对节点进行分裂
其中:
node表示即将进行分裂的节点;
nums表示节点数据的行坐标列表;
isUsed表示到该节点位置所有属性的使用情况;
findBestSplit的这个方法主要有以下几个组成部分:
1)节点分裂停止的判定
节点分裂条件如上文所述,源代码如下:
View Code
2)寻找最优的分裂属性
寻找最优的分裂属性需要计算每一个分裂属性分裂后的信息增益率,计算公式上文已给出,其中熵的计算代码如下:
View Code
3)进行分裂,同时对子节点进行迭代处理
其实就是递归的工程,对每一个子节点执行findBestSplit方法进行分裂。
findBestSplit源代码:
View Code
(4)剪枝
悲观剪枝方法(PEP):
View Code
C4.5核心算法的所有源代码:
View Code
总结:
要记住,C4.5是分类树最终要的算法,算法的思想其实很简单,但是分类的准确性高。可以说C4.5是ID3的升级版和强化版,解决了ID3未能解决的问题。要重点记住以下几个方面:
1.C4.5是采用信息增益率选择分裂的属性,解决了ID3选择属性时的偏向性问题;
2.C4.5能够对连续数据进行处理,采用一刀切的方式将连续型的数据切成两份,在选择切割点的时候使用信息增益作为择优的条件;
3.C4.5采用悲观剪枝的策略,一定程度上降低了过拟合的影响。