SQL SERVER 锁机制浅读
内容为本人根据当前正在读的《SQL Server性能调优实战》(陈畅亮 吴一晴 著 机械工业出版社)和前辈分享的PPT,通读后的总结与汇总。
序
- 锁及事务机制的存在,便于关系型数据库实现它的四个基本特性。
- 当两个不同的进程试图同时修改同一份数据时,数据库管理系统(DBMS)负责解决他们之间潜在的冲突。
- 理论上所有的事务之间应该是完全隔离的。但是实际上,要实现完全隔离成本实在是太高(必须是序列化的隔离等级才能完全隔离)。所以,SQLServer通过锁,就像十字路口的红绿灯一样,告诉所有并发的链接,在同一时刻上,哪些资源可以读取,哪些资源可以修改。当一个事务需要访问的资源加了其所不兼容的锁,SQLServer会阻塞当前事务来达成所谓的隔离性,直到其所请求资源上的锁被释放。
- SQL Server在隔离和并发之间选择了Read Commited作为数据库的默认隔离级别。
ACID
- 原子性(Atomicity):既不可再分,一个事务,要么全部成功,要么全部失败。一个语句,要么执行,要么不执行。
- 一致性(Consistency):事务执行前后,不论成败,数据库的完整性约束没有被破坏。(唯一约束,外键约束,check约束和触发器设置等)。这一点是由SQLServer进行保证的。
- 隔离性(Isolation):事务是互不干扰的,一个事务不可能看到其它事务运行时,中间某一时刻的数据。
- 持久性(Durability):事务结束前(大部分书称之为‘成功后’),对数据的所有改动都已经从内存转为外部存储器(物理存储器)上。其实应该说是对数据的改动后的结果是可持久的。这样子系统任何时候瘫痪,已提交事务所进行的更新不会丢失。
锁、事务要解决的问题
- 脏读:在某个会话中,读取了还未提交的事务中修改或更新的数据。
- 不可重复读:在同一事务中,前后两次读取相同的数据,结果却不一样。
- 幻读:当某个事务查找或更新某个范围内的数据时,另一个事务在这个范围内插入了某条数据,会导致当前事务没有将这条新增的数据返回或更新。
- 重复读:当某个查询以索引扫描的方式读取数据时,另一个事务更新了索引数据,并导致数据向后转移了位置。此时会把已经读取过但被挪动了位置的数据重新读取出来。
- 丢失更新:事务T1读取了数据,并执行了一些操作,然后更新数据。事务T2也做了相同的事,则T1和T2更新数据数据时可能会覆盖对方的更新,从而引起错误。
并发控制的主要方法是通过锁,在一段时间内禁止用户做某些操作以避免产生数据不一致。
丢失更新例子:A、B两个用户读同一数据并进行修改,其中一个用户的修改结果破坏了另一个修改的结果,比如订票系统。
PS:这个‘丢失更新’问题,是我在前辈分享的ppt中看到的,但在我正在读的《SQL Server性能调优实战》(陈畅亮 吴一晴 著 机械工业出版社)中未找到这一条,暂时不是很懂。
猜测一下,所谓的更新覆盖,应该是类似并发时,A用户执行操作导致剩余数量为3,B用户执行操作导致剩余数量为2,然而结果剩余数量为3的把剩余数量为2的更新覆盖了,就会导致数据出错。
我这边开发这种情况时,根据前辈的建议,一直都是尽量在SQL中执行加减操作,而非程序中加减后,将剩余数量入库。所以就避免了丢失更新问题。
隔离级别
- Read Uncommitted[ˌʌnkəˈmɪtɪd]:此隔离级别会有脏读、不可重复读和幻读的情况发生,但并发性能最佳,因为它不会为读操作添加共享锁。
- Read Committed[kəˈmɪtɪd]:此隔离级别会有不可重复读、幻读和重复读的情况发生,它的并发性比Read Uncommitted差,是SQL Server默认的隔离级别。
- Repeatable[rɪˈpi:təbl]:此隔离级别会有幻读情况,它与Read Committed的区别在于,共享锁持有的时间会比较长,需要等待到事务提交或回滚后才释放共享锁。由于共享锁持有的时间长了,阻塞相对也会多一些,特别是对于更新操作会有较多的阻塞。
- Serializable[sɪərɪrlaɪ’zəbl]:此隔离级别不会有以上提到的四种问题出现,但其代价是最高的。该隔离级别锁引入了**Range Lock(区间锁)**的概念。区间锁是指在进行查询、更新、删除、插入操作时,对更新数据中某个去与内的数据加锁。因此其并发非常有限。
- Snapshot[ˈsnæpʃɑ:t]:上面四个隔离级别是以“悲观锁”的方式实现的,而Snapshot是以“乐观锁”的方式实现的。数据库会在Tempdb中创建与之相应的副本,从而避免脏读和不可重复读的问题。
从上面可以了解:
要解决不可重复读和重复读问题,需要将隔离级别升到Repeatable,这个级别的事务会保持共享锁,直到事务回滚或提交。
要解决幻读问题,则需要将隔离级别提升到Serializable,这个隔离级别为事务中更新的数据添加区间锁。
PS:在我当前开发的电商项目中,我们的所有查询SQL都要添加WITH(NOLOCK)来查询,应该是为了提高并发性能,允许其进行脏读。手动将默认隔离级别降级为Read Uncommitted。
锁模式
- 共享锁(S锁):发生在数据查找之前。用于读取资源所加的锁,允许多个事务对同一对象使用相同的共享锁,拥有共享锁的资源不能被修改。共享锁默认情况下是读取了资源马上释放。不会等到事务提交或回滚。
- 排他锁(X锁):发生在数据更新之前。用于数据修改,排他锁是一个独占锁,和其他任何锁都不兼容,包括其它排他锁。当资源加了排他锁,其它请求读取或修改这个资源的的事务都会被阻塞。
- 更新锁(U锁):发生在更新语句中。用于更新数据,当查找的数据不是被更新对象时,与S锁一样处理。若确认是被更新的对象,则将U锁转换为X锁。SQL Server通过U锁来避免死锁问题。因为S锁和S锁是兼容的,U锁和S锁兼容的,来使得更新查找时不影响数据查找,而U锁和U锁之间并不兼容从而减少了死锁的可能性。
- 意向锁(IS IX IU SIX SIU UIX):发生在较低粒度级别的资源获取锁之前,表示将对该资源下低粒度的资源添加对应的锁。意向共享锁(IS锁)、意向排他锁(IX锁)、意向更新锁(IU锁)、共享意向排他锁(SIX锁)、共享意向更新锁(SIU锁)、更新意向排他锁(UIX锁)。
- 快照(SNOPSHOT):通过在tempDB中创建一个额外的副本来避免脏读、不可重复度,会给tempDB造成负担。
- 键范围锁(KEY-RANGE):在使用可序列化事务隔离级别时,对于Transact-SQL语句读取的记录集,键范围锁可以隐式保护该记录集中包含的行范围。可序列化隔离级别要求每当在事务期间执行任一查询时,该查询都必须获取相同的行集。键范围锁可防止其他事务插入其键值位于可序列化事务读取的键值范围内的新行,从而确保满足此要求。
键范围锁可防止幻读。通过保护行之间的键范围,它还可以防止对事务访问的记录集进行幻插入。
键范围锁放置在索引上,指定开始键值和结束键值。此锁将阻止任何要插入、更新或删除任何带有该范围内的键值的行的尝试,因为这些操作会首 先获取索引上的锁。例如,可序列化事务可能发出了一个 SELECT 语句,以读取其键值介于 ‘AAA’ 与 ‘CZZ’ 之间的所有行。从 ‘AAA’ 到 ‘CZZ’ 范围内的键值上的键范围锁可阻止其他事务插入带有该范围内的键值(例如 ‘ADG’、‘BBD’ 或 ‘CAL’)的行。 - 架构锁:SQL Server使用架构锁来保持表结构的完整性。不像其他提供数据隔离的锁类型,架构锁提供事务中对数据库对象如表、视图、索引的schema隔离。
- 大容量更新锁:在向表进行大容量数据复制且指定了 TABLOCK 提示时使用。
PS:意向锁更像是一个指示器。因为资源是有层次的,锁也是有层级结构的。行、页、表。简单来说,当一个粒度比较低的资源被锁定时,会在其父资源加上意向锁,告诉其它查询这个资源的某一部分已经上锁,不必一行行去找是否有被锁定的低粒度资源。
PS:快照(SNOPSHOT)这个我看到有归类到隔离级别上,有归类到锁模式上,至于它是否因为本质上特殊,可以达到两种效果而导致大家对其分界认知有所模糊。我尚未用过,尚不明确,留待后续学习。
PS:快照及后面三个锁模式键范围锁、架构锁、大容量更新锁,在《SQL Server性能调优实战》书中未标明这四种锁模式,又感觉与锁粒度颇有关系的样子。尚不明确,留待后续学习。
锁粒度
- 行锁:是SQL Server数据级别中粒度最小的锁级别,行锁可针对数据中的某一行添加一个对应类型的锁。行锁根据表是否存在狙击索引粉为键值锁和行标识锁(RID)。
- 页锁:针对某个数据页添加的锁。在T-SQL语句中,如果查询使用了页锁,则不会再使用相同类型的行锁,如果使用了行锁,也不会再使用相同类型的页锁。对数据页加锁后,将无法再对数据页使用与之不兼容的锁。
- 表锁:在整个表中添加锁。若表被锁了,其中的数据页及数据行都无法加上预制不兼容的锁。
所谓所粒度,从本质上说就是,为了给事务提供完全的隔离和序列化,作为查询或更新的一部分被锁定的数据的总量(的大小)。Lock Manager需要在资源的并发访问与维护大量低级别锁的管理开销之间取得平衡。比如,锁的粒度越小,能够同时访问同一张表的并发用户的数量就越大,不过维护这些锁的管理开销也越大。锁的粒度越大,管理锁需要的开销就越少,而并发性也降低了。下图说明了锁的大小与并发性之间的权衡取舍。
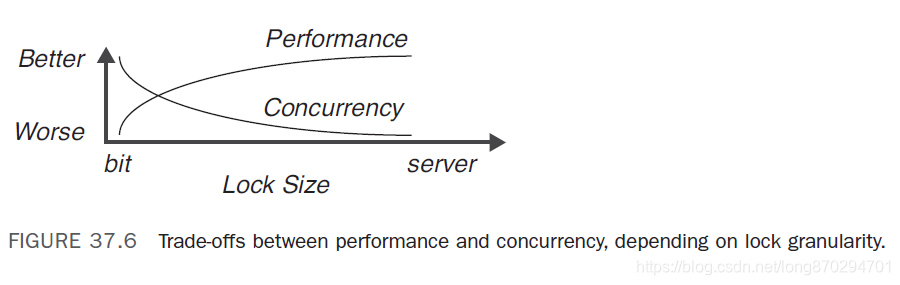
锁升级
锁升级是将许多较细粒度的锁转换成数量更少的较粗粒度的锁的过程,这样可以减少系统开销,但却增加了并发争用的可能性。
当 SQL Server 数据库引擎获取低级别的锁时,它还将在包含更低级别对象的对象上放置意向锁:
1、当锁定行或索引键范围时,数据库引擎将在包含这些行或键的页上放置意向锁。
2、当锁定页时,数据库引擎将在包含这些页的更高级别的对象上放置意向锁。除了对象上的意向锁以外,以下对象上还需要意向页锁:
非聚集索引的叶级页
聚集索引的数据页
堆数据页
锁升级的阈值:
单个 Transact-SQL 语句在单个无分区表或索引上获得至少 5,000 个锁。
单个 Transact-SQL 语句在已分区表的单个分区上获得至少 5,000 个锁,并且 ALTER TABLE SET LOCK_ESCALATION 选项设为 AUTO。
数据库引擎实例中的锁的数量超出了内存或配置阈值或持有锁的时间过长时,会可能引发锁升级。
TIPS:数据库引擎不会将行锁或键范围锁升级到页锁,而是将它们直接升级到表锁。同样,页锁始终升级到表锁。
简单的思维导图
createtime:2018-11-14