最近呆在家里闲着没事干,学习了几天pyhton爬虫,有了一个初步的了解,便打算模拟登录一下正方教务系统获取一下成绩信息,方便以后可以快速地查成绩,心疼几秒教务系统/滑稽。首先要获取教务系统的网址,在浏览器访问网址:http://210.38.137.126:8016/,观察登录界面:
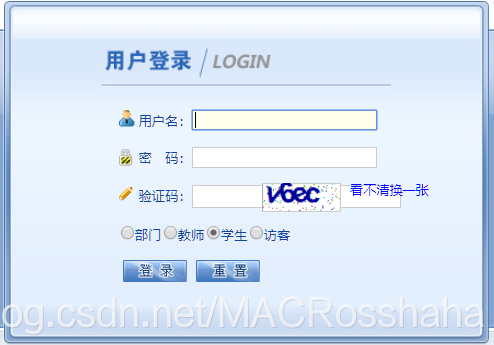
验证码识别:
登录需要用户名、密码和验证码,首先要解决的是验证码的问题,识别验证码的方法无非两种,人工识别和第三方自动识别,为了方便以后的操作,我选择了一个叫云打码的第三方平台,有需要的可以百度搜索注册一个,价格挺便宜的,具体使用方法平台有详细的说明,在这里就不多复述了,嫌麻烦的可以先采用第一种方法,无论哪种方法,都是要先将验证码下载到本地,这一步还是相对简单,方法为:对网址发起一个GET请求,找到验证码对应的src地址,保存到本地:

url = "http://210.38.137.126:8016/"
page_text = requests.get(url =url,headers=headers).text
tree = etree.HTML(page_text)
code_img_src = 'http://210.38.137.126:8016/' + tree.xpath('//*[@id="icode"]/@src')[0]
img_data = requests.get(url =code_img_src,headers=headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
模拟登录教务系统:
首先还是打开浏览器的抓包工具,勾选上Preserve log(保存中间过程)
在浏览器模拟登录过程,使用抓包工具追踪浏览器的行为:

找到了POST请求,往下拉查看提交的数据信息:
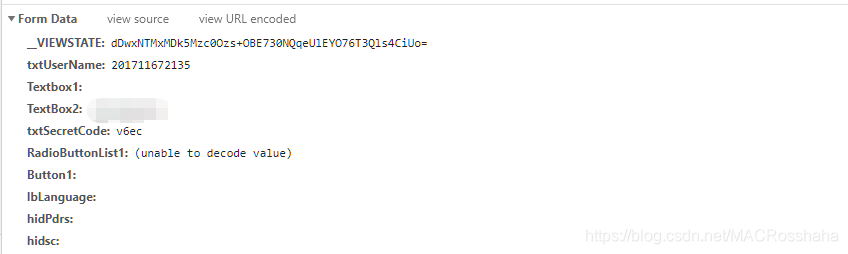
第一项__VIEWSTATE这是asp.net框架特有的一个东西,详细用法自行百度,这里一定要加入,其他信息包括学号、密码、验证码,基本符合登录所系要求,接下来我们使用requests模块发起一个POST请求,代码如下:
login_url = 'http://210.38.137.126:8016/default2.aspx'
data = {
'__VIEWSTATE': 'dDwxNTMxMDk5Mzc0Ozs+OBE730NQqeUlEYO76T3Qls4CiUo=',
'txtUserName': '201711672135',
'Textbox1':'',
'TextBox2': '*******',
'txtSecretCode': code_text,
'RadioButtonList1': '(unable to decode value)',
'Button1': '',
'lbLanguage': '',
'hidPdrs':'',
'hidsc':'',
}
response = requests.post(url=login_url,headers=headers,data=data)
print(response.status_code)
login_page_text = response.text
with open('login.html','w',encoding='utf-8') as fp:
fp.write(login_page_text)
cookie处理:
这里保存一下html文件,方便后面检验,打开html文件,发现页面不对,提示验证码错误。返回登录界面,观察发现每次获取验证码后cookie也会发生相应的变化,因此我们需要对cookie值做相应的操作。这里简单介绍一下cookie,http/https协议特性为无状态,而cookie是用来让服务器端记录客户端的相关状态,模拟登录post请求后,由服务器端创建。处理cookie分为两种,一种是手动处理,通过抓包工具获取cookie值,将该值封装到headers中,一般用于cookie非动态变化的情况。另一种是自动处理,这里我们用到的是session会话对象,当请求过程中产生了cookie,则该cookie会被自动存储/携带在该session对象中。
创建一个session对象:
session = requests.Session()
重新运行代码,发现登录成功,进入教务系统页面。(PS:注意一定要先创建cookie,再获取验证码进行提交,不然相当于你填完了验证码又刷新了一下,验证码就变掉了,这样会提示你验证码错误的。)
查询成绩:
还是打开浏览器的抓包工具,勾选上Preserve log(保存中间过程),使用抓包工具追踪浏览器的行为:
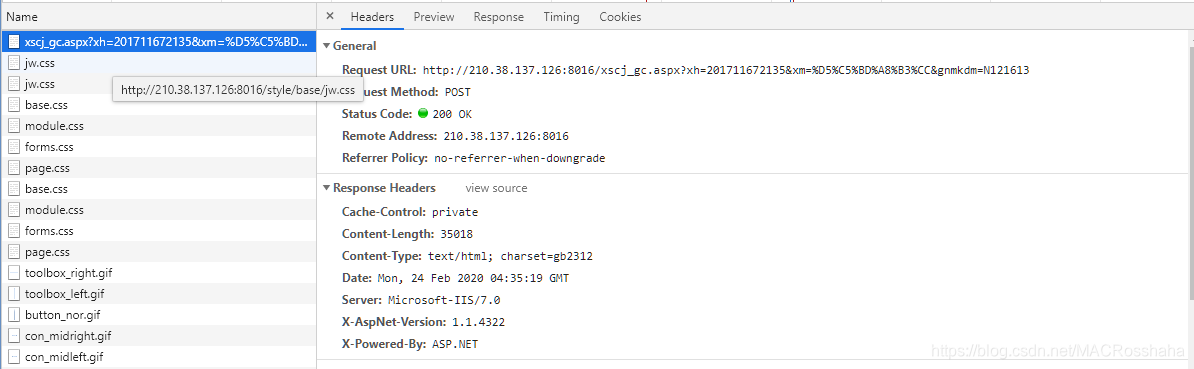
这里找到了浏览器提交的POST请求,分析一下网址:http://210.38.137.126:8016/xscj_gc.aspx?xh=201711672135&xm=%D5%C5%BD%A8%B3%CC&gnmkdm=N121613,网站地址后面跟的是学生的学号和姓名,这里可以封装一下保存到param字典中,也可以直接对这个url发起POST请求。找到该POST请求下浏览器提交的数据:
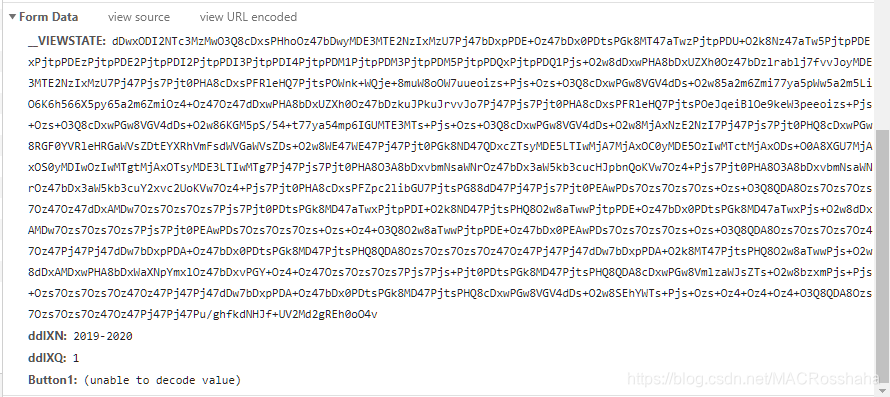
包含年份和学期,采用同样的方法发起一个POST请求:
cj_url = 'http://210.38.137.126:8016/xscj_gc.aspx?xh=201711672135&xm=%D5%C5%BD%A8%B3%CC&gnmkdm=N121613'
data2 ={
'__VIEWSTATE': 'dDwxODI2NTc3MzMwO3Q8cDxsPHhoOz47bDwyMDE3MTE2NzIxMzU7Pj47bDxpPDE+Oz47bDx0PDtsPGk8MT47aTwzPjtpPDU+O2k8Nz47aTw5PjtpPDExPjtpPDEzPjtpPDE2PjtpPDI2PjtpPDI3PjtpPDI4PjtpPDM1PjtpPDM3PjtpPDM5PjtpPDQxPjtpPDQ1Pjs+O2w8dDxwPHA8bDxUZXh0Oz47bDzlrablj7fvvJoyMDE3MTE2NzIxMzU7Pj47Pjs7Pjt0PHA8cDxsPFRleHQ7PjtsPOWnk+WQje+8muW8oOW7uueoizs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w85a2m6Zmi77ya5pWw5a2m5LiO6K6h566X5py65a2m6ZmiOz4+Oz47Oz47dDxwPHA8bDxUZXh0Oz47bDzkuJPkuJrvvJo7Pj47Pjs7Pjt0PHA8cDxsPFRleHQ7PjtsPOeJqeiBlOe9keW3peeoizs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w86KGM5pS/54+t77ya54mp6IGUMTE3MTs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w8MjAxNzE2NzI7Pj47Pjs7Pjt0PHQ8cDxwPGw8RGF0YVRleHRGaWVsZDtEYXRhVmFsdWVGaWVsZDs+O2w8WE47WE47Pj47Pjt0PGk8ND47QDxcZTsyMDE5LTIwMjA7MjAxOC0yMDE5OzIwMTctMjAxODs+O0A8XGU7MjAxOS0yMDIwOzIwMTgtMjAxOTsyMDE3LTIwMTg7Pj47Pjs7Pjt0PHA8O3A8bDxvbmNsaWNrOz47bDx3aW5kb3cucHJpbnQoKVw7Oz4+Pjs7Pjt0PHA8O3A8bDxvbmNsaWNrOz47bDx3aW5kb3cuY2xvc2UoKVw7Oz4+Pjs7Pjt0PHA8cDxsPFZpc2libGU7PjtsPG88dD47Pj47Pjs7Pjt0PEAwPDs7Ozs7Ozs7Ozs+Ozs+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47dDxAMDw7Ozs7Ozs7Ozs7Pjs7Pjt0PDtsPGk8MD47aTwxPjtpPDI+O2k8ND47PjtsPHQ8O2w8aTwwPjtpPDE+Oz47bDx0PDtsPGk8MD47aTwxPjs+O2w8dDxAMDw7Ozs7Ozs7Ozs7Pjs7Pjt0PEAwPDs7Ozs7Ozs7Ozs+Ozs+Oz4+O3Q8O2w8aTwwPjtpPDE+Oz47bDx0PEAwPDs7Ozs7Ozs7Ozs+Ozs+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+Oz47bDx0PDtsPGk8MD47PjtsPHQ8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+O2k8MT47PjtsPHQ8O2w8aTwwPjs+O2w8dDxAMDxwPHA8bDxWaXNpYmxlOz47bDxvPGY+Oz4+Oz47Ozs7Ozs7Ozs7Pjs7Pjs+Pjt0PDtsPGk8MD47PjtsPHQ8QDA8cDxwPGw8VmlzaWJsZTs+O2w8bzxmPjs+Pjs+Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+Oz47bDx0PDtsPGk8MD47PjtsPHQ8cDxwPGw8VGV4dDs+O2w8SEhYWTs+Pjs+Ozs+Oz4+Oz4+Oz4+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47Pu/ghfkdNHJf+UV2Md2gREh0oO4v',
'ddlXN': '2019-2020',
'ddlXQ': '1',
'Button1': '(unable to decode value)',
}
# param = {
# 'xh': '201711672135',
# 'xm': '(unable to decode value)',
# 'gnmkdm': 'N121613',
# }
response1 = session.post(url=cj_url,headers=headers,data=data2)
print(response1.status_code)
cj_page_text = response1.text
with open('cj.html','w',encoding='utf-8') as fp:
fp.write(cj_page_text)
运行代码,发现页面显示错误。打印一下status_code,显示为302,保存为html文件,打开发现网页出现重定向问题:
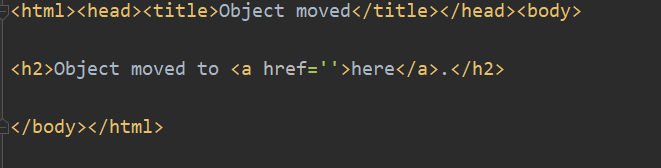
上网查询了一下发现问题是浏览器不知道要跳转到哪里,所以浏览器就显示了这几个字母。正方的每次post请求除了需要cookie ivewStatus 还需要Referer,加上网站的Referer就可以正常爬取信息了。
原文链接:正方教务系统模拟登陆查询课表出现302跳转解决Object moved to here.
修改一下代码:
headers2 ={
'Referer': 'http://210.38.137.126:8016/xs_main.aspx?xh=201711672135',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
运行代码,status_code显示200,说明成功请求到成绩页面。
数据解析:
获取到页面信息后最后一步就是解析数据了。数据解析分类:正则, bs4,xpath(通用性强)。这里我采用的是bs4和正则。附上代码:
soup = BeautifulSoup(cj_page_text,'lxml')
tr_list = soup.select('.datelist > tr')
fp = open('成绩单.txt','w',encoding='utf-8')
ex = '<td>(.*?)</td>'
list = []
count = 0 #记录数量,便于换行
for tr in tr_list:
tr = str(tr)
list = re.findall(ex,tr,re.S)
for li in list:
count = count+1
li =li.strip()
if count%16 ==0:
fp.write(li+'\n')
else:
fp.write(li+' ')
if tr_list:
os.startfile(r'成绩单.txt')
else:
print("验证码识别错误!")
运行代码,成绩单打印成功!

还可以将py文件封装为exe可执行文件,这样以后就可以直接运行。
相关链接:Python 将.py转换为.exe详解
总结:
第一次写博客,一些专业的术语可能描述得不正确,大佬们请别较真哈
,主要是想记录一下整个过程,同时也供有需要的同学借鉴和参考,有什么问题欢迎交流探讨。
最后附上完整代码:
import os
import re
from lxml import etree
from CodeClass import YDMHttp
from bs4 import BeautifulSoup
import requests
def getCodeText(imgPath,codeType): #获取验证码
username = '****'
password = '****'
appid = 10085
appkey = '343fbf24012c556c64cebce0c1643127'
filename = imgPath
#http://www.yundama.com/price.html
codetype = codeType
timeout = 15
result = None
# 检查
if (username == 'username'):
print('请设置好相关参数再测试')
else:
# 初始化
yundama = YDMHttp(username, password, appid, appkey)
uid = yundama.login();
print('uid: %s' % uid)
balance = yundama.balance();
print('balance: %s' % balance)
# 开始识别,图片路径,验证码类型ID,超时时间(秒),识别结果
cid, result = yundama.decode(filename, codetype, timeout);
#print('cid: %s, result: %s' % (cid, result))
return result
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'
}
session = requests.Session()
url = "http://210.38.137.126:8016/"
page_text = session.get(url =url,headers=headers).text
tree = etree.HTML(page_text)
code_img_src = 'http://210.38.137.126:8016/' + tree.xpath('//*[@id="icode"]/@src')[0]
img_data = session.get(url =code_img_src,headers=headers).content
with open('./code.jpg','wb') as fp:
fp.write(img_data)
code_text = getCodeText('code.jpg',1004)
print('验证码识别结果:',code_text)
login_url = 'http://210.38.137.126:8016/default2.aspx'
data = {
'__VIEWSTATE': 'dDwxNTMxMDk5Mzc0Ozs+OBE730NQqeUlEYO76T3Qls4CiUo=',
'txtUserName': '201711672135',
'Textbox1':'',
'TextBox2': '********',
'txtSecretCode': code_text,
'RadioButtonList1': '(unable to decode value)',
'Button1': '',
'lbLanguage': '',
'hidPdrs':'',
'hidsc':'',
}
response = session.post(url=login_url,headers=headers,data=data)
print(response.status_code)
login_page_text = response.text
cj_url = 'http://210.38.137.126:8016/xscj_gc.aspx?xh=201711672135&xm=%D5%C5%BD%A8%B3%CC&gnmkdm=N121613'
headers2 ={
'Referer': 'http://210.38.137.126:8016/xs_main.aspx?xh=201711672135',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
data2 ={
'__VIEWSTATE': 'dDwxODI2NTc3MzMwO3Q8cDxsPHhoOz47bDwyMDE3MTE2NzIxMzU7Pj47bDxpPDE+Oz47bDx0PDtsPGk8MT47aTwzPjtpPDU+O2k8Nz47aTw5PjtpPDExPjtpPDEzPjtpPDE2PjtpPDI2PjtpPDI3PjtpPDI4PjtpPDM1PjtpPDM3PjtpPDM5PjtpPDQxPjtpPDQ1Pjs+O2w8dDxwPHA8bDxUZXh0Oz47bDzlrablj7fvvJoyMDE3MTE2NzIxMzU7Pj47Pjs7Pjt0PHA8cDxsPFRleHQ7PjtsPOWnk+WQje+8muW8oOW7uueoizs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w85a2m6Zmi77ya5pWw5a2m5LiO6K6h566X5py65a2m6ZmiOz4+Oz47Oz47dDxwPHA8bDxUZXh0Oz47bDzkuJPkuJrvvJo7Pj47Pjs7Pjt0PHA8cDxsPFRleHQ7PjtsPOeJqeiBlOe9keW3peeoizs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w86KGM5pS/54+t77ya54mp6IGUMTE3MTs+Pjs+Ozs+O3Q8cDxwPGw8VGV4dDs+O2w8MjAxNzE2NzI7Pj47Pjs7Pjt0PHQ8cDxwPGw8RGF0YVRleHRGaWVsZDtEYXRhVmFsdWVGaWVsZDs+O2w8WE47WE47Pj47Pjt0PGk8ND47QDxcZTsyMDE5LTIwMjA7MjAxOC0yMDE5OzIwMTctMjAxODs+O0A8XGU7MjAxOS0yMDIwOzIwMTgtMjAxOTsyMDE3LTIwMTg7Pj47Pjs7Pjt0PHA8O3A8bDxvbmNsaWNrOz47bDx3aW5kb3cucHJpbnQoKVw7Oz4+Pjs7Pjt0PHA8O3A8bDxvbmNsaWNrOz47bDx3aW5kb3cuY2xvc2UoKVw7Oz4+Pjs7Pjt0PHA8cDxsPFZpc2libGU7PjtsPG88dD47Pj47Pjs7Pjt0PEAwPDs7Ozs7Ozs7Ozs+Ozs+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47dDxAMDw7Ozs7Ozs7Ozs7Pjs7Pjt0PDtsPGk8MD47aTwxPjtpPDI+O2k8ND47PjtsPHQ8O2w8aTwwPjtpPDE+Oz47bDx0PDtsPGk8MD47aTwxPjs+O2w8dDxAMDw7Ozs7Ozs7Ozs7Pjs7Pjt0PEAwPDs7Ozs7Ozs7Ozs+Ozs+Oz4+O3Q8O2w8aTwwPjtpPDE+Oz47bDx0PEAwPDs7Ozs7Ozs7Ozs+Ozs+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+Oz47bDx0PDtsPGk8MD47PjtsPHQ8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+O2k8MT47PjtsPHQ8O2w8aTwwPjs+O2w8dDxAMDxwPHA8bDxWaXNpYmxlOz47bDxvPGY+Oz4+Oz47Ozs7Ozs7Ozs7Pjs7Pjs+Pjt0PDtsPGk8MD47PjtsPHQ8QDA8cDxwPGw8VmlzaWJsZTs+O2w8bzxmPjs+Pjs+Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47dDw7bDxpPDA+Oz47bDx0PDtsPGk8MD47PjtsPHQ8cDxwPGw8VGV4dDs+O2w8SEhYWTs+Pjs+Ozs+Oz4+Oz4+Oz4+O3Q8QDA8Ozs7Ozs7Ozs7Oz47Oz47Pj47Pj47Pu/ghfkdNHJf+UV2Md2gREh0oO4v',
'ddlXN': '2019-2020',
'ddlXQ': '1',
'Button1': '(unable to decode value)',
}
response1 = session.post(url=cj_url,headers=headers2,data=data2)
# print(response1.status_code)
cj_page_text = response1.text
with open('cj.html','w',encoding='utf-8') as fp:
fp.write(cj_page_text)
#数据解析:
soup = BeautifulSoup(cj_page_text,'lxml')
tr_list = soup.select('.datelist > tr')
fp = open('成绩单.txt','w',encoding='utf-8')
ex = '<td>(.*?)</td>'
list = []
count = 0
for tr in tr_list:
tr = str(tr)
list = re.findall(ex,tr,re.S)
for li in list:
count = count+1
li =li.strip()
if count%16 ==0:
fp.write(li+'\n')
else:
fp.write(li+' ')
if tr_list:
os.startfile(r'成绩单.txt')
else:
print("验证码识别错误!")